简介
注:该方法用于AMD 2025推理优化挑战赛的赛题解法,源码详见
gitee.com/fanwenjie/reference-kernels
在GPU上实现大矩阵乘法运算,目前主流的方法是将矩阵切块用Block分治计算,而在Block内的运算中,经典方案是采用通过借助共享内存(LDS)缓存从设备内存读取的数据,并在同一个Block内进行复用,从而减少设备内存的IO次数,进而提升计算速度。
本方案将采用一种新型的实现方式,不使用LDS,而是通过提升IO性能,而非减少IO次数,来提升速度。
实现方式
以FP8矩阵乘法为例,在MI300上面,使用v_mfma_f32_32x32x16_fp8_fp8指令,该指令输入2个32x16的矩阵,要求以8字节为单位,将每个矩阵的数据加载到wavefront的64个线程里面。其中A和B矩阵的加载格式如下。
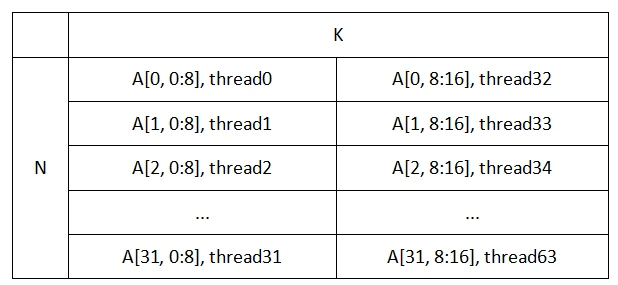
经典方法是直接从设备内存中加载数据,在加载每个输入矩阵的时候需要跨行加载32次。
而本方法是结合矩阵计算指令,让矩阵以一种特殊的排列格式,在内存中进行排布。
为了容易理解,采用输入32x32矩阵,输出也是32x32矩阵的方式表示,即在K方向上通过v_mfma_f32_32x32x16_fp8_fp8指令计算2次,每个矩阵需要在每个thread上,用2个8字节的寄存器进行存储。
因此输入输出矩阵可以用同一种格式进行表示。
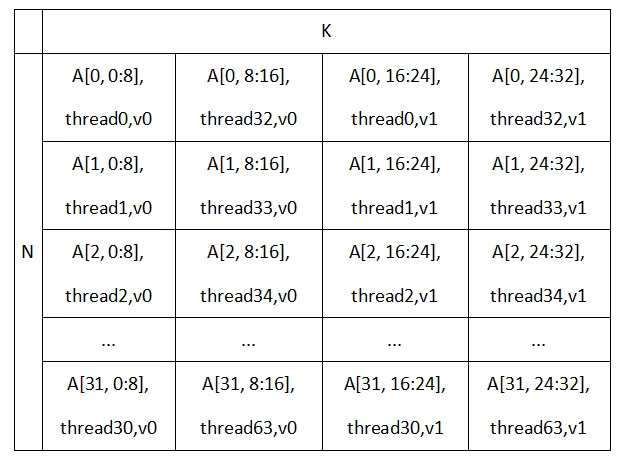
除了FP8,其它格式的浮点也可以用该格式存储,比如针对float16格式的浮点,可在K方向上通过v_mfma_f32_32x32x8f16指令计算4次来实现。对于MFMA指令,左矩阵的km 向量与右矩阵的kn向量的内积存储于目标矩阵的(n, m)位置,需要交换左右参数才能保证同构。
因此,设定一个字节大小为(n/32, k/32, 1024)的3维张量来存储矩阵,
将矩阵的行和列按照32x32的大小进行切分,切分成若干个batch,在每个batch内的数据上按照述表格的方式,通过N方向优先的顺序,写入这个3维张量,则将2维矩阵转化为3维张量。
则三维张量的群计算如下,与矩阵群形成同构,该运算用内置指令实现
其中对应二维矩阵群运算是
二者之间存在如下映射,映射即为内存转换规则
对于二维矩阵运算,IO的算法时间复杂度为O(n³),若进行该映射,可大幅减少算法时间。该映射算法的算法复杂度O(n²), 因此使用该算法,总体算法时间复杂度为O(n²)+O((kn)³),其中k<1。这是该算法的原理。
在内存中最后一个维度的排列如下示例:
A[0, 0:8], A[1, 0:8], ..., A[31, 0:8], A[0, 8:16], A[1, 8:16], ..., A[31, 24:32]
经测试,该方法的IO性能较于经典方法有明显提升。
英伟达CUDA平台实现参考
在nVidia平台上,由于wavefront只有32个线程,且lane的长度为4。这2项参数均为MI300的一半,因此在nVidia平台上,将矩阵按照16x16的大小进行切分。
nVidia平台上的参考实现代码链接如下:
gitee.com/fanwenjie/fast-gemm
可能的原因及思路
每个wavefront内64个线程的计算可看作64个通道的SIMD计算。
这里以CPU上的AVX256指令集进行类比,AVX256在计算单精度浮点时,可看作8个通道的SIMD计算。
如果将若干个浮点加载到YMM寄存器,如果这些浮点在内存中是不连续的,则需要通过gather指令进行加载,比如vgatherdps。但如果是连续的vmovups, 如果不但连续而且地址还按照ymm寄存器长度32字节进行对齐,那么则可以使用vmovaps指令。上述指令在性能方面依次增加。
因此,可以将wavefront内的运算看作“AVX4096”指令集运算,若每个batch内的数据不是连续的,则会在底层使用gather指令。否则不但连续且对齐则使用mov指令。因此将batch内数据按照thread序号连续且512字节对齐,则IO性能会大幅提升。