一般来说,直接把最新版exe重新放在一个空目录,启动后,等待下载列表全部下载完毕,再点安装依赖,然后跟随引导启动,是不会有问题的
如果这里的疑难解答解决不了你的问题,请在评论区提问,我会补充到此
另外预设的配置比较保守,如果你的电脑能成功开启CUDA算子加速,一般可以使用比你实际显存多1-2GB的配置,如果你的配置自己改乱了,或者你想拉取最新预设配置,请删除本地的config.json文件,重启程序,如果你能理解配置页面的参数作用,可以无视预设配置,甚至全部删除,v1.0.8之前的用户,我建议将config.json删除,重新拉取最新预设配置,增加和调整了8G,12G,16G的预设,并全部默认开启了CUDA算子加速
16系和40系显卡开启CUDA算子加速后启动失败
删除目录下的cache.json,然后重启程序,会拉取最新的算子,你可以在下载列表查看
三方应用API接口调用报错
同样删除cache.json,重启拉取最新API程序,检查下载列表,等待完成
一个典型的调用API的示例是,打开浏览器控制台,粘贴执行以下代码,你应该能看到输出回答
fetch("http://127.0.0.1:8000/chat/completions", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ messages: [{ role: "user", content: "你好" }] }),
})
.then((r) => r.json())
.then(console.log);
软件自动更新下载不动,想要手动下载覆盖,正确操作姿势
如果你希望同时拉取最新相关依赖,请删除cache.json,然后启动新版本exe
如果你在离线环境部署,请保留cache.json,或至少自己新建一个空的cache.json文件,避免拉取最新依赖,离线环境想要手动更新API,参考下面第6点
点击安装依赖后,几个黑窗一闪而过
请检查下载列表所有内容是否都已经下载完毕,下载完毕后再点击安装依赖,如果没在下载的,请自己手动再点一下继续,如果下载列表是空的,说明本地文件都正常,可以安装依赖
如果始终下载不动,可以自己前往github手动下载,参考这个链接:https://github.com/josStorer/RWKV-Runner/issues/18
如何使用专用的小说模型
在这里下载小说模型,https://huggingface.co/BlinkDL/rwkv-4-novel/tree/main,然后放在models目录,刷新模型列表,启动后,进入补全页面使用,模型类型说明参考此文:https://zhuanlan.zhihu.com/p/618011122
注意小说模型不适合对话,仅限写作
6. 内网离线环境更新python API
与第4步一样,参考https://github.com/josStorer/RWKV-Runner/issues/18,手动下载放置到目录中
7. 启动出现500错误,切换模型失败
一种可能是显存不足,启动前,打开任务管理器查看显存占用然后看增长过程中是否占满了,占满后出这个错误就是显存不足,在配置页面降低载入显存层数
另一种可能,请检查错误里是否有not enough memory文字,你可以框选把所有内容复制到记事本,然后搜索
如果有,说明是你的内存不足,一般是开启int8量化出现的错误,如果你电脑内存比较大的,请退出一些无用程序再启动
如果你内存不多,典型的例如16G内存,但显卡是3060,4060,本身性能充足,只是不能量化,可以尝试增大虚拟内存,如果还是失败,可前往此链接下载量化好的模型,并放在models目录下,然后刷新列表: https://huggingface.co/appleatiger/rwkv_cuda_i8/tree/main
注意此链接是全层数int8量化,你不把载入层数拉满不能运行,如果你显存只够载入一部分,也可以让别人帮你按你的层数转换完毕,再发给你
8G显存开启CUDA算子可以跑完整的7B int8模型,从上面的地址下载后,使用如下配置即可,注意不要开启输出层高精度:
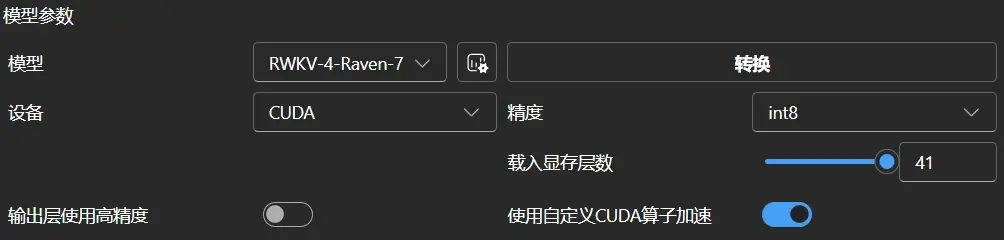
8. 从其他途径获取到了int8量化模型,而不是用runner转换的,启动失败
一般其他途径获取到的都是满层数量化,你要在runner使用,需要把载入显存层数拉满,关闭输出层使用高精度,精度选择int8,然后打开CUDA算子加速,就像上面那张图一样
9. 你是10,16,20,30,40系显卡用户,但是开启CUDA算子加速失败
检查py310\Lib\site-packages目录下,是否有这个文件夹torch-1.13.1+cu117.dist-info,如果没有,往往可能是装了torch-2.0.x,将两个torch目录删除,并把exe所在目录的cache.json删除,然后运行runner,让它自己重新安装依赖
10. 输出乱码
请更新显卡驱动
11. Torch not compiled with CUDA enabled
和上面第9点一样
最后,一个标准的离线环境目录结构是这样的