


本章导航地图:

1.什么是编程范式?
编程范式:Programming Paradigm。即模范的意思,范式即方式、方法,是一种典型的编程风格。说白了就是指从事软件工程的一种方法论。
C语言
C 语言诞生于 1972 年,到现在已经有 45 年的历史,在它之后,C++、Java、C# 等语言前仆后继,一浪高过一浪,都在试图解决那个时代的那个特定问题。我们不能去否定某个语言,但可以确定的是,随着历史的发展,每一门语言都还在默默迭代,不断优化和更新。同时,也会有很多新的编程语言带着新的闪光耀眼的特性出现在我们面前。
C语言有哪些特性呢?
1.C 语言是一个静态弱类型语言,在使用变量时需要声明变量类型,但是类型间可以有隐式转换;
2.不同的变量类型可以用结构体(struct)组合在一起,以此来声明新的数据类型;
3.C 语言可以用 typedef 关键字来定义类型的别名,以此来达到变量类型的抽象;
4.C 语言是一个有结构化程序设计、具有变量作用域以及递归功能的过程式语言;
5.C 语言传递参数一般是以值传递,也可以传递指针;
6.通过指针,C 语言可以容易地对内存进行低级控制,然而这加大了编程复杂度;
7.编译预处理让 C 语言的编译更具有弹性,比如跨平台。
C 语言的这些特性,可以让程序员在微观层面写出非常精细和精确的编程操作,让程序员可以在底层和系统细节上非常自由、灵活和精准地控制代码。
2.泛型编程

泛型编程来源于C语言中对于各种数据类型的适配问题,对类型的抽象,这就是所谓的泛型编程。

2.1 C语言泛型的实现
1.使用void *关键字 函数接口中增加了一个size参数 函数的实现中使用了memcpy()函数 函数的实现中使用了一个temp[size]数组 2.使用宏定义
2.2 C++解决了C语言中的哪些问题和不便?
1.用引用来解决指针的问题。 2.用 namespace 来解决名字空间冲突的问题。 3.通过 try-catch 来解决检查返回值编程的问题。 4.用 class 来解决对象的创建、复制、销毁的问题,从而可以达到在结构体嵌套时可以深度复制的内存安全问题。 5.通过重载操作符来达到操作上的泛型。 6.通过模板 template 和虚函数的多态以及运行时识别来达到更高层次的泛型和多态。 7.用 RAII、智能指针的方式,解决了 C 语言中因为需要释放资源而出现的那些非常 ugly 也很容易出错的代码的问题。 8.用 STL 解决了 C 语言中算法和数据结构的 N 多种坑。
2.3 C++的泛型如何实现?
1.通过类的方式来解决 类里面会有构造函数、析构函数表示这个类的分配和释放 还有它的拷贝构造函数,表示了对内存的复制 还有重载操作符,像我们要去比较大于、等于、不等于 2.通过模板达到类型和算法的妥协 模板有点像 DSL,模板的特化会根据使用者的类型在编译时期生成那个模板的代码 模板可以通过一个虚拟类型来做类型绑定,这样不会导致类型转换时的问题 3.通过虚函数和运行时类型识别 虚函数带来的多态在语义上可以支持“同一类”的类型泛型 运行时类型识别技术可以做到在泛型时对具体类型的特殊处理。
2.4类型系统
编程世界中的类型系统主要有两种:内建类型和抽象类型。
内建类型,如 int、float 和 char 等;抽象类型,如 struct、class 和 function 等。
在编程世界中建立类型系统有什么作用呢?
程序语言的安全性 利于编译器的优化 代码的可读性 抽象化
基于类型系统就衍生除了两类语言,静态类型语言和动态类型语言。所谓静态类型语言,就是有严格的类型声明,类型在声明出来后就不能随意改变了,如C、C++、Java;所谓的动态类型语言就是没有严格的类型声明,类型可以随意改变,如 Python、PHP、JavaScript 等。
类型的本质:
1.类型是对内存的一种抽象 不同的类型,会有不同的内存布局和内存分配的策略 2.不同的类型,有不同的操作 对于特定的类型,也有特定的一组操作
2.5泛型的本质
标准化掉类型的内存分配、释放和访问 标准化掉类型的操作。比如:比较操作,I/O 操作,复制操作…… 标准化掉数据容器的操作。比如:查找算法、过滤算法、聚合算法…… 标准化掉类型上特有的操作。需要有标准化的接口来回调不同类型的具体操作……
那么泛型的本质就是屏蔽掉数据和操作数据的细节,让算法更为通用,让编程者更多的关注算法的结构,而不是在算法中处理不同的数据类型。
3.函数式编程
函数式编程是个非常古老的概念,它的核心思想是将运算过程尽量写成一系列嵌套的函数调用,关注的是做什么而不是怎么做,因而被称为声明式编程。
以 Stateless(无状态)和 Immutable(不可变)为主要特点,代码简洁,易于理解,能便于进行并行执行,易于做代码重构,函数执行没有顺序上的问题,支持惰性求值,具有函数的确定性——无论在什么场景下都会得到同样的结果。

3.1什么叫函数式编程?
定义输入数据和输出数据相关的关系,数学表达式里面其实是在做一种映射(mapping),输入的数据和输出的数据关系是什么样的,是用函数来定义的。
3.2函数式编程的特征
stateless:函数不维护任何状态。函数式编程的核心精神是 stateless,简而言之就是它不能存在状态,打个比方,你给我数据我处理完扔出来。里面的数据是不变的。
immutable:输入数据是不能动的,动了输入数据就有危险,所以要返回新的数据集。
3.3优势
没有状态就没有伤害。
并行执行无伤害。
Copy-Paste 重构代码无伤害。
函数的执行没有顺序上的问题。
3.4好处
惰性求值
表达式在绑定的时候是不会没有求值的,只有在显示调用的时候才会真正求值
确定性
对于结果是确定的,不过在何种场景下
3.5劣势
数据复制比较严重。
3.6各语言对函数式编程的支持程度
完全纯函数式 Haskell
容易写纯函数 F#, Ocaml, Clojure, Scala
纯函数需要花点精力 C#, Java, JavaScript
3.7函数式编程用到的技术
first class function(头等函数)
这个技术可以让你的函数就像变量一样来使用。也就是说,你的函数可以像变量一样被创建、修改,并当成变量一样传递、返回,或是在函数中嵌套函数。
tail recursion optimization(尾递归优化)
我们知道递归的害处,那就是如果递归很深的话,stack 受不了,并会导致性能大幅度下降。因此,我们使用尾递归优化技术——每次递归时都会重用 stack,这样能够提升性能。当然,这需要语言或编译器的支持。Python 就不支持。
map & reduce
函数式编程最常见的技术就是对一个集合做 Map 和 Reduce 操作。这比起过程式的语言来说,在代码上要更容易阅读。
pipeline(管道)
这个技术的意思是,将函数实例成一个一个的 action,然后将一组 action 放到一个数组或是列表中,再把数据传给这个 action list,数据就像一个 pipeline 一样顺序地被各个函数所操作,最终得到我们想要的结果
recursing(递归)
递归最大的好处就简化代码,它可以把一个复杂的问题用很简单的代码描述出来。
currying(柯里化)
将一个函数的多个参数分解成多个函数, 然后将函数多层封装起来,每层函数都返回一个函数去接收下一个参数,这可以简化函数的多个参数。
higher order function(高阶函数)
所谓高阶函数就是函数当参数,把传入的函数做一个封装,然后返回这个封装函数。
3.8修饰器模式
l 修饰器模式就是扩展现有的一个函数的功能,让它可以干一些其他的事,或是在现有的函数功能上再附加上一些别的功能。
l Decorator 这个函数其实是可以修饰几乎所有的函数的。于是,这种可以通用于其它函数的编程方式,可以很容易地将一些非业务功能的、属于控制类型的代码给抽象出来(所谓的控制类型的代码就是像 for-loop,或是打日志,或是函数路由,或是求函数运行时间之类的非业务功能性的代码)。
4.面向对象编程

面向对象编程是我们Java程序员最熟悉不过的了,关于对面向对象的讲解大家可以看看我之前发的视频,里面有很详细的讲解,这里就不再重复了。

4.1面向对象编程范式的定义
面向对象编程是一种具有对象概念的程序编程范型,同时也是一种程序开发的抽象方针,它可能包含数据、属性、代码与方法。
它将对象作为程序的基本单元,将程序和数据封装其中,以提高软件的可重用性、灵活性和可扩展性,对象里的程序可以访问及修改对象相关联的数据。在面向对象编程里,计算机程序会被设计成彼此相关的对象。
4.2三大特性
封装
继承
多态
4.3优点
l 能和真实的世界交相辉映,符合人的直觉。 l 面向对象和数据库模型设计类型,更多地关注对象间的模型设计。 l 强调于“名词”而不是“动词”,更多地关注对象和对象间的接口。 l 根据业务的特征形成一个个高内聚的对象,有效地分离了抽象和具体实现,增强了可重用性和可扩展性。 l 拥有大量非常优秀的设计原则和设计模式。 l S.O.L.I.D(单一功能、开闭原则、里氏替换、接口隔离以及依赖反转,是面向对象设计的五个基本原则)、IoC/DIP……
4.4缺点
l 代码都需要附着在一个类上,从一侧面上说,其鼓励了类型。 l 代码需要通过对象来达到抽象的效果,导致了相当厚重的“代码粘合层”。 l 因为太多的封装以及对状态的鼓励,导致了大量不透明并在并发下出现很多问题。
4.5基于原型(Prototype)的编程
基于原型(Prototype)的编程其实也是面向对象编程的一种方式。没有 class 化的,直接使用对象。又叫,基于实例的编程。其主流的语言就是 JavaScript。
5.编程本质和逻辑编程

5.1编程的本质
Programs = Algorithms + Data Structures(编程=算法+数据结构)
Algorithm = Logic + Control(算法=逻辑+控制)
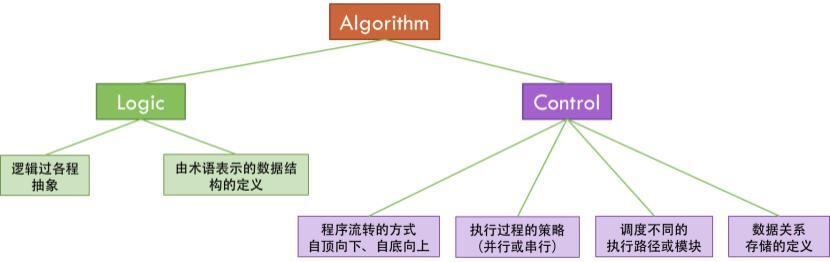
根据上面两条公式我们可以得出最终的公式:
Program = Logic + Control + Data Structure
编程范式的本质就是:有效地分离 Logic、Control 和 Data 是写出好程序的关键所在!
l Control 是可以标准化的。比如:遍历数据、查找数据、多线程、并发、异步等,都是可以标准化的 l Control 需要处理数据,所以标准化 Control,需要标准化 Data Structure,我们可以通过泛型编程来解决这个事。 l Control 还要处理用户的业务逻辑,即 Logic。所以,我们可以通过标准化接口 / 协议来实现,我们的 Control 模式可以适配于任何的 Logic。
代码复杂度的原因:
1.业务逻辑的复杂度决定了代码的复杂度;
2.控制逻辑的复杂度 + 业务逻辑的复杂度 ==> 程序代码的混乱不堪;
3.绝大多数程序复杂混乱的根本原因:业务逻辑与控制逻辑的耦合。
如何分离 control 和 logic 呢?我们可以使用下面的这些技术来解耦。
State Machine
状态定义 状态变迁条件 状态的 action
DSL – Domain Specific Language
HTML,SQL,Unix Shell Script,AWK,正则表达式……
编程范式
面向对象:委托、策略、桥接、修饰、IoC/DIP、MVC…… 函数式编程:修饰、管道、拼装 逻辑推导式编程:Prolog
这就是编程的本质:
Logic 部分才是真正有意义的(What)
Control 部分只是影响 Logic 部分的效率(How)
5.2逻辑编程范式
Prolog(Programming in Logic)是一种逻辑编程语言,它创建在逻辑学的理论基础之上,最初被运用于自然语言等研究领域。现在它已被广泛地应用在人工智能的研究中,可以用来建造专家系统、自然语言理解、智能知识库等。
逻辑编程是靠推理
逻辑编程的几个步骤:
1.先定义一个规则:哲学家是人类。 2.然后陈述事实:苏格拉底、亚里士多德、柏拉图都是哲学家。 3.然后,我们问,谁是人类?于是就会输出苏格拉底、亚里士多德、柏拉图。
逻辑编程的特征:
逻辑编程的要点是将正规的逻辑风格带入计算机程序设计之中。 逻辑编程建立了描述一个问题里的世界的逻辑模型。 逻辑编程的目标是对它的模型建立新的陈述。 通过陈述事实——因果关系。 程序自动推导出相关的逻辑。
总结:
Prolog 这种逻辑编程,把业务逻辑或是说算法抽象成只关心规则、事实和问题的推导这样的标准方式,不需要关心程序控制,也不需要关心具体的实现算法。只需要给出可以用于推导的规则和相关的事实,问题就可以被通过逻辑推导来解决掉。
最后用一张图总结我们的编程范式。
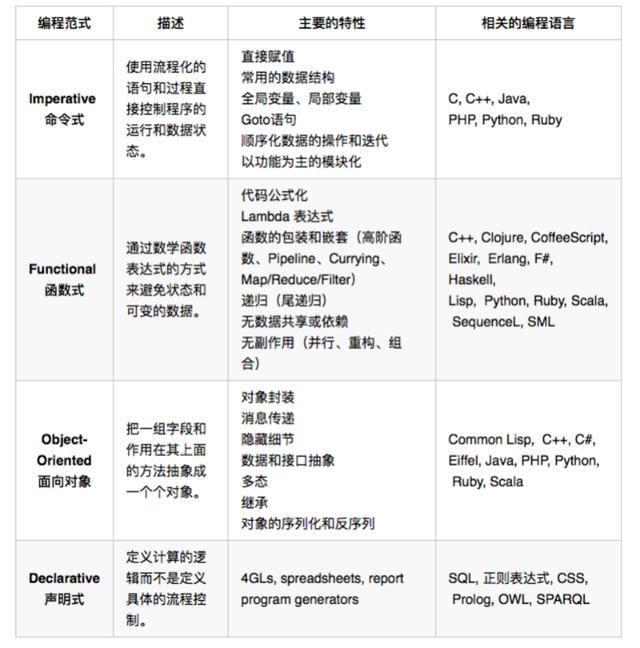
编程范式
