论文名:Human Video Translation via Query Warping
论文链接:ttps://arxiv.org/pdf/2402.12099.pdf
引言
给定一个人类动作视频,将其动作转移到另一个人以合成新视频在计算机视觉和图形领域引起了很多关注,并取得了很大进展。已有的研究利用生成对抗网络(GANs),将参考动作视频和目标帧作为条件输入。然而,翻译后的视频类似于目标帧,并且无法使用文本进行编辑。最近,文本到图像(T2I)扩散模型在静态图 像合成方面取得了显著进展。给定一个文本提示,可以生成各种风格的生动图像。此外,ControlNet赋 予了T2I模型在文本提示之外的各种条件下的控制能力。
简介
我们提出了QueryWarp,这是一种用于时域连贯的人类运动视频翻译的新型框架。现有基于扩散的视频编辑方法仅依赖于关键和值令牌来确保时间一致性,这种方法会牺牲局部和结构区域的保留。相反,我们旨在通过构建不同帧间查询令牌之间的时间相关性来考虑互补的查询先验。首先,我们从源姿势中提取外观流以捕捉连续的人体前景运动。随后,在扩散模型的去噪过程中,我们利用外观流来扭曲先前帧的查询令牌,将其与当前帧的查询对齐。这种查询扭曲对自注意力层的输出施加了显式约束,从而有效地保证了时间上的一致翻译。我们对各种人体运动视频翻译任务进行了实验,结果表明我们 的QueryWarp框架在质量和量化方面均优于现有方法。
方法与模型
1、Preliminaries
潜在扩散模型(LDMs)
是一种文本到图像模型,它在自动编码器的潜在空间中进行扩散过程。它包括一个自动编码器和一个去噪扩散概率模型(DDPM) 。给定图像x,首先通过自动编码器E编码为潜在代码z, 即z = E(x)。在正向扩散过程中,DDPM会对潜在代码z进行迭代地添加高斯噪声:
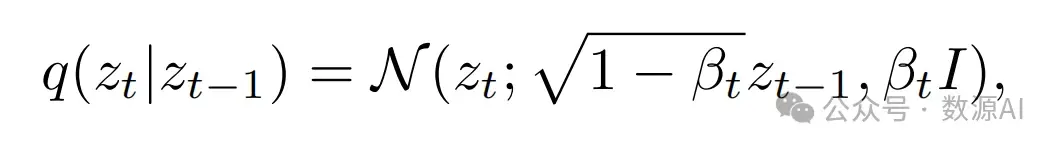
其中q(zt|zt−1)是给定zt−1时zt的条件密度,{βt} T t=0是 噪声的尺度,T是扩散过程的总时间步长。
反向去噪过程表示为:
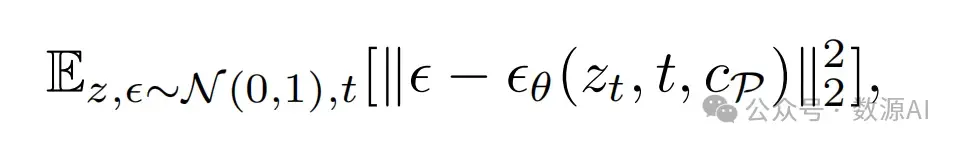
在这里,cP是文本提示。
DDIM抽样和反演
在推断过程中,采用确定性DDIM抽样,逐步将随机高斯噪声zT转换为干净的潜在编码z0,具体如下方程所示:
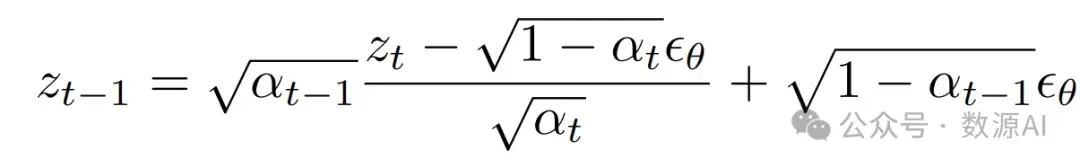
其中t是去噪步骤t : T → 1,αt是噪声调度的参数 。为了重建真实图像并进行编辑[12, 25],DDIM反演被用来将真实图像的潜在编码z0编码为相关的反演噪声,通过在逆向步骤t : 1 → T中反转上述过程。
ControlNet是一种条件文本到图像生成模型,能 够处理各种条件cF,例如,深度图、姿势、边缘。通 过构建噪声预测网络 ϵθ(zt, t, cP , cF ),ControlNet 为条件输入cF添加了一个可训练的副本编码模型。然后,它利用与提示输入cP连接的零卷积进行特定任务 的条件图像生成。
2、Procedure
给定一个包含 N 帧的源人类行为视频 V = {vi | i ∈ [1, N]},我们的目标是在与目标提示 P ∗ 对齐的姿 势条件 C = {ci | i ∈ [1, N]} 下,将其转换为目标时 间连贯视频 V ∗,同时保留源视频的顺序人类行为。与 现有工作不同,我们的翻译视频外观由给定的目标提示 P ∗ 和姿势指导 C 控制。我们的 QueryWarp 管道如图 3.1 的左侧所示,基于 Stable Diffusion 和 ControlNet 构建了该框架。我们首先遵循 Tune-AVideo,膨胀 T2I 模型中的 2D U-Net为伪 3D U-Net,然后通过将外观流重新编程为流引导的注意 力,以保持翻译视频的时间一致性。

3、Self-Attention Mechanism
在介绍我们的方法之前,我们首先希望介绍原始T2I模型的注意力机制。具体来说,给定帧i的潜在表示zi,原始的自注意力机制首先将其投影到“查询”(Qi)、键(Ki)和值(Vi)标记上。然后自注意 力机制表示为:
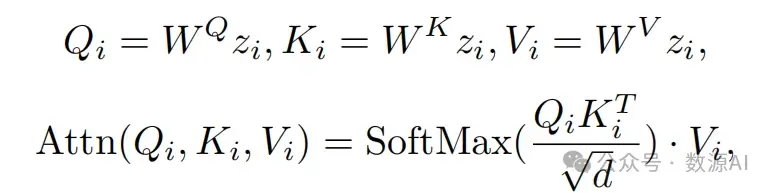
其 中WQ, W K和WV 将zi投影到query、 key和value, d是key和query标记的输出维度。自注意机制处理每帧的内容,但无法保证帧间的时间一致性。为了消除内容不一致性, 现有基 于T2I的视频编辑作品[37, 42]选择一个关键帧,并将 其内容传播到其他帧。特别地,它们使用锚定帧的 标记替换不同帧的key和value标记,即通过共享的锚定key和value标记扩展自注意力到跨帧注意力。具体地,在第i帧上,跨帧注意力可以表示为:
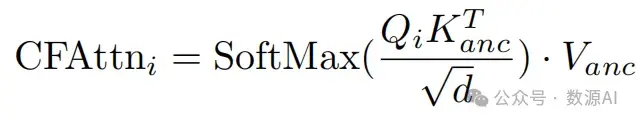
其中,Kanc 和 Vanc 分别表示选择的锚点键和值标记。然而,由于查询标记 Qi 采用自当前帧,不同帧的查询标记之间并没有明确的约束,因此无法消除时间上的不一致性。在本文中,我们将跨帧注意力机制重新设计为一种基于流的引导注意力机制,该机制会在查询 标记上建立时间相关性以消除时间上的不一致性。
4、Flow-guided Attention
如图 3.1 的左侧所示,我们首先从源视频中提取 流动的运动。一种直接的方法是从源视频 V 中提取光流。然而,在文本引导的运动转换中,目标文本提示 可能与源视频非常不同。以图 ?? 为例,源视频的提示 是“一个男人在跳舞”,但目标提示是“一只熊猫在月 亮背景下跳舞”。在这种情况下,从视频帧中提取的光 流无法描述“熊猫”和“男人”之间由于结构差异导 致的“熊猫”与“男人”的时间对应关系。在这种情 况下,光流无法用于扭曲查询。
我们注意到,姿势序列可以在领域差异的情况下 共享,外观流也可以通过姿势序列来预测。在这里, 我们使用在姿势序列 C = {Ci | i ∈ [1, N]} 上预 测外观流,并得到流序列 F = {fi⇒i−1 | i ∈ [2, N]}。同时,姿势序列 C = {Ci | i ∈ [1, N]} 也可以通过 [? ] 预测出映射 M = {mi | i ∈ [1, N]}。基于外观流和遮挡图,我们建立不同帧之间“查询”标记的时间相关性。如图 3.1 的右侧所示,在帧 i 中,我们首先使用调 整大小的流 fi⇒i−1 对上一帧的 query Qi−1 进行变形 1, 然后根据遮挡图 mi⇒i−1 将变形结果与原始查询标记 Qi 融合:
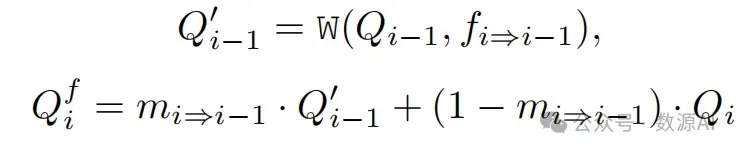
其中W(, ·,)是反向封装操作,Q′ i−1是query记号Qi−1的 变形结果, Q f i 是融合的query记号。现在我们通过用Q f i 替换方程2中的Qi来定义流引导的注意力:
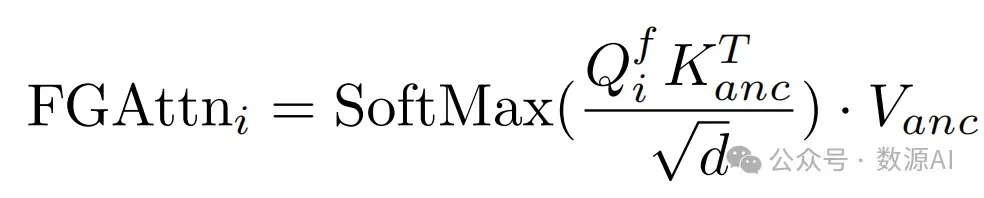
我们在SD的U-Net解码器上应用了流引导注意机制[3, 40],在我们的流引导注意机制中,流控制着不同帧之 间的“查询”标记,以及在不同帧之间共享值和键标 记,从而可以有效地保持时间上的连贯性。为了使翻译具有更少的领域差距, 我们还使 用HED边界作为条件。在这种条件下,我们使用从视 频帧中提取的光流,使用GMFlow,并遵循[16, 39], 基于变形误差计算遮挡地图。
实验与结果
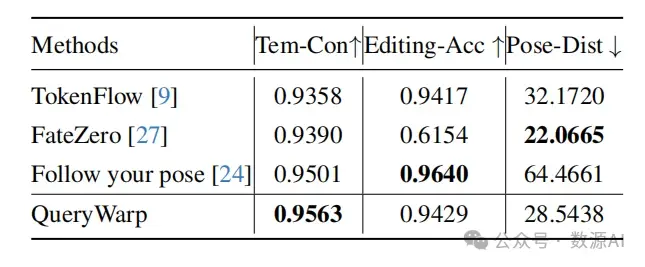
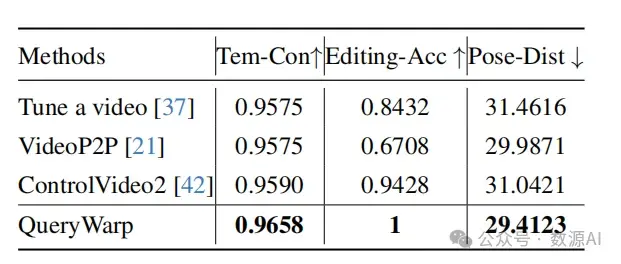
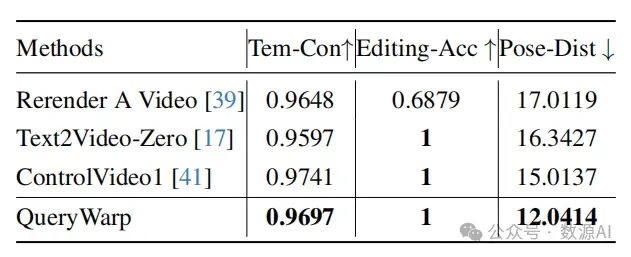
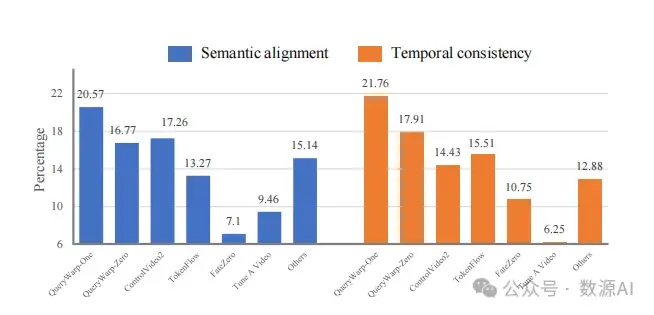
我们从互联网收集了40个人体运动视 频,其中包括舞蹈和与运动相关的视频。然后我们手 动添加字幕,形成文本-视频配对。我们的框架采用 了Stable Diffusion 1.5 和ControlNet 1.0 。根据以 往的研究 [37, 42],我们从每个视频中取样8帧,分辨率 为512×512。在取样过程中,我们使用带有50步和12个 无分类器指导的DDIM采样器进行推理。