
本教程写作时游戏版本:1.16.201

序言
这篇专栏其实我上个学期就打算写的,但是由于缺乏相应的代码支持(就是有一个部分的代码自己始终写不出来),并且自己还不太善于表达,于是就搁置了,所以要向一直期待这个专栏的粉丝表示非常抱歉。
我在自己的测试特效红石音乐的封面图上发表了自己是如何制作那一期视频的。细心的观众肯定也留意到,许多有放了方块的区块都没有自然生成的超平坦地形。这是因为我是直接用的自己写的编辑存档的工具吖~ 所以那个视频虽然可能连特效都算不上,但是还是有许多内涵的(无深意)
本来打算将这个做成ppt动画然后发视频的,然后就发现自己的时间根本不够。(上一年投稿的“用mc还原横竖撇点折字谜”的视频也是在有网课基础的情况下才得以有时间的(说出真相),所以这个专栏更多的是去教大家怎么搜集资料,教大家理解代码,补充上网上几乎找不到的,并与大家广泛交流。
参考资料:
Minecraft维基【中文版和英文版】,
国外大佬编写的与读取存档有关的库【https://github.com/mjungnickel18/papyruscs】
存档整体架构
基岩版的存档可以分为两个部分,一个部分存储的是世界的全局信息,一个部分是区块单独信息。世界的全局信息包括材质包,行为包,时间,游戏模式等不论在哪个区块永恒不变的游戏设定【包括《赤壁赋》中的月亮(指时间)】;区块单独信息包括某个位置的方块属性,末地的折跃门的方位,以及主世界的某个村庄信息。
世界的全局信息就是存档中除了db文件夹其它的所有文件,区块单独信息就是db文件夹。
值得注意的是,有一小部分的生物事件的启用等信息也放在db文件夹里面了。这个将会在下面涉及到。
世界全局信息
level.dat
这个文件是以未经压缩的小端序的NBT格式存储的。里面记录的绝大部分在存档设置中能看到的选项。许多的参数根据其英文的命名可以直接猜出来,还有些少部分大家试一下应该就清楚了。这个文件网上应该教程很广泛。【如果实在找不到或许可以参考一下Minecraft java版本的同名参数】
level.dat_old是其备份的文件。如果存档哪一天突然在世界列表里面找不到了,就可以将原来的level.dat文件删掉然后将这个文件改为level.dat。【多半找不到的原因就是level.dat文件损坏了】
注:这个文件里面的LevelName参数就是在世界列表中显示的世界名称。改变ta,则显示的世界名称也会跟着修改,同时levelname.txt也随着修改。
world_icon.jpeg
世界图标,大小为400 * 225。
world_***_packs.json
这个记录了世界正在使用的资源包信息。
world_***_packs_history.json
这个记录了世界曾经使用的所有资源包的信息。
这个文件里面有一个can_be_redownloaded参数。当这个参数为true时,那么这个资源包就是商店里面有的资源包。在Windows 10上面能够找到下载的缓存,位于“C:\Users\用户名\AppData\Local\Packages\Microsoft.MinecraftUWP_8wekyb3d8bbwe\LocalState\premium_cache\”,但是里面的文件几乎全部都被加密了。
还有两个文件夹:***_packs
大家肯定都懂,我就不说辽~
区块单独信息
这部分的信息全部都存储在db文件夹里面。里面的所有文件和目录都构成一个levelDB数据库,并且还以zlib压缩。
简单解释一下levelDB。如果大家了解过java,那么levelDB就可以描述成Map<byte[], byte[]>;就是每有一个byte数组,就有一个byte数组与其对应(当然如果数据库里面没有对应的,那就会是null了)。下文中提到的某个文本“传入数据库”,就是这个文本对应的byte数组传入数据库内。
这个部分可以使用mcc tool chest pe来直观的查看。

MCC Tool Chest PE
在MCC Tool Chest PE打开世界后,data和players文件夹里面的所有项的名字都可以直接传入LevelDB并得到相应的信息。相信大家根据名字就可以猜出对应的信息。【这个部分我没有仔细研究】
区块存储
这一个部分网上的资料几乎很少,所以就尽量详细一点。
第一步,我们需要构造一个传入的byte数组来申请数据。
这一个部分非常简单。传入的byte数组的前四项以小端序放上int类型的区块x坐标,然后放上小端序存储的int类型的区块z坐标。接下来,如果是主世界(维度id为0),可以跳过这一步;如果不是主世界,那么放上小端序的int类型的区块维度id。接下来传入一个字节,这个字节可以有如下情况,分别可以得到不同的区块信息:(有些不清楚的就省略了)
45 高度图和生物群系
47 子区块的数据
49 方块实体数据
50 实体数据
118 该区块格式版本号
尝试申请子区块的数据的时候,传入的byte数组的最后还要加一个字节,代表这个子区块从下往上数是第几个(要从0开始数哦)。
第二步,就是解析返回的byte数组。
高度图和生物群系
Generally,返回的都是768个字节。前512个字节是高度图,每个高度占两个字节(也就是short类型)。紧接着256个字节是生物群系,每个生物群系对应id以byte类型存储。
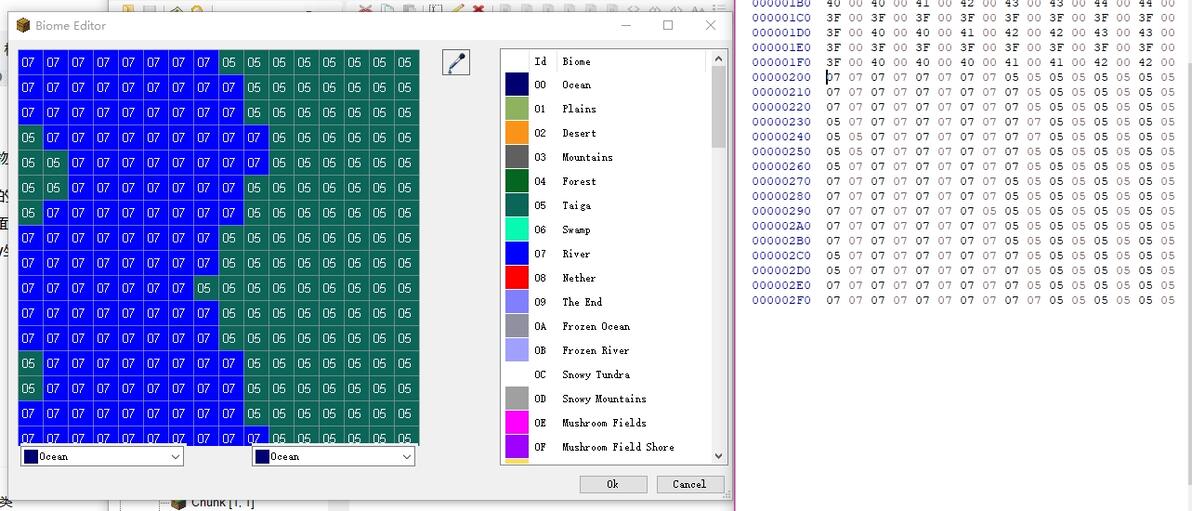
左图:mcc tool chest生物群系截图,横着是x轴,竖着是y轴。右图:数据库返回的原始数据在16进制编辑器中的模样
方块实体数据
返回的方块实体数据是一个nbt数据接一个nbt数据的。这个nbt数据有该方块实体数据对应的方块坐标x,y,z;还有id,即方块实体数据的类型;还有一个叫"isMovable"的布尔值,代表该方块能否被活塞推动。剩下的就是每个方块实体的单独特有的信息了。
这里就不介绍每个不同类型方块有哪些数据了。minecraft维基上记载了哪些方块具有方块实体数据。大家可以先将有方块实体数据的方块放置,然后通过mcc tool chest或者直接用代码查看一下有哪些参数。
子区块的数据
mc不是整个存储一个区块的。她()将区块划分成8个16x16x16个从下到上堆积的子区块,分别存储。并且不仅是levelDB有自己的压缩算法,子区块的存储也有自己专门的压缩算法。这就听我娓娓道来()。
首先我们就需要了解几个东西,这些东西在下面就会用到。
第一个就是分区:众所周知,游戏中有一个东西叫做含水方块,一个含水方块在基岩版严格来说就是一格具有两个方块,所以游戏将这两个方块放在不同分区对应的方块中,这就是分区的用途。
第二个就是有效字节。许多比较小的数的存储不会将所有字节都用上,比如说十进制的数字192837465,以long类型存储到磁盘中就会是:“”,于是我们发现,真正有意义的有且仅有28个bit:“1011 0111 1110 0111 0111 0101 1001”,其ta的字节都是0,可以理解为无意义,所以就说这个数的有效字节只有28位。
获取到的byte数组,首先的第一个字节就是该格式的版本号,在目前的版本是8;第二个字节代表有多少个分区。从第三个字节开始,就开始存储分区。每个分区由索引区和数据区组成。数据区存储了许多方块NBT,在这里,每个方块NBT按照顺序被标上号,即代表的索引id。索引区按照顺序存储了一连串id,这些id根据索引对应了方块NBT。
索引区使用了一种压缩算法。我们可以将这个情景剥离出来,就是:现在有16*16*16=4096个数,该怎么存储能够尽量占用字节少。mc给出了一个solution:索引区的第一个字节除以2得到的数代表要存储的数占用的最大有效字节是多少。接下来的我实在不会表达辽,直接上代码:
【这一个部分的代码来自https://github.com/LovelyZeeiam/BedrockEditor/blob/master/src/main/java/xueli/bedrockeditor/LevelDatabase.java中的processIn方法】
ByteBuffer in = 索引区的输入流;
//每个方块索引最大占据几个字节
byte bitsPerBlock = in.read();
// 索引区的第二个字节开始存储索引正文,每几个索引在一起以int类型的形式存储
// 每个int类型中可以存储多少个方块
int blocksPerWord = (int) Math.floor(sizeof(int) / bitsPerBlock);
// 一共有多少个int类型
int wordCount = (int) Math.ceil((16 * 16 * 16) / blocksPerWord);
// 当前指针指向的方块的位置
int position = 0;
// 方块索引
int[][][] indices = new int[16][16][16];
for (int wi = 0; wi < wordCount; wi++) {
int word = in.getInt();
for (int block = 0; block < blocksPerWord; block++) {
int state = (word >> ((position % blocksPerWord) * bitsPerBlock)) & ((1 << bitsPerBlock) - 1);
int x = (position >> 8) & 0xF;
int y = position & 0xF;
int z = (position >> 4) & 0xF;
indices[x][y][z] = state;
position++;
}
}
// 这里就是数据区了
ArrayList tags = new ArrayList<>();
// 数据区的前四个字节代表数据区存储了多少方块NBT数据
int paletteSize = in.getInt();
for (int palletId = 0; palletId < paletteSize; palletId++) {
// ByteBufferInputStream类是我自己写的一个类,就是将ByteBuffer变成一个Inputstream
// NBTInputStream的构造方法的第二个参数代表该NBT数据是没有gzip压缩的
NBTInputStream nbtin = new NBTInputStream(new ByteBufferInputStream(in), false, ByteOrder.LITTLE_ENDIAN);
CompoundTag tag = (CompoundTag) nbtin.readTag();
tags.add(tag);
nbtin.close();
}
// 最后就将indices和tags对应,放到storage列表里面就可以
storages.add(new Storage(indices, tags));
每种方块对应的方块NBT里面有三个参数:一个叫name,String类型,代表方块的命名空间;还有一个叫version,int类型,在这个游戏版本都是17825808;第三个是一个CompoundTag,名字叫states。这个CompoundTag里面代表的所有参数可以在英文版维基对应方块的"Block states"中的"Bedrock Edition"找到。至于参数的类型,可以参照查找方块实体数据的方法来查找参数的类型。
结构
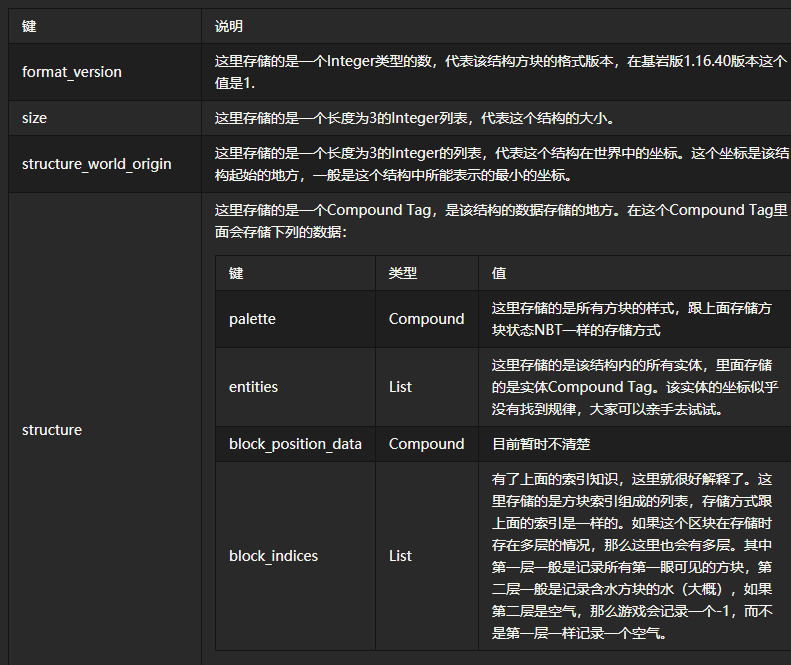
最后我们要提及的就是结构。获取结构很简单,将"structuretemplate_"放在游戏中保存的结构名称之前就可以找到了,获得到的是一个nbt数据,这个nbt数据中会有这些参数:

最后
up已经临近高三了,忙活技术类东西的时间已经很少了,估计不会再出一些技术力很大的视频或者专栏了。我在mc里面其实并未创建出什么成就,我不会pvp和建造,也不会玩出令人羡慕的生存存档。如果这篇文章对宁的mc旅途有帮助,还请不忘点个赞;如果觉得文章有不足之处,还请不忘在评论区里面指出来。
提前给大家祝贺元宵节快乐~
