
前言
常常会苦恼,平常做的项目很普通,没啥亮点;面试中也经常会被问到:做过哪些亮点项目吗?
前端监控就是一个很有亮点的项目,各个大厂都有自己的内部实现,没有监控的项目好比是在裸奔
文章分成以下六部分来介绍:
自研监控平台解决了哪些痛点,实现了什么亮点功能?
相比sentry等监控方案,自研监控的优势有哪些?
前端监控的设计方案、监控的目的
数据的采集方式:错误信息、性能数据、用户行为、加载资源、个性化指标等
设计开发一个完整的监控SDK
监控后台错误还原演示示例
痛点
某⼀天用户:xx商品无法下单! ⼜⼀天运营:xx广告在手机端打开不了!
大家反馈的bug,怎么都复现不出来,尴尬的要死!😢
如何记录项目的错误,并将错误还原出来,这是监控平台要解决的痛点之一
错误还原
web-see[1] 监控提供三种错误还原方式:定位源码、播放录屏、记录用户行为
定位源码
项目出错,要是能定位到源码就好了,可线上的项目都是打包后的代码,也不能把 .map 文件放到线上
监控平台通过 source-map[2] 可以实现该功能
最终效果:

播放录屏
多数场景下,定位到具体的源码,就可以定位bug,但如果是用户做了异常操作,或者是在某些复杂操作下才出现的bug,仅仅通过定位源码,还是不能还原错误
要是能把用户的操作都录制下来,然后通过回放来还原错误就好了
监控平台通过 rrweb[3] 可以实现该功能
最终效果:
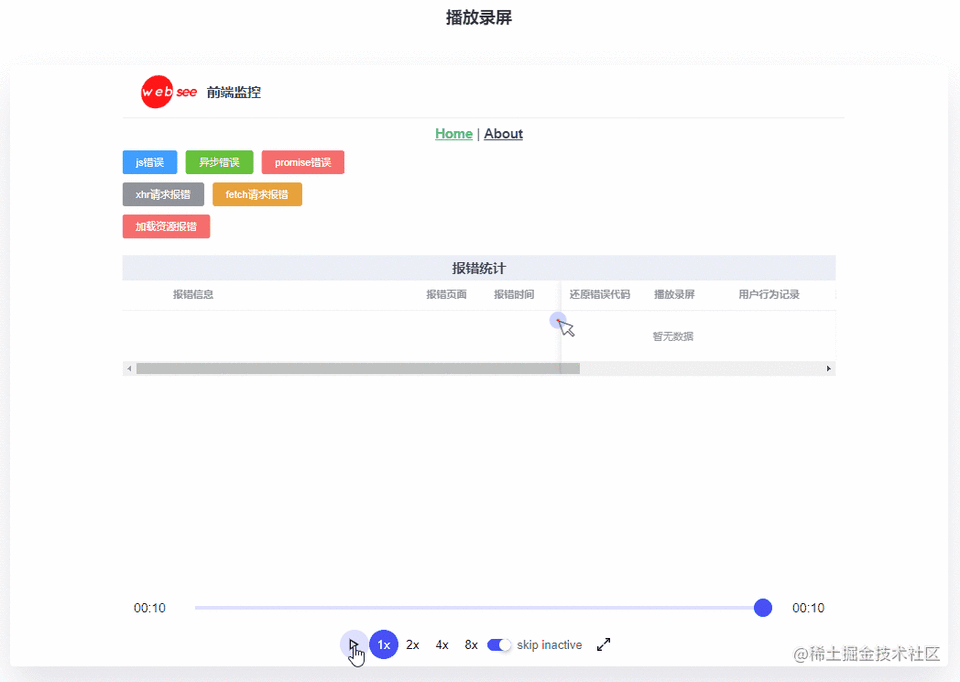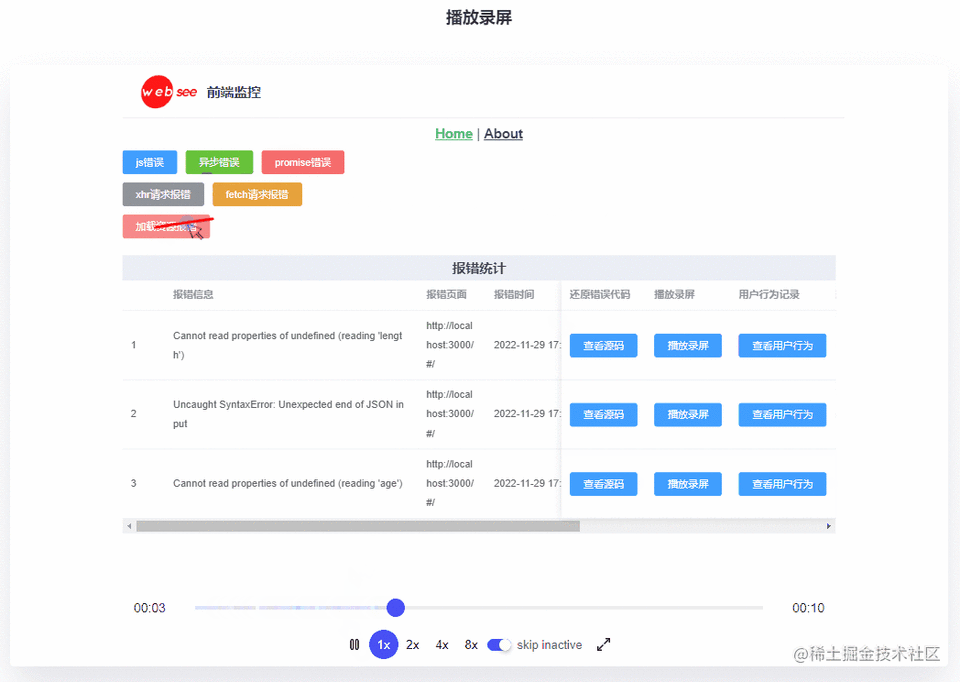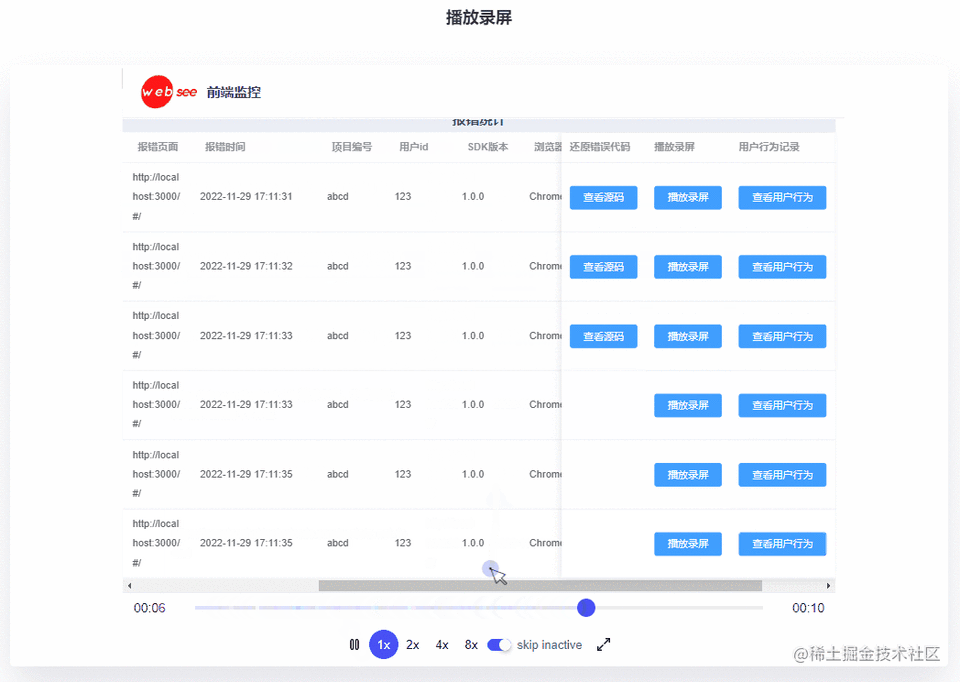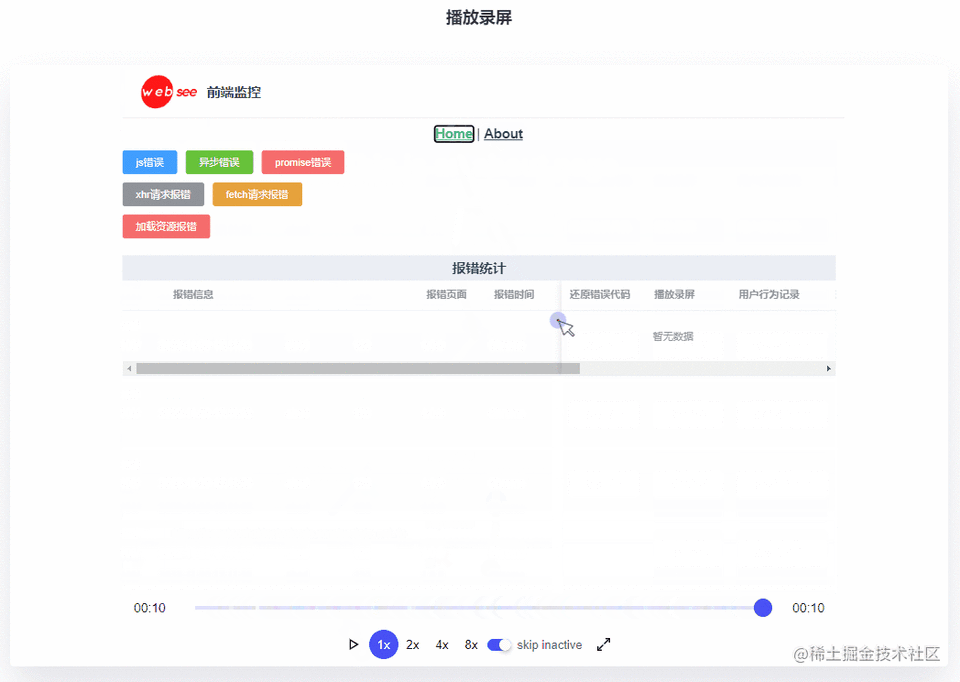
回放的录屏中,记录了用户的所有操作,红色的线代表了鼠标的移动轨迹
前端录屏确实是件很酷的事情,但是不能走极端,如果把用户的所有操作都录制下来,是没有意义的
我们更关注的是,页面报错的时候用户做了哪些操作,所以监控平台只把报错前10s的视频保存下来(单次录屏时长也可以自定义)
记录用户行为
通过 定位源码 + 播放录屏 这套组合,还原错误应该够用了,同时监控平台也提供了 记录用户行为 这种方式
假如用户做了很多操作,操作的间隔超过了单次录屏时长,录制的视频可能是不完整的,此时可以借助用户行为来分析用户的操作,帮助复现bug
最终效果:

用户行为列表记录了:鼠标点击、接口调用、资源加载、页面路由变化、代码报错等信息
通过 这三板斧,解决了复现bug的痛点
自研监控的优势
为什么不直接用sentry私有化部署,而选择自研前端监控?
这是优先要思考的问题,sentry作为前端监控的行业标杆,有很多可以借鉴的地方
相比sentry,自研监控平台的优势在于:
1、可以将公司的SDK统一成一个,包括但不限于:监控SDK、埋点SDK、录屏SDK、广告SDK等
2、提供了更多的错误还原方式,同时错误信息可以和埋点信息联动,便可拿到更细致的用户行为栈,更快的排查线上错误
3、监控自定义的个性化指标:如 long task、memory页面内存、首屏加载时间等。过多的长任务会造成页面丢帧、卡顿;过大的内存可能会造成低端机器的卡死、崩溃
4、统计资源缓存率,来判断项目的缓存策略是否合理,提升缓存率可以减少服务器压力,也可以提升页面的打开速度
5、提供了 采样对比+ 轮询修正机制 的白屏检测方案,用于检测页面是否一直处于白屏状态,让开发者知道页面什么时候白了,具体实现见 前端白屏的检测方案,解决你的线上之忧[4]
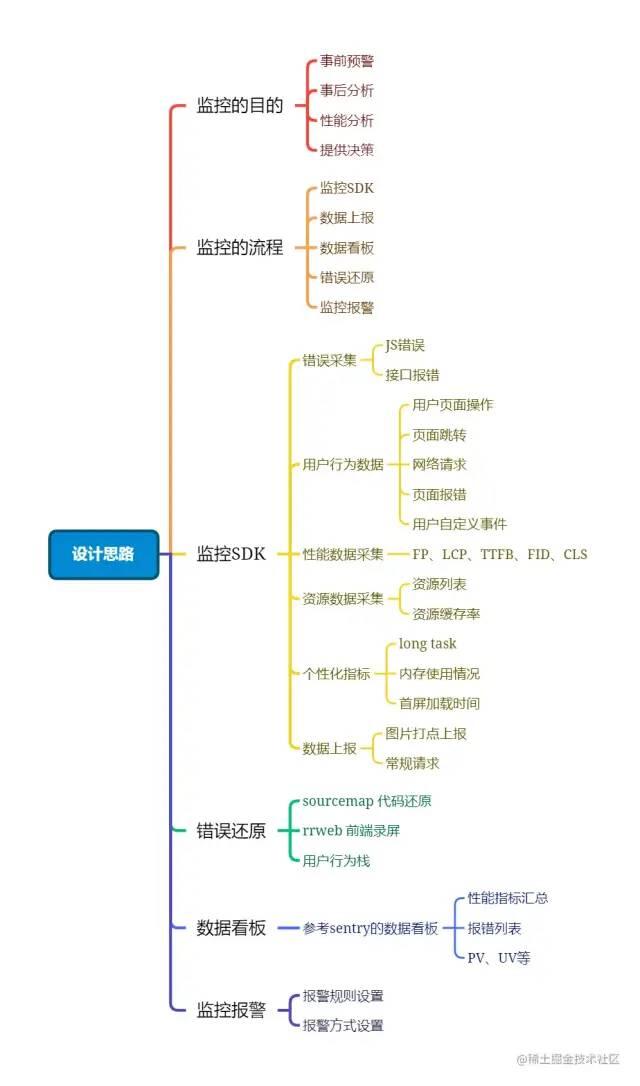
设计思路
一个完整的前端监控平台包括三个部分:数据采集与上报、数据分析和存储、数据展示
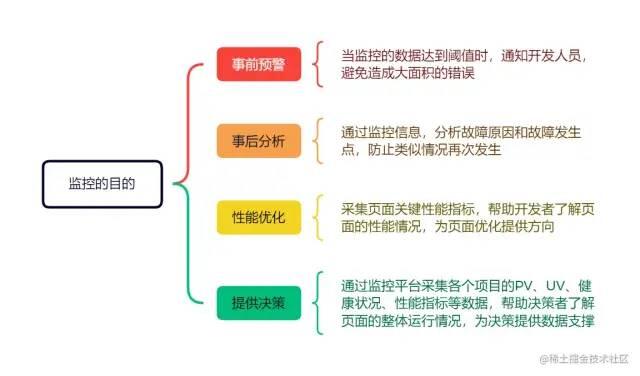
监控目的
异常分析
按照 5W1H 法则来分析前端异常,需要知道以下信息
What,发⽣了什么错误:JS错误、异步错误、资源加载、接口错误等
When,出现的时间段,如时间戳
Who,影响了多少用户,包括报错事件数、IP
Where,出现的页面是哪些,包括页面、对应的设备信息
Why,错误的原因是为什么,包括错误堆栈、⾏列、SourceMap、异常录屏
How,如何定位还原问题,如何异常报警,避免类似的错误发生
错误数据采集
错误信息是最基础也是最重要的数据,错误信息主要分为下面几类:
JS 代码运行错误、语法错误等
异步错误等
静态资源加载错误
接口请求报错
错误捕获方式
1)try/catch
只能捕获代码常规的运行错误,语法错误和异步错误不能捕获到
示例:
2) window.onerror
window.onerror 可以捕获常规错误、异步错误,但不能捕获资源错误
示例:
3) window.addEventListener
当静态资源加载失败时,会触发 error 事件, 此时 window.onerror 不能捕获到
示例:
4)Promise错误
Promise中抛出的错误,无法被 window.onerror、try/catch、 error 事件捕获到,可通过 unhandledrejection 事件来处理
示例:
Vue 错误
Vue项目中,window.onerror 和 error 事件不能捕获到常规的代码错误
异常代码:
main.js中添加捕获代码:
控制台会报错,但是 window.onerror 和 error 不能捕获到
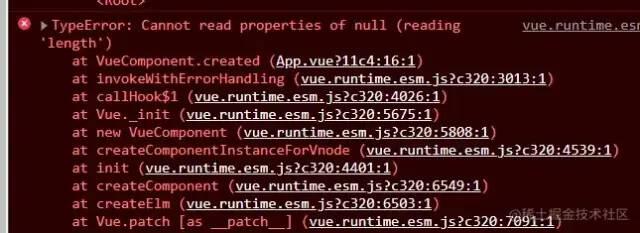
vue 通过 来捕获异常:
控制台打印:
errorHandler源码分析
在目录下,有一个文件
通过源码明白了,vue 使用 try/catch 来捕获常规代码的报错,被捕获的错误会通过 console.error 输出而避免应用崩溃
可以在 Vue.config.errorHandler 中将捕获的错误上报
React 错误
从 react16 开始,官方提供了 ErrorBoundary 错误边界的功能,被该组件包裹的子组件,render 函数报错时会触发离当前组件最近父组件的ErrorBoundary
生产环境,一旦被 ErrorBoundary 捕获的错误,也不会触发全局的 window.onerror 和 error 事件
父组件代码:
子组件代码:
同vue项目的处理类似,react项目中,可以在 componentDidCatch 中将捕获的错误上报
跨域问题
如果当前页面中,引入了其他域名的JS资源,如果资源出现错误,error 事件只会监测到一个 的异常。
示例:
报错信息:
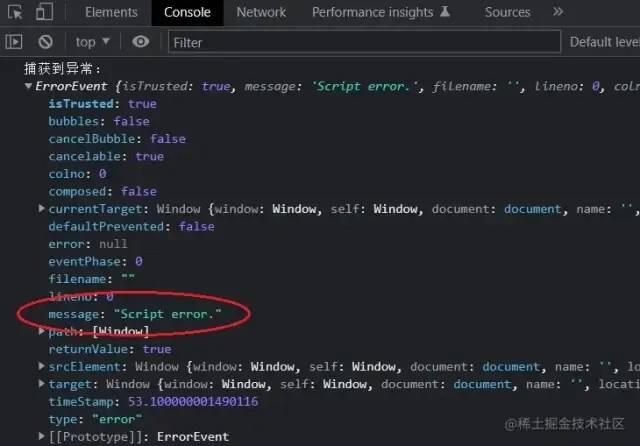
只能捕获到 的原因:
是由于浏览器基于,故意隐藏了其它域JS文件抛出的具体错误信息,这样可以有效避免敏感信息无意中被第三方(不受控制的)脚本捕获到,因此,浏览器只允许同域下的脚本捕获具体的错误信息
解决方法:
前端script加crossorigin,后端配置 Access-Control-Allow-Origin
添加 crossorigin 后可以捕获到完整的报错信息:
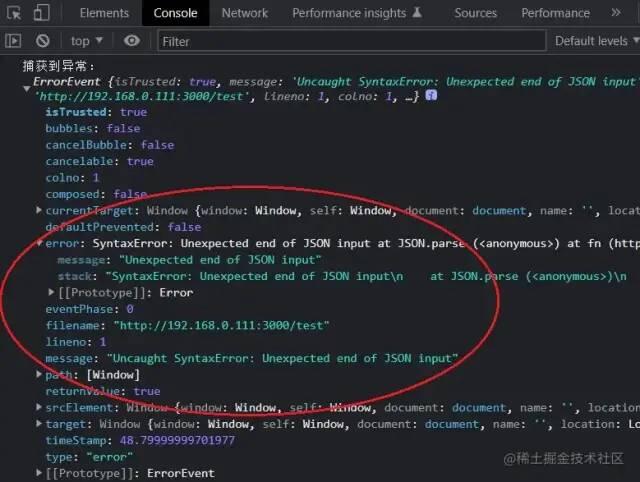
如果不能修改服务端的请求头,可以考虑通过使用 try/catch 绕过,将错误抛出
接口错误
接口监控的实现原理:针对浏览器内置的 XMLHttpRequest、fetch 对象,利用 AOP 切片编程重写该方法,实现对请求的接口拦截,从而获取接口报错的情况并上报
1)拦截XMLHttpRequest请求示例:
2)拦截fetch请求示例:
性能数据采集
谈到性能数据采集,就会提及加载过程模型图:
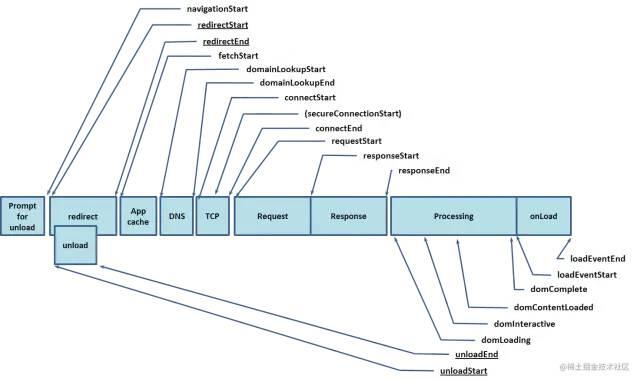
以Spa页面来说,页面的加载过程大致是这样的:
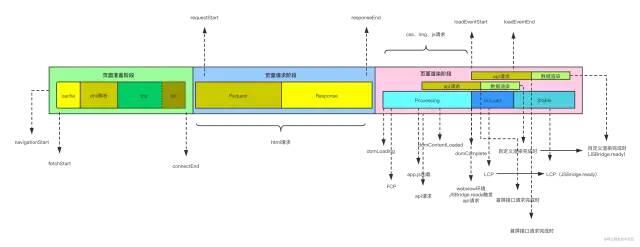
包括dns查询、建立tcp连接、发送http请求、返回html文档、html文档解析等阶段
最初,可以通过 来获取加载过程模型中各个阶段的耗时数据
后来 window.performance.timing 被废弃,通过 PerformanceObserver[5] 来获取。旧的 api,返回的是一个 类型的绝对时间,和用户的系统时间相关,分析的时候需要再次计算。而新的 api,返回的是一个相对时间,可以直接用来分析
现在 chrome 开发团队提供了 web-vitals[6] 库,方便来计算各性能数据(注意:web-vitals 不支持safari浏览器)
用户行为数据采集
用户行为包括:页面路由变化、鼠标点击、资源加载、接口调用、代码报错等行为
设计思路
1、通过Breadcrumb类来创建用户行为的对象,来存储和管理所有的用户行为
2、通过重写或添加相应的事件,完成用户行为数据的采集
用户行为代码示例:
页面跳转
通过监听路由的变化来判断页面跳转,路由有两种模式,history模式可以监听事件,hash模式通过重写 事件
vue项目中不能通过 事件来监听路由变化, 底层调用的是 和 ,不会触发 hashchange
vue-router源码:
通过重写 pushState、replaceState 事件来监听路由变化
用户点击
给 document 对象添加click事件,并上报
资源加载
获取页面中加载的资源信息,比如它们的 url 是什么、加载了多久、是否来自缓存等,最终生成 资源加载瀑布图[7]
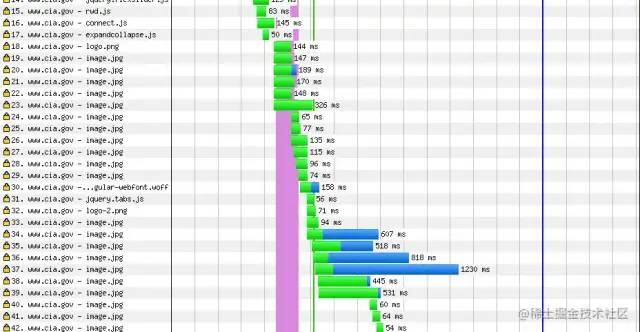
瀑布图展现了浏览器为渲染网页而加载的所有的资源,包括加载的顺序和每个资源的加载时间
分析这些资源是如何加载的, 可以帮助我们了解究竟是什么原因拖慢了网页,从而采取对应的措施来提升网页速度
可以通过 performance.getEntriesByType('resource')获取页面加载的资源列表,同时可以结合 initiatorType 字段来判断资源类型,对资源进行过滤
其中 PerformanceResourceTiming[8] 来分析资源加载的详细数据
获取资源加载时长为 字段,即 的差值
获取加载资源列表:
一个真实的页面中,资源加载大多数是逐步进行的,有些资源本身就做了延迟加载,有些是需要用户发生交互后才会去请求一些资源
如果我们只关注首页资源,可以在 事件中去收集
如果要收集所有的资源,需要通过定时器反复地去收集,并且在一轮收集结束后,通过调用 clearResourceTimings[9] 将 performance entries 里的信息清空,避免在下一轮收集时取到重复的资源
个性化指标
long task
执行时间超过50ms的任务,被称为 long task[10] 长任务
获取页面的长任务列表:
memory页面内存
可以显示此刻内存占用情况,它是一个动态值,其中:
jsHeapSizeLimit 该属性代表的含义是:内存大小的限制。
totalJSHeapSize 表示总内存的大小。
usedJSHeapSize 表示可使用的内存的大小。
通常,usedJSHeapSize 不能大于 totalJSHeapSize,如果大于,有可能出现了内存泄漏
首屏加载时间
首屏加载时间和首页加载时间不一样,首屏指的是屏幕内的dom渲染完成的时间
比如首页很长需要好几屏展示,这种情况下屏幕以外的元素不考虑在内
计算首屏加载时间流程
1)利用监听对象,每当dom变化时触发该事件
2)判断监听的dom是否在首屏内,如果在首屏内,将该dom放到指定的数组中,记录下当前dom变化的时间点
3)在MutationObserver的callback函数中,通过防抖函数,监听状态的变化
4)当,停止定时器和 取消对document的监听
5)遍历存放dom的数组,找出最后变化节点的时间,用该时间点减去 得出首屏的加载时间
监控SDK
监控SDK的作用:数据采集与上报
整体架构
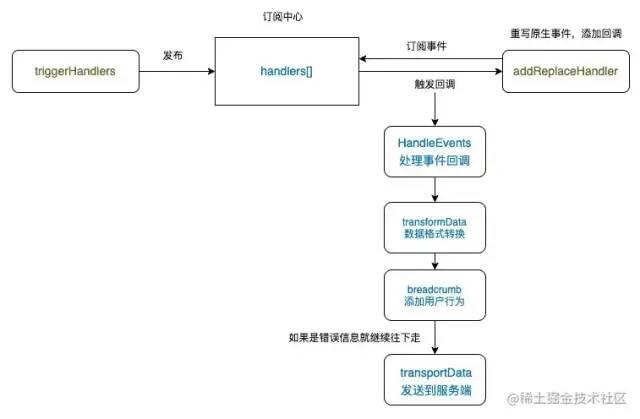
整体架构使用 发布-订阅 设计模式,这样设计的好处是便于后续扩展与维护,如果想添加新的或事件,在该回调中添加对应的函数即可
SDK 入口
对外导出init事件,配置了vue、react项目的不同引入方式
vue项目在Vue.config.errorHandler中上报错误,react项目在ErrorBoundary中上报错误
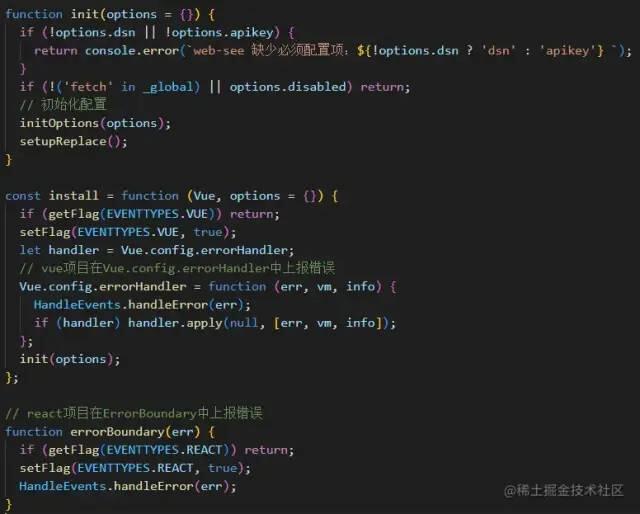
事件发布与订阅
通过添加监听事件来捕获错误,利用 AOP 切片编程,重写接口请求、路由监听等功能,从而获取对应的数据
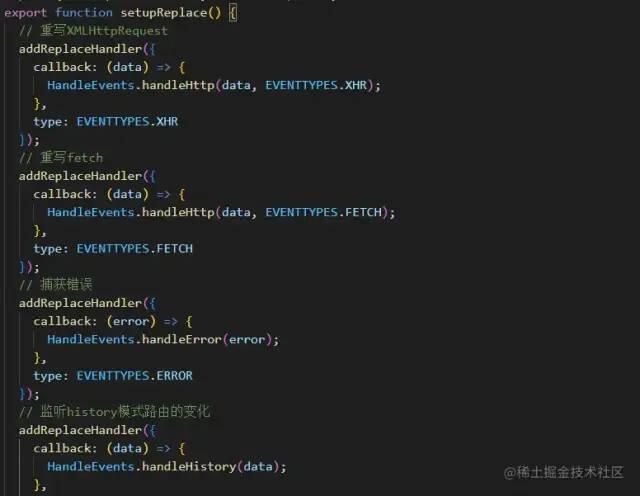
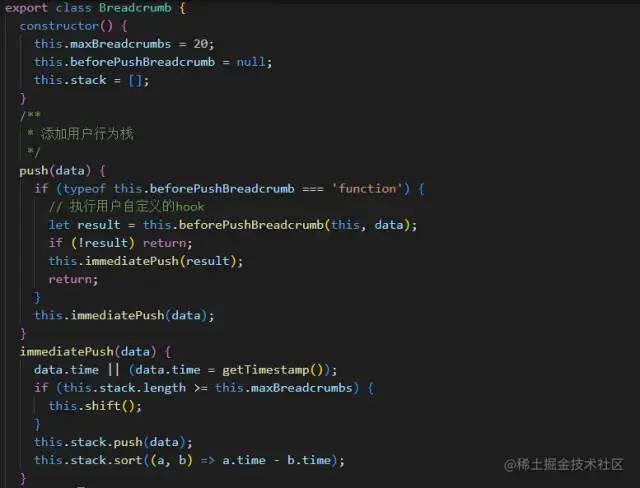
用户行为收集
创建用户行为类,stack用来存储用户行为,当长度超过限制时,最早的一条数据会被覆盖掉,在上报错误时,对应的用户行为会添加到该错误信息中
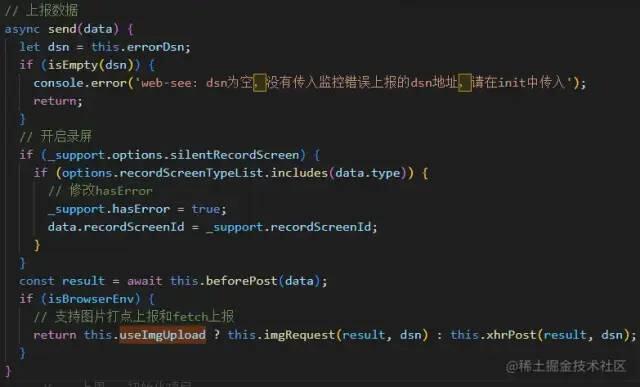
数据上报方式
支持图片打点上报和fetch请求上报两种方式
图片打点上报的优势: 1)支持跨域,一般而言,上报域名都不是当前域名,上报的接口请求会构成跨域 2)体积小且不需要插入dom中 3)不需要等待服务器返回数据
图片打点缺点是:url受浏览器长度限制
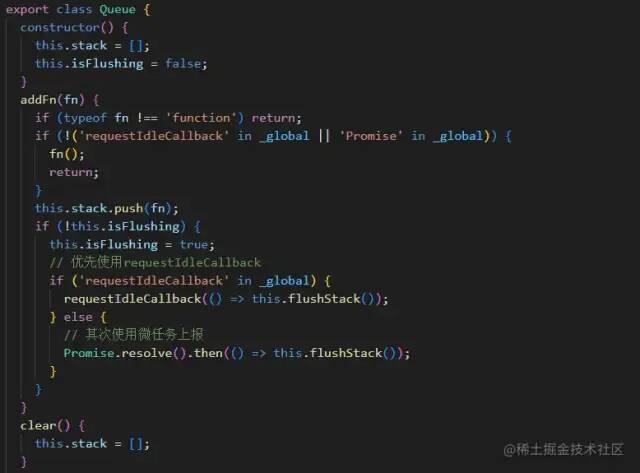
数据上报时机
优先使用 requestIdleCallback,利用浏览器空闲时间上报,其次使用微任务上报
监控SDK,参考了 sentry、 monitor、 mitojs
项目后台demo
主要用来演示错误还原功能,方式包括:定位源码、播放录屏、记录用户行为

后台demo功能介绍:
1、使用 express 开启静态服务器,模拟线上环境,用于实现定位源码的功能
2、server.js 中实现了 reportData(错误上报)、getmap(获取 map 文件)、getRecordScreenId(获取录屏信息)、 getErrorList(获取错误列表)的接口
3、用户可点击 'js 报错'、'异步报错'、'promise 错误' 按钮,上报对应的代码错误,后台实现错误还原功能
4、点击 'xhr 请求报错'、'fetch 请求报错' 按钮,上报接口报错信息
5、点击 '加载资源报错' 按钮,上报对应的资源报错信息
通过这些异步的捕获,了解监控平台的整体流程
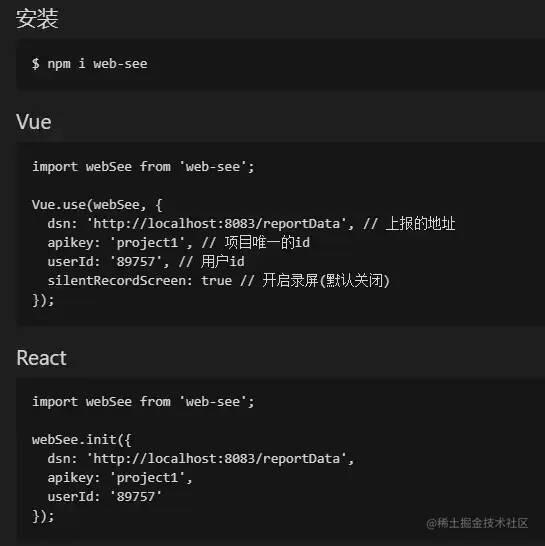
安装与使用
npm官网搜索 web-see[11]
仓库地址
监控SDK: web-see[12]
监控后台: web-see-demo[13]
总结
目前市面上的前端监控方案可谓是百花齐放,但底层原理都是相通的。从基础的理论知识到实现一个可用的监控平台,收获还是挺多的
有兴趣的小伙伴可以结合git仓库的源码玩一玩,再结合本文一起阅读,帮助加深理解
