
前篇-数学的基石(SDE版)
扩散模型可以说是数学性很强的模型了,如果你研究物理和数学,那么将会对你大有帮助
首先说一下以前常见的生成模型GAN,VAE和Flow-based 模型。
它们在生成高质量样本方面取得了巨大成功,但各自也存在一些局限性。GAN模型因其对抗性训练的本质可能导致训练不稳定以及生成多样性不足,VAE依赖于替代损失,Flow模型必须使用专门的架构来构建可逆变换。
扩散模型受非平衡热力学的启发。它们定义了一个扩散步骤的马尔可夫链,逐渐向数据添加随机噪声,然后学习逆转扩散过程,从噪声中构造期望的数据样本。与变分自编码器或流模型不同,扩散模型使用固定的过程进行学习,并且潜在变量具有高维度(与原始数据相同)。
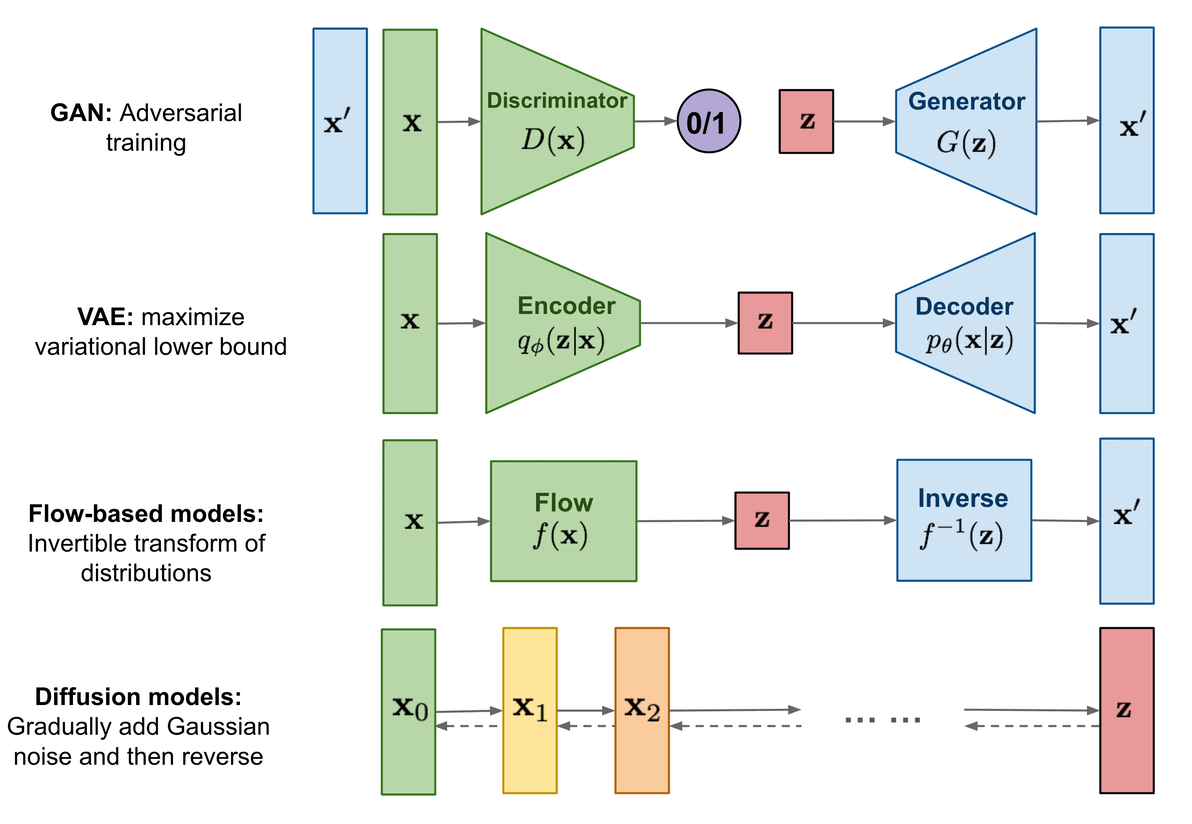
Overview of different types of generative models
所以什么是扩散模型呢?
几份重要的工作:
扩散概率模型 diffusion -----------(Sohl-Dickstein et al., 2015)
噪声条件评分网络 NCSN ---------(Yang & Ermon, 2019)
去噪扩散概率模型 DDPM---------(Ho et al. 2020)
DDPM其实和变分自编码器VAE有很大联系,但是他自称扩散,那我们还是尊重他~
扩散模型的前向过程
给定真实图片,diffusion前向过程通过 T 次累计对其添加高斯噪声,得到,如下图的q过程。这里需要给定一系列的高斯分布方差的超参数
。前向过程由于每个时刻 T只与t-1时刻有关,所以也可以看做马尔科夫过程:
这个过程中,随着 t 的增大,越来越接近纯噪声。当 , 是完全的高斯噪声 (下 面会证明,且与均值系数 的选择有关) 。且实际中 随着增大是递增的,即 。在GLIDE的code中, 是由 0.0001 到0.02线性插值 (以 T=1000 为基准, T 增加, 对应降低)。
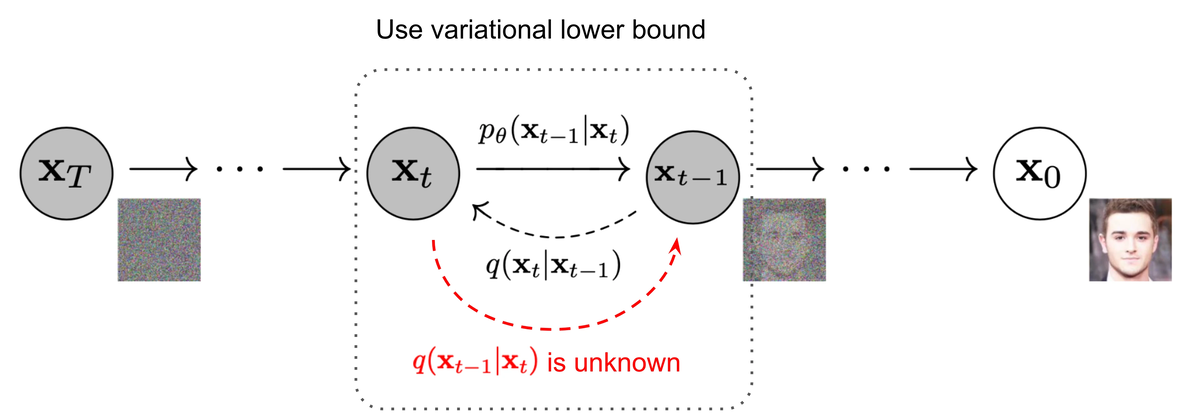
The Markov chain of forward (reverse) diffusion process of generating a sample by slowly adding (removing) noise. (Image source: Ho et al. 2020 with a few additional annotations)
上述过程的很好的特性是我们可以采样 在任何任意时间步长 t 以封闭形式使用重新参数化技巧。假设:
回想一下,当我们合并两个具有不同方差的高斯分布时时,和 ,新的分布是。这里的合并后的标准差为 。
由此当样本变得更嘈杂时,我们可以承受更大的更新步长,所以 且 。
扩散模型的反向过程
如果我们能逆转上述过程并从中采样 ,我们将能够从高斯噪声输入中重新创建真实样本,。请注意,如果 足够小, 也将是高斯分布的。不幸的是,我们无法轻易估计 因为它需要使用整个数据集,因此我们需要学习一个模型近似这些条件概率,以便运行反向扩散过程。
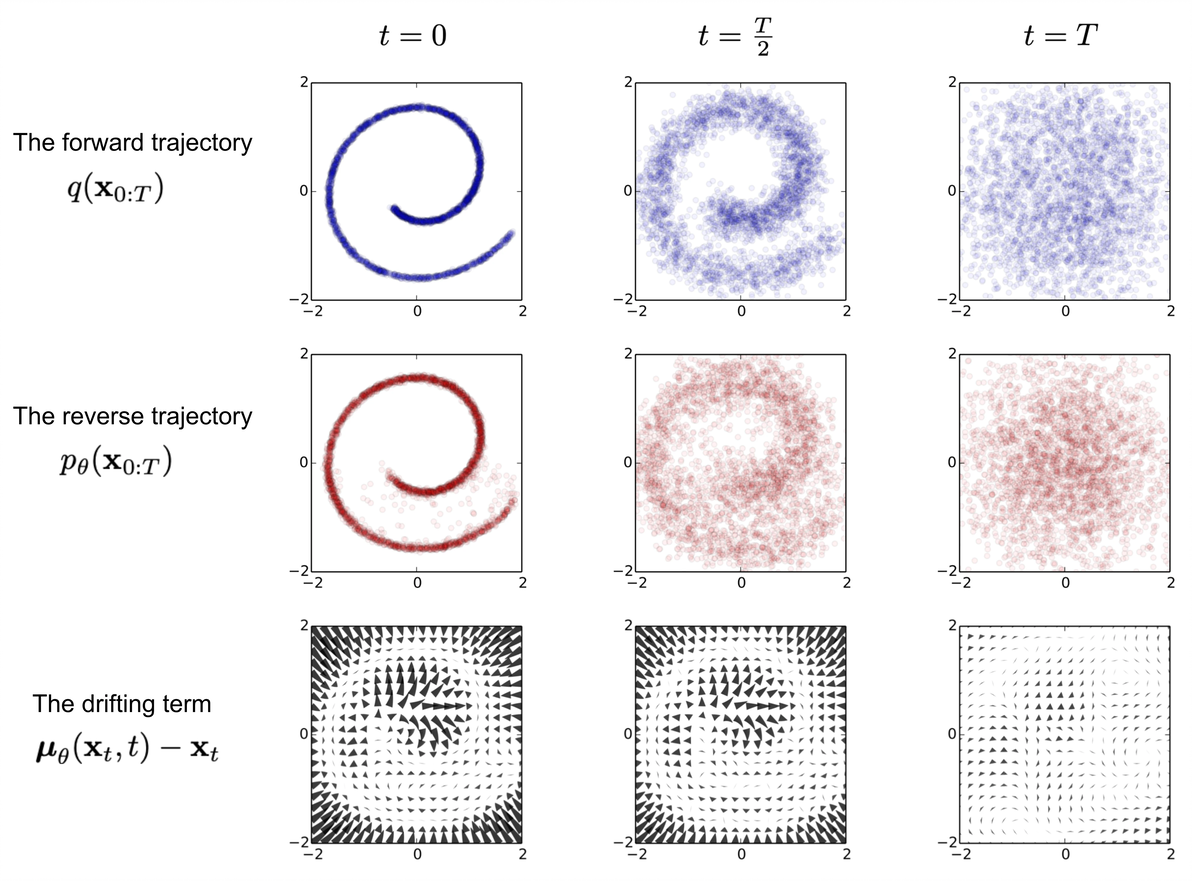
An example of training a diffusion model for modeling a 2D swiss roll data. (Image source: Sohl-Dickstein et al., 2015)
虽然我们无法得到逆转后的分布 ,但是如果知道 ,是可以通过贝叶斯公式得到 为:
过程:
遵循标准高斯密度函数,均值和方差可以参数化如下:
根据前向过程的特性,我们可以得到 并将其代入上述等式并获得:
其中高斯分布为深度模型所预测的噪声 (用于去噪) ,可看做为 ,即得到:
这样的设置和VAE非常相似,因此我们可以使用变分下限来优化负对数似然。
通过使用詹森不等式获得相同的结果也很简单。
为了将方程中的每个项转换为可解析计算的项,可以进一步将目标重写熵与多个KL散度的累加
或者写为

突然打不出公式,只能截图了。。。
但是根据后来的实验结果显示,使用忽略加权项的简化目标训练扩散模型效果更好:
最终简化为:
加速扩散模型采样
通过遵循反向扩散过程的马尔可夫链从DDPM生成样品非常慢,因为 T 需要几千步才能获得高质量的结果。
DDIM中则提出了一种牺牲多样性来换取更快推理的手段。
本文就省略其数学推断过程,直接给出结论。
与DDPM相比,DDIM能够:
使用更少的步骤生成更高质量的样本。
具有“一致性”属性,因为生成过程是确定性的,这意味着以同一潜在变量为条件的多个样本应该具有类似的高级特征。
由于一致性,DDIM 可以在潜在变量中执行语义上有意义的插值。
LDM则将扩散过程放在潜在空间(隐空间)而不是像素空间中进行扩散过程,进一步降低了训练成本,提高了推理速度。具体过程可见于前篇。
DPM-Solver则是DDIM的高阶形式,基于DPM-Solver扩散模型的采样速度直接翻倍。

后篇-扩散的控制
如果你有GAN或者VAE的基础或者了解过不少,你可能会发现其中的相似之处,尤其DDPM的推导中还利用了VAE的思路。
在笔者看来,生成式扩散模型脱胎于传统VAE(非传统的暂时不了解~汗),VAE和扩散模型都大量利用到了高斯分布,而VAE则是编码-生成一步到位,而扩散模型将编码-生成的步骤进行了分解,一个直观的想法是,多步相比单步更能对真实的分布进行拟合,比如傅里叶级数,用简单函数叠加拟合复杂函数。
而扩散模型与GAN的联系可以通过《Score-based Generative Modeling Secretly Minimizes the Wasserstein Distance》这篇文章略窥一二,而对比GAN这种更加一步到位在训练中不确定性大的模型,扩散模型这种平稳小步的节奏算得上一种优势。
那么,代价是什么呢?
从原版DDPM采样需要上千步就能看出,扩散模型的采样速度太慢,尽管后续推出了数种加快采样的方法,但是相比GAN仍有差距,估计扩散模型的采样加速也将成为之后的研究重点。
最终模型还是得回归到实际应用上,所以条件控制生成结果也是重点。我们通常将无条件生成能力视为模型的上限,而光有上限不够,我们还需要考察模型的控制能力,我们能否利用模型输出我们想要的东西。
事实上,扩散模型的火爆也得益于条件生成,比如DALL-2,midjoury,Imagen(还有本文的主角stable diffusion....),这也是我们第二篇的主题,前面的算作序幕好了......
按照第一篇的规矩,我们希望直观地展示其中原理。
回到我们亲切的stable-diffusion,如果你是涩图炼丹师傅绝对对以下概念并不陌生
创建Embedding
创建超网络(Hypernetwork)
DreamBooth
LoRA
ControlNet
那么我们就来粗略地看看,有个大概的印象.....
Textual Inversion(Embedding)
中文名称译为文本反转
何为反转?让我们回想第一篇写扩散模型的生成的最开始的例子,我们不仅可以将文本作为输入,也可以将图片作为输入。
但是我们实际在使用文生图模型的过程中,常常会感到词穷,无法用自然语言去详细地指导我们图片的生成(难道只有我?),而模型也不能很好地将我们的语言进行理解。那么我们为什么不用富含更多信息的二维图像来指导我们的图像生成呢?
但是通过图像进行生成显然不够“文生图”这一过程,而且可能不太方便输入。那么我们直接将图片与文本进行映射不就方便通过文本输入图像信息了吗。
文本反转正是将图片转换为伪单词(pseudo-words)作为prompt来影响我们的生成结果。
具体过程涉及到文本编码器的工作原理,详细介绍会在第四章
当然文本反转也不止指将图片与文本做个映射,还包括将一些有联系的词映射到一个创建的新的关键词(embedding),比如最近很火的一些模型将一系列ntags或者tags浓缩到一个特殊词(实际训练时是通过一系列tags生成图片,然后对这一系列图片进行文本反转,就能用特殊词替代他们),大大减少了魔法师的吟唱时间......
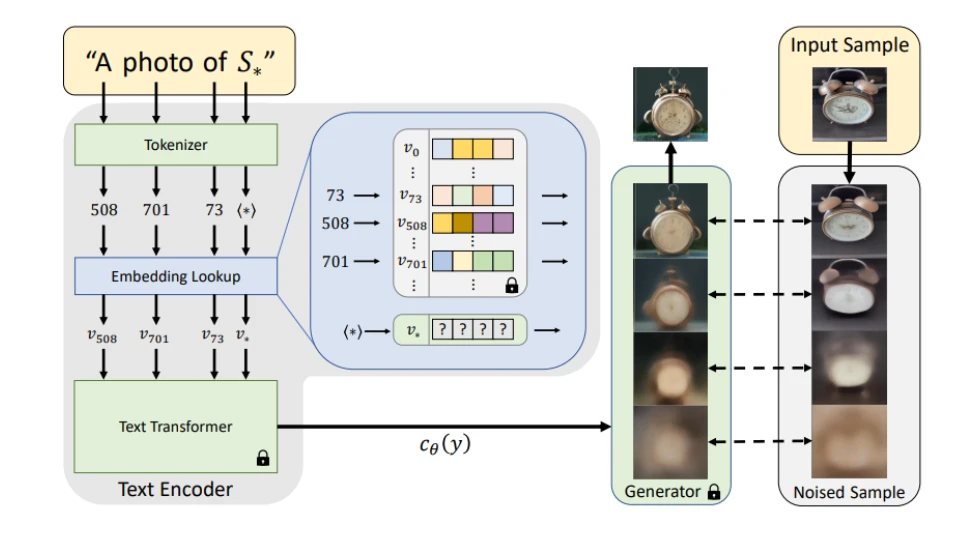
原始论文的网络图
stable-diffuison-webui允许用户使用Textual Inversion将自己的图片进行训练,得到一个embedding用于指导新的图片生成,其大小通常为几十KB,后缀为.pt或.safetensors或者.bin
Hypernetwork
中文译名为超网络
何为超网络(扩散模型中)?Hypernetwork是一个单独的小型神经网络模型,该模型用于输出可以插入到原始Diffusion模型的中间层。
让我们回到前篇,我们将语义信息与图片产生联系时,引入了crossattention(注意力交叉)机制,而我们的超网络则劫持了这部分来插入样式,最终达成对生成结果的影响。(LoRA模型同样也修改了这部分但是方式不同)
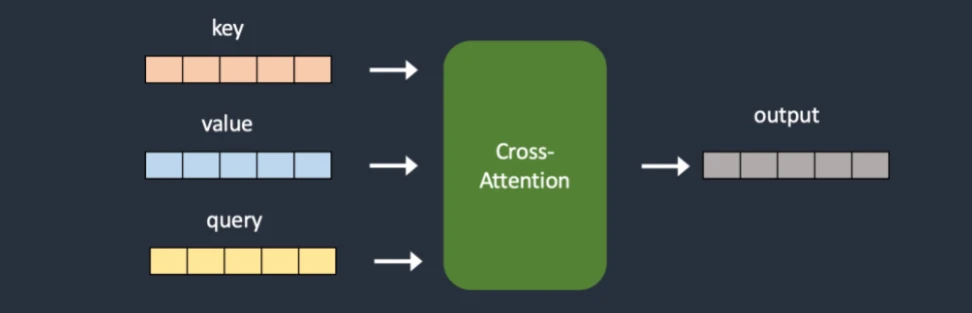
原始扩散模型的交叉注意力模块
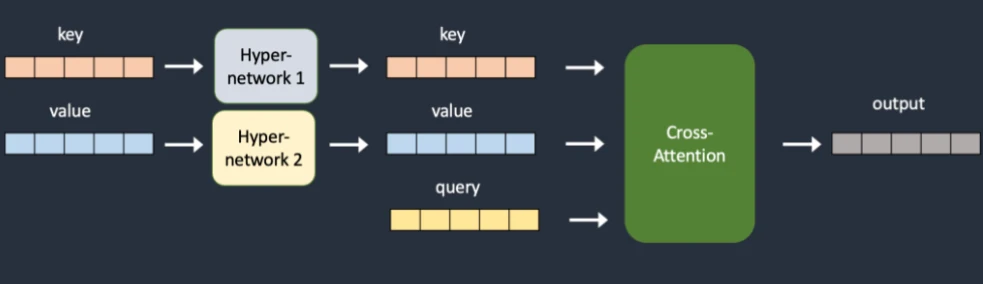
超网络注入额外的神经网络参数来转换键和值
stable-diffuison-webui同样允许用户训练超网络,训练过程中原本模型参数将被锁定,但是由于超网络一般为小型网络所以开销小,速度快。其大小通常小于200MB,后缀为.pt或.safetensors
DreamBooth
中文译名为梦想厅??
It’s like a photo booth, but once the subject is captured, it can be synthesized wherever your dreams take you.
何为DreamBooth?和它的名称一样,DreamBooth比较强调个性。DreamBooth的论文中提出了文生图扩散模型“个性化”的方法,可以适应用户特定的生成需求。

只需 3 张训练图像,Dreambooth 就可以将自定义主题无缝地注入扩散模型
其原理是扩展目标模型的text-image 词典,将新的文本标识符与特定主题或图片进行联系,然后引导图片生成
所以为什么是DreamBooth而不是其他训练方式?众所周知小数据集会导致过度拟合,而且茫然地扩展text-image还会导致语义漂移(language drift)
而DreamBooth则通过一些方式解决了这些问题:
为新的主题使用一个罕见的词,避免语义漂移(prompt撞车)
保留同类的先验知识,通过设计一个损失函数,鼓励扩散模型不断生成与我们的主题相同大类别的不同实例。
看着是不是和我们之前讲到的文本反转(Textual Inversion)很像,请注意DreamBooth注入了一个罕见词,且微调了整个模型,而文本反转则是注入了一个新的关键词,只微调了模型的文本嵌入部分。
目前,stable-diffusion-webui允许用户在使用插件的情况下训练dreamBooth,通常3-10张图片即可(你想多弄点也行),需要注意你希望个性化的主体应该处于不同背景,以便于将主体与背景区分开来。由于这种训练方式微调了整个模型权重,所以你得到的将会是一个2-7G大小的模型文件,且后缀为.checkpoint或.safetensors
LoRA(Low Rank Adaption)
中文译名为低秩适配??
何为LoRA?LoRA并不是扩散模型专有的技术,而是从隔壁语言模型(LLM)迁移过来的,旨在解决避免将整个模型参数拷贝下来才能对模型进行调校的问题。因为大型语言模型的参数量过于恐怖,比如最近新出的GPT-4参数量约为100 万亿。
LoRA采用的方式是向原有的模型中插入新的数据处理层,这样就避免了去修改原有的模型参数,从而避免将整个模型进行拷贝的情况,同时其也优化了插入层的参数量,最终实现了一种很轻量化的模型调校方法。
和上文提到的Hypernetwork相同,LoRA在稳定扩散模型里也将注意打在了crossattention(注意力交叉)机制上,LoRA将会将自己的权重添加到注意力交叉层的权重中,以此来实现微调。
添加是以向量(矩阵)的形式,如果这样做,LoRA势必需要存储同样大小的参数,那么LoRA又有了个好点子,直接以向量(矩阵)相乘的形式存储,最终文件大小就会小很多了。
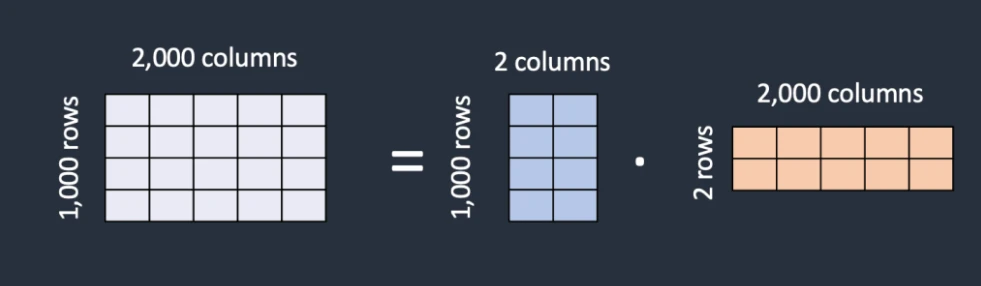
LoRA将一个大矩阵分解成俩个低秩矩阵
研究人员发现Hypernetwork也可以通过这种方式进行存储,对最终效果没有产生很大影响,所以貌似没有副作用。由于不会影响原有模型参数,所以相比Dreambooth训练更快且使用更少的显存。
这么看来Hypernetwork算是个低配版LoRA了,毕竟LoRA是隔壁“大户人家”提出的,对于如何最优化其训练速度及参数量都有着详实的研究理论及数据支撑。
目前stable-diffusion-webui可以允许用户在使用插件的情况下使用和训练LoRA模型,其大小通常为2-200MB,后缀为.bin或.pt或.safetensors
ControlNet
中文译名为控制网络
Let us control diffusion models!
何为ControlNet?ControlNet和它霸气大胆的名字一样是很有野心的,试图通过一系列措施掌控扩散模型。事实上它确实在一定程度上做到了,如果你经常使用稳定扩散模型,你就会明白想要稳定输出人物确切姿势有多难,而ControlNet却能帮你做到这一点。
我们通常用文本或图片来控制生成,而控制网络让我们能使用更多的条件(conditioning)来控制扩散模型。
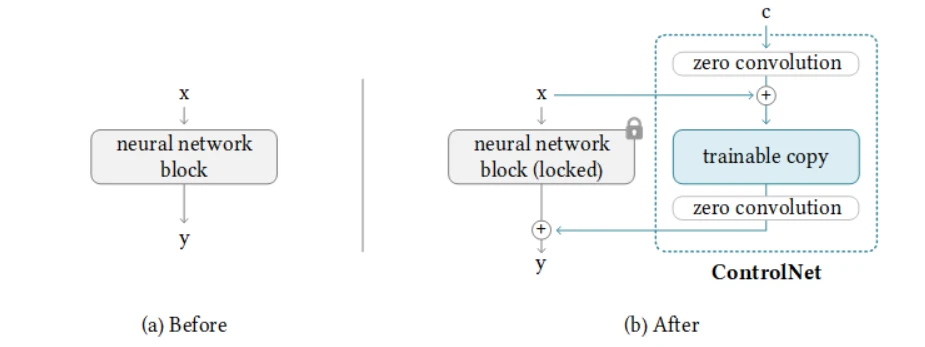
ControlNet将神经网络权重复制到一个锁定(locked)副本和一个可训练(trainable)副本。
可训练副本将会学习新加入的条件,而锁定副本将会保留原有的模型,得益于此在进行小数据集训练时不会破坏原有的扩散模型。
通过多次重复利用上图结构(附加到稳定扩散模型的U-Net(噪声预测器)的各个部分),我们可以控制稳定扩散模型如下图:
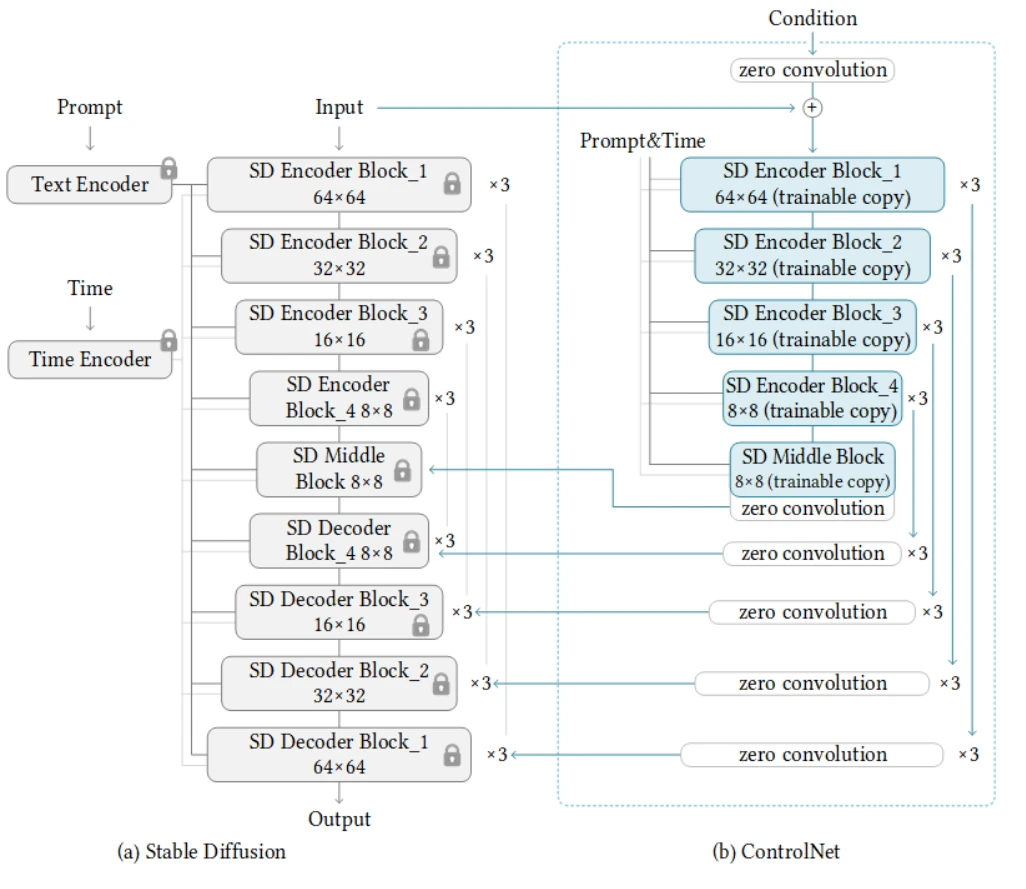
通过这种方式ControlNet能重复利用SD编码器作为深厚、坚强、强壮、有力的主干(deep, strong, robust, and powerful backbone)来学习各种控制。尽管添加了很多层,但是由于连接层的高效率,GPU消耗并不比之前高出多少。
让我们来看看ControlNet具体能做到哪些
Edge detection(边缘检测)
ControlNet通过获取额外的输入图像并使用Canny边缘检测器来获取轮廓图,轮廓图将会作为额外的条件(conditioning)被送入ControlNet 模型(Stable Diffusion ControlNet)中然后进行稳定扩散,如下图。
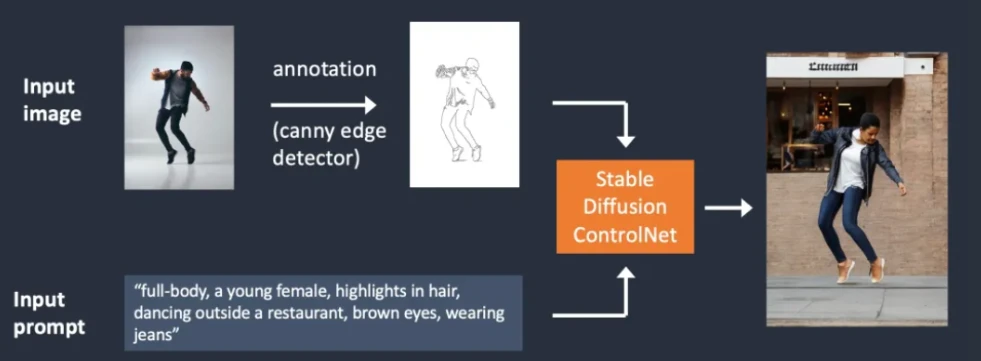
Canny edge conditioning
Human pose detection(人体姿势探测)
同理,我们不仅可以将轮廓或边缘作为输入进行预处理,还能通过探测人体姿势。Openpose关键点检测器可以提取人体的姿势,比如头、手和腿部的位置信息,如下图。
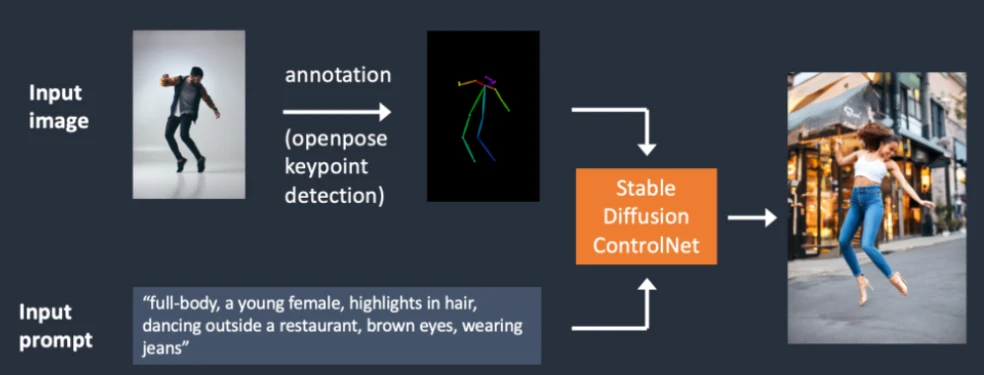
Input image annotated with human pose detection using Openpose
和边缘检测类似,提取出来的人体姿势信息将会作为额外条件被送入进行稳定扩散。
你可能已经注意到了其中的共同之处是检测器(detector),这是ControlNet训练出的模型,那么ControlNet有哪些模型呢?
OpenPose detector
Canny edge detector
Straight line detector -- 一种快速直线检测器(M-LSD Lines),可以提取具有直边的轮廓,如室内设计,街景等
HED edge detector -- 也是一种边缘检测器(HED Boundary),擅长像真人绘画一样产生轮廓图,适用于重新择色和重新设计图像
Scribbles -- 用户涂鸦检测器(User Scribbles),字面意思,擅长将你的涂鸦内容转换成图片
Depth Map -- 可以从输入图像推断出深度图,相比于stable-diffusion V2的depth-to-image,Depth Map能产生更高分辨率的结果。
Normal map -- 法线贴图指定了物体表面的三维方向。这是在由多边形构成的低分辨率表面上伪造纹理的常见方法。当然,你只有一个二维输入图像。法线贴图是从深度图计算出来的。
Anime Line Drawing -- 使用动漫线条训练了一个相对简单的模型,可以提取动漫图片的线稿,可能对涩图炼丹师有所帮助(汗
.......
这些detector模型配合上被定制化训练出来的Stable Diffusion ControlNet模型就能达成特定目标
可以见得ControlNet的潜力和野心都很大,目前stable-diffusion-webui用户已经可以插件来安装并使用ControlNet了,如果你有基础和A100你也能定制自己的ControlNet模型将更多的条件加入到生成,彻底发挥扩散模型的潜力。
到此,我们应该对扩散模型已经有了偏前沿的了解了~
下篇我们讲讲细枝末节和具体的使用和训练
