摘要:连续隐状态记忆有望让语言模型在不把每一步都翻译回文本的情况下传递中间状态。本文研究一种具体实现——小型隐式黑板(latent blackboard),将上游上下文压缩为下游模型可读取的隐藏向量。在同架构 2B 混合注意力检查点对上,我们运行受控 Phase-0 诊断套件,发现朴素 retrofit 黑板的约束因素与其说是板槽数量,不如说是读者(reader)的使用激励。精确 token 级隐藏状态重建在 2:1 压缩下即崩溃;gist 式黑板可恢复约 60–70% 的全上下文价值,但恢复率随板槽数几乎平坦,且可能被读者漂移(reader drift)高估。我们引入两项配对诊断指标——board lift 与 LM drift——并表明朴素读者 co-training 主要改善无板读者,而非板的使用。无板锚定(no-board anchoring)干预改变分解结果:board lift 从 0.14–0.16 升至 1.31–1.54 PPL 点,LM drift 从约 1.18 降至 0.20–0.32;log-PPL 空间方向一致。结论既不是隐式记忆失败,也不是系统已解决:retrofit 黑板更像有损笔记,只有目标函数结构上抑制忽略时才会被使用。这些结果指向从零预训练、强制跨段依赖的黑板架构。
引言
现代 Transformer 语言模型通过 token 通信,但内部计算是连续的。能否让一个模型写出紧凑的隐藏向量序列,供另一个模型作为工作记忆读取?成功的话,串行专家系统可以传递隐状态而非冗长文本,并提供区别于 KV cache 的记忆基底——后者记录完整 token 级计算轨迹。
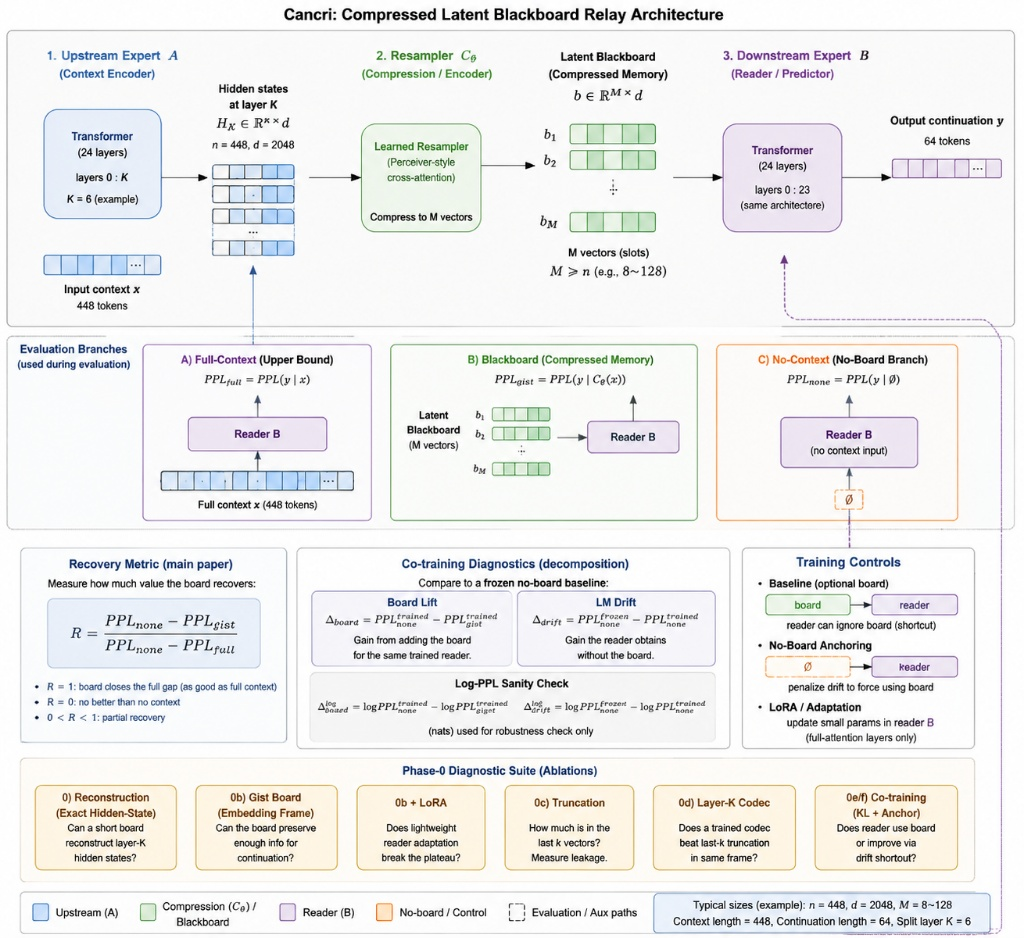
本文在 Cancri 串行 relay 架构中研究该问题的正反两面:上游专家编码上下文;学习 resampler 将隐藏状态压缩为 M 个 board 向量;下游专家从这些 board 向量预测续写。期望的 board 不一定是每个 token 状态的无损重建,而更像连续笔记——保留对下一段有用的信息的紧凑状态。
核心发现是:可选隐式 board 很容易被预训练读者忽略。许多表面增益在与/无 board 的同一训练读者对比时消失——读者可通过普通语言模型适应降低训练损失,而非真正使用 board。加入 no-board anchor 约束这条逃逸路径后,读者才开始使用 board:board lift 约提升一个数量级,恢复价值主要归因于 board 而非 no-board LM drift。
实验设置与诊断指标
Relay 任务:上下文 x(448 token)→ 上游 A 的 layer 0:K 隐藏状态 → resampler C_θ 压缩为 M×d 的 board b → 下游 B 预测续写 y(64 token)。同架构 2B Base/Instruct 检查点对,24 层、hidden 2048、混合注意力(full-attention 层位于 3, 7, 11, 15, 19, 23),分割层 K=6。报告值为 16 个 held-out 窗口的中位数。
三项困惑度:PPL_full = PPL(y|x),PPL_gist = PPL(y|C_θ(x)),PPL_none = PPL(y|∅)。恢复率 R = (PPL_none − PPL_gist) / (PPL_none − PPL_full),R=1 表示 board 闭合无上下文与全上下文之间的测量差距。
读者 co-training 需分解 board lift Δ_board = PPL_trained_none − PPL_trained_gist 与 LM drift Δ_drift = PPL_frozen_none − PPL_trained_none。Board lift 是同一训练读者在加/不加 board 时的配对增益;LM drift 是读者在无 board 条件下获得的增益。
主要结果
1. 无损式隐藏状态压缩迅速崩溃。M=512(1:1)时 student/teacher PPL 比中位数 1.07;M=256(2:1)跳至 2.67;4:1 及以上 PPL 数量级崩溃。紧凑 board 不应被评估为无损 hidden-state 视频编解码器,而应被理解为有损笔记。
2. Gist board 恢复上下文价值但平台化。冻结读者下 M=8(56:1 压缩)R=0.654,M=32(14:1)R=0.658;增大 M 不能可靠提升。LoRA 将 M=32 最佳结果提至 R=0.697,但 M=64 仍为 0.688。瓶颈不在槽位数,而在读者使用 soft board 的能力与激励。原始 last-k 截断曲线陡峭——需约一半原始向量才接近全恢复,说明信息分布在整个上下文而非尾部集中;但训练 layer-K codec 在高压缩下仍优于截断。
3. 协议泄漏可高估恢复率。污染协议(续写表示在 board 插入前已见上下文)下 k=32 时 R=0.757,而 clean 协议仅 0.310;k=64 时分别为 0.926 vs 0.591。决定性比较必须使用 clean continuation encoding。
4. 朴素 co-training 学习 no-board 捷径。Clean KL-to-teacher、M=32:PPL_gist=5.526,PPL_none=5.668,配对 board lift 仅 0.142;LM drift 1.196(相对 frozen no-board PPL 6.864)。log-PPL 空间 board lift 仅 0.025 nats,LM drift 0.192 nats。解冻读者不能打破平台——优化存在简单路径:直接改善续写建模,忽略困难的隐式侧信道。
5. No-board anchoring 强制实际 board 使用。无 anchoring 时 board lift 约 0.15,LM drift 约 1.13–1.20。anchor weight=2 时 board lift 升至 1.31–1.41,drift 降至 0.23–0.32;weight=5 时 M=16 的 board lift 达 1.54,drift 全网格低于 0.30。主导效应是 anchor 权重,而非 M 从 16 变到 64。M=32 分解:KL only 时仅约 11% PPL 改善归因于 board;anchoring 后大部分改善为 board lift。Board 仍非无损——anchored recovery 约 0.57–0.60,远低于全上下文——但失败模式从「读者忽略 board」变为「board 是有损 gist 记忆」。
讨论与下一步
黑板不是 hidden-state 视频编解码器;读者目标比槽位数更重要;retrofit 使 board 对已有强续写先验的读者成为可选项;no-board anchor 移除最直接漂移路径。从零训练应使 board 成为唯一跨段路径——段 t 不应直接看到段 t−1 的 token,只能看到 board_{t−1}。
本文是 Phase-0 诊断,非成品黑板语言模型:单一 2B 模型族、K=6、100MB 子集、16 窗口中位数。最强证据来自 retrofit 中的 anchoring 干预;下一步需多种子、更大 held-out、额外 split layer,以及无需 retrofit anchoring 即可正 board lift 的从零 recurrent-board 原型。
原文见:https://www.nexusvai.xyz/article.html?id=blackboardPhase0