
来源:深度之眼 作者:摸奖成功
编辑:学姐
Google Brain - Ventilator Pressuren Prediction

01 背景信息与数据初探
呼吸机的气压作用?
呼吸机将气压打入患者佩戴的口鼻罩中,有助于防止呼吸道塌陷
呼吸机气压过低会怎样?
氧气没办法压入患者的身体,吸气困难
呼吸机气压过高会怎样?
患者没办法吐气,呼气困难
赛题解读:
根据背景信息,因为呼吸机气压过高过低都不行,所以要用机器预测气压变化曲线,然后人为预先调整,不然人都凉了。
评价指标是平均绝对误差|x-y|
赛题数据:
时长为3s;有两个控制信号;产生的气道压力和肺的相关属性。
Discussion(官网):
https://www.kaggle.com/dmitryuarov/ventilator-pressure-eda-lstm-0-189
数据介绍:
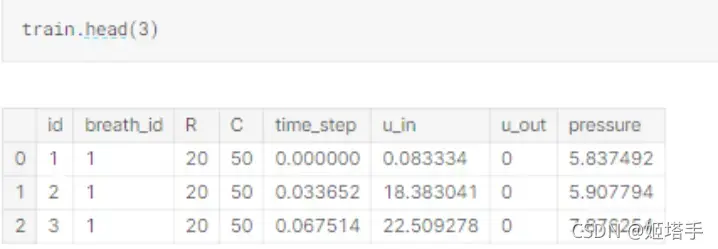
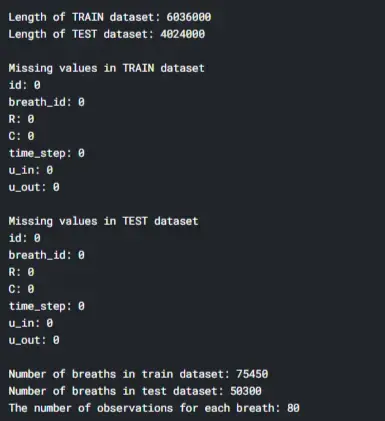
02 赛题解析
本次比赛中使用的呼吸机数据是通过一个呼吸回路连接到一个人工风箱测试肺的改良开源呼吸机产生的。
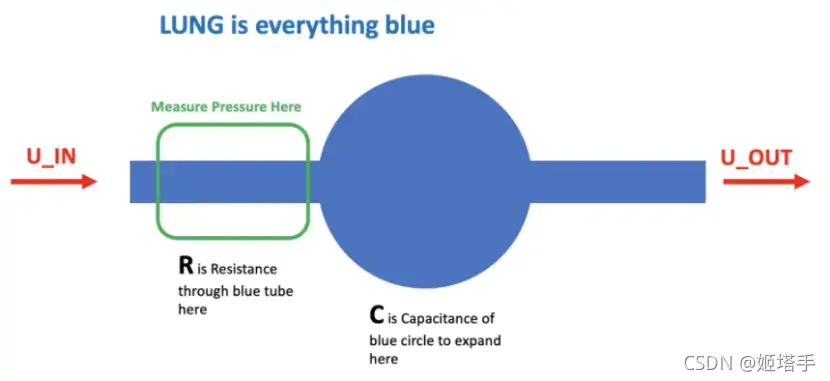
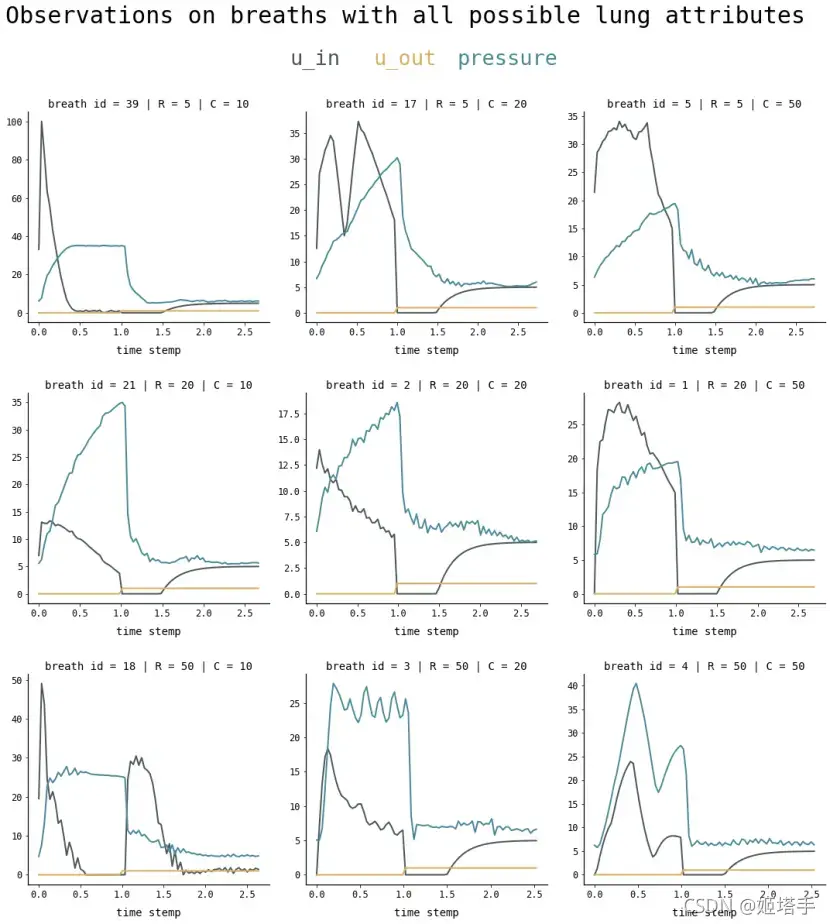
下图展示了设置,两个控制输入用绿色突出显示,要预测的状态变量(气道压力)用蓝色显示。
第一个控制输入是一个从0到100的连续变量,代表吸气电磁阀打开以让空气进入肺的百分比(即,0完全关闭,没有空气进入,100完全打开)。
第二个控制输入是一个二进制变量,表示探索性阀门是开启(1)还是关闭(0)以排出空气。
在这个比赛中,参与者将被给予无数次时间序列的呼吸,并将学习在给定控制输入的时间序列的情况下,预测呼吸过程中呼吸回路中的气道压力。每个时间序列代表大约3秒的呼吸。
这些文件被组织起来,每一行都是呼吸中的一个时间步骤,并给出两个控制信号,由此产生的气道压力和肺的相关属性,如下所述。

代码包👉 【私信“比赛君”,回复“呼吸机”+小助理领取baseline】

03 数据介绍

Id -在整个文件中全局唯一的时间步骤标识符
Breath_id -全局唯一的呼吸时间步长
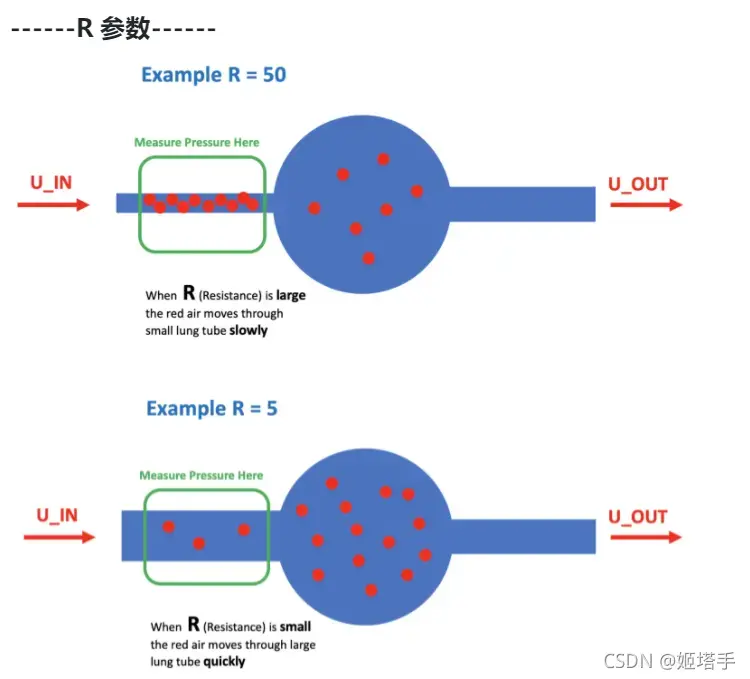
R -指示气道受限程度的肺属性(cmH2O/L/S)
物理上,这是每流量变化的压力变化(每时间的空气体积)。凭直觉,我们可以想象用一根吸管吹气球。我们可以通过改变吸管的直径来改变R, R越大吹起来越难。
R越大,肺吸气的难度越大,需要呼吸机的压力越大,所以这个指标特征融合后依旧需要
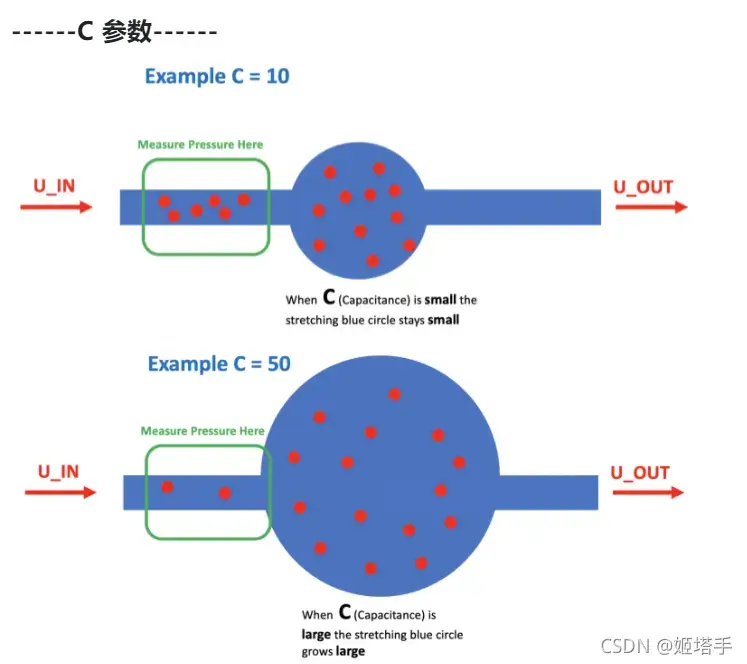
C -肺属性,指示肺顺应性(以mL/cmH2O表示)。物理上,这是体积变化除以压强变化。我们可以直观地想象同样的气球例子。我们可以通过改变气球乳胶的厚度来改变C, C越高,乳胶越薄,越容易吹气。
C越大,类比为乳胶越薄,肺吸气的难度越小,需要呼吸机的压力越小。
所以这个指标特征融合后依旧需要。
Time_step—实际的时间戳
U_in吸气电磁阀的控制输入。取值范围为0 ~ 100
U_out -探索性电磁阀的控制输入。0或者1
Pressure-在呼吸回路中测量的气道压力,以cmH2O计
蓝线是所有的u_in时间序列。注意它们是如何相似的。红线是所有时间序列的压力C=10。橙色线是带有 的压力C=20。黄线是压力与C=50。
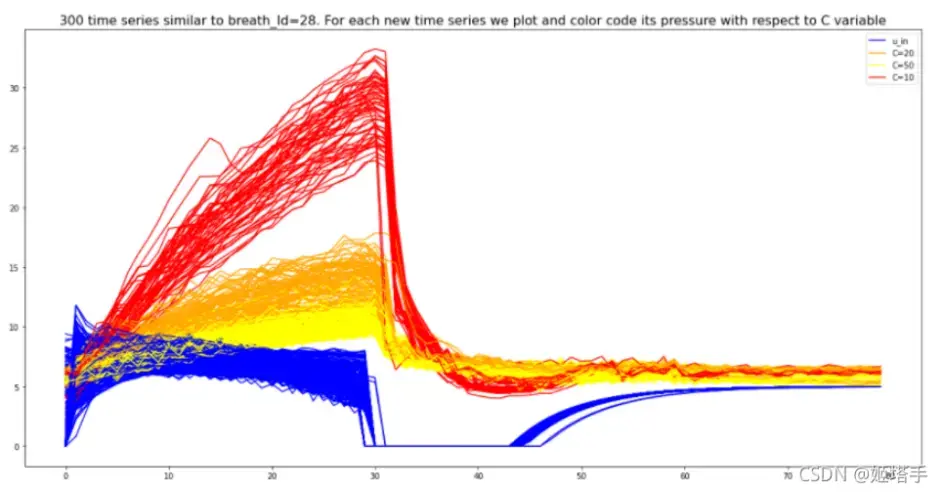
横坐标:Breath_id 0-80 总共为3s
纵坐标:压力
图片解释:蓝色的线:输入的压力——相同压力,C越大(黄线C大,对应的压力越小),乳胶越薄,纵坐标是越容易吸气
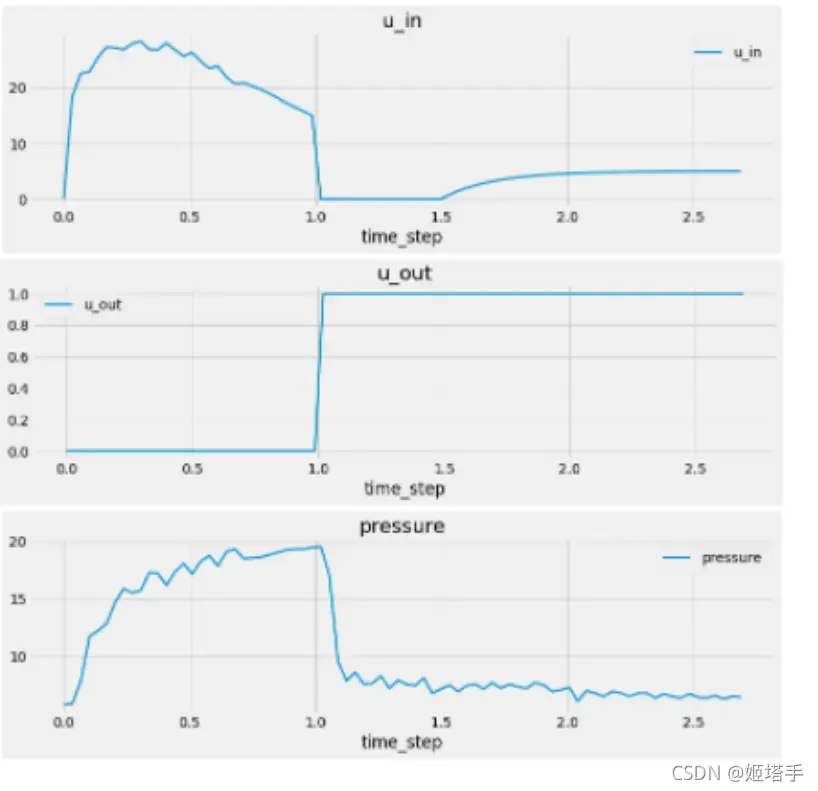
变量C是顺应性,表示拉伸气球(肺)的难易程度。最大值C=50是最容易拉伸的。
如果我们将空气输入一个容易伸展的气球,压力不会增加,因为气球只会变大(因此每个空间的空气不会增加)。如果我们将空气输入到不容易拉伸C=10的气球( ) 中,气球会保持相同的大小,但会在里面获得更多的空气(因此压力增加)。
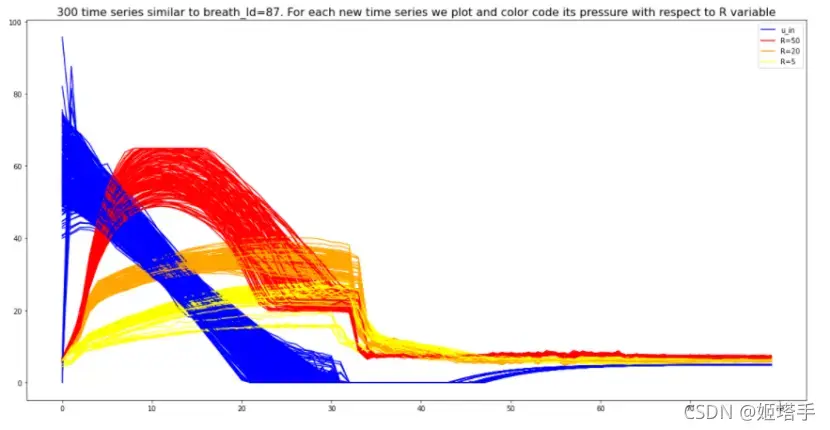
变量R是阻力,表示空气进入然后“退出”气球的容易程度。(实际上只是四处走动,因为在吸气期间出口是关闭的)。最大值R=50具有最大的阻力。如果我们将空气输入到具有高阻力的气球中,空气会“留在里面”并增加压力。
这可以在下面的图中看到,它是 300 个时间序列,类似于breath_id = 87按参数 颜色编码R。(红色是R=50,橙色是R=20,黄色是R=5)如果我们输入一个尖峰(快速输入)空气,那么R压力上升大的气球(肺)很快,而小气球(肺)则R很容易观察到空气“通过”并且不要迅速升高压力。
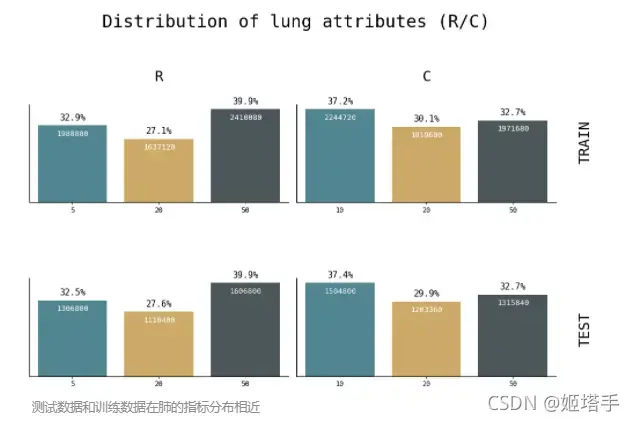
RC在训练集测试集上的分布
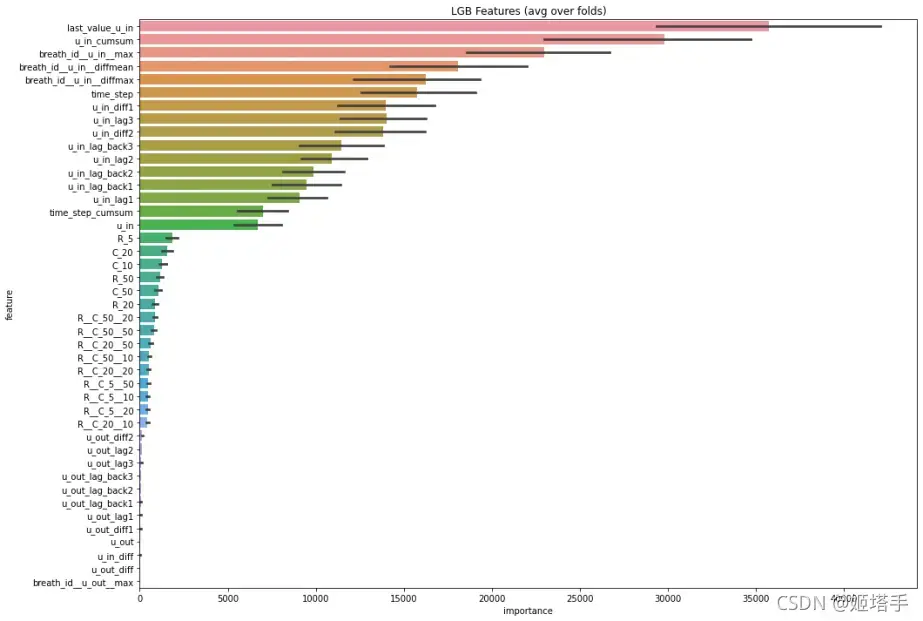
特征工程
04 baseline解读
https://www.kaggle.com/dlaststark/gb-vpp-whoppity-dub-dub/notebook
制作特征组合
def add_features(df):
df['cross']= df['u_in'] * df['u_out']
df['cross2']= df['time_step'] * df['u_out']
df['area'] = df['time_step'] * df['u_in']
df['area'] = df.groupby('breath_id')['area'].cumsum()
df['time_step_cumsum'] = df.groupby(['breath_id'])['time_step'].cumsum()
df['u_in_cumsum'] = (df['u_in']).groupby(df['breath_id']).cumsum()
print("Step-1...Completed")
df
['u_in_lag1'] = df.groupby('breath_id')['u_in'].shift(1)
df['u_out_lag1'] = df.groupby('breath_id')['u_out'].shift(1)
df['u_in_lag_back1'] = df.groupby('breath_id')['u_in'].shift(-1)
df['u_out_lag_back1'] = df.groupby('breath_id')['u_out'].shift(-1)
df['u_in_lag2'] = df.groupby('breath_id')['u_in'].shift(2)
df['u_out_lag2'] = df.groupby('breath_id')['u_out'].shift(2)
df['u_in_lag_back2'] = df.groupby('breath_id')['u_in'].shift(-2)
df['u_out_lag_back2'] = df.groupby('breath_id')['u_out'].shift(-2)
df['u_in_lag3'] = df.groupby('breath_id')['u_in'].shift(3)
df['u_out_lag3'] = df.groupby('breath_id')['u_out'].shift(3)
df['u_in_lag_back3'] = df.groupby('breath_id')['u_in'].shift(-3)
df['u_out_lag_back3'] = df.groupby('breath_id')['u_out'].shift(-3)
df['u_in_lag4'] = df.groupby('breath_id')['u_in'].shift(4)
df['u_out_lag4'] = df.groupby('breath_id')['u_out'].shift(4)
df['u_in_lag_back4'] = df.groupby('breath_id')['u_in'].shift(-4)
df['u_out_lag_back4'] = df.groupby('breath_id')['u_out'].shift(-4)
df = df.fillna(0)
print("Step-2...Completed")
df
['breath_id__u_in__max'] = df.groupby(['breath_id'])['u_in'].transform('max')
df['breath_id__u_in__mean'] = df.groupby(['breath_id'])['u_in'].transform('mean')
df['breath_id__u_in__diffmax'] = df.groupby(['breath_id'])['u_in'].transform('max') - df['u_in']
df['breath_id__u_in__diffmean'] = df.groupby(['breath_id'])['u_in'].transform('mean') - df['u_in']
print("Step-3...Completed")
df
['u_in_diff1'] = df['u_in'] - df['u_in_lag1']
df['u_out_diff1'] = df['u_out'] - df['u_out_lag1']
df['u_in_diff2'] = df['u_in'] - df['u_in_lag2']
df['u_out_diff2'] = df['u_out'] - df['u_out_lag2']
df['u_in_diff3'] = df['u_in'] - df['u_in_lag3']
df['u_out_diff3'] = df['u_out'] - df['u_out_lag3']
df['u_in_diff4'] = df['u_in'] - df['u_in_lag4']
df['u_out_diff4'] = df['u_out'] - df['u_out_lag4']
print("Step-4...Completed")
df
['one'] = 1
df['count'] = (df['one']).groupby(df['breath_id']).cumsum()
df['u_in_cummean'] =df['u_in_cumsum'] /df['count']
df
#让breath_id向右移动一位['breath_id_lag']=df['breath_id'].shift(1).fillna(0)
df
#让breath_id向右移动两位['breath_id_lag2']=df['breath_id'].shift(2).fillna(0)
df
['breath_id_lagsame']=np.select([df['breath_id_lag']==df['breath_id']],[1],0)
df['breath_id_lag2same']=np.select([df['breath_id_lag2']==df['breath_id']],[1],0)
df['breath_id__u_in_lag'] = df['u_in'].shift(1).fillna(0)
df['breath_id__u_in_lag'] = df['breath_id__u_in_lag'] * df['breath_id_lagsame']
df['breath_id__u_in_lag2'] = df['u_in'].shift(2).fillna(0)
df['breath_id__u_in_lag2'] = df['breath_id__u_in_lag2'] * df['breath_id_lag2same']
print("Step-5...Completed")
df
['time_step_diff'] = df.groupby('breath_id')['time_step'].diff().fillna(0)
df['ewm_u_in_mean'] = (
df\.groupby('breath_id')['u_in']
\.ewm(halflife=9)
\.mean()
\.reset_index(level=0,drop=True))
df[["15_in_sum","15_in_min","15_in_max","15_in_mean"]] = (
df\.groupby('breath_id')['u_in']
\.rolling(window=15,min_periods=1)
\.agg({"15_in_sum":"sum",
"15_in_min":"min",
"15_in_max":"max",
"15_in_mean":"mean"})
\.reset_index(level=0,drop=True))
print("Step-6...Completed")
df
['u_in_lagback_diff1'] = df['u_in'] - df['u_in_lag_back1']
df['u_out_lagback_diff1'] = df['u_out'] - df['u_out_lag_back1']
df['u_in_lagback_diff2'] = df['u_in'] - df['u_in_lag_back2']
df['u_out_lagback_diff2'] = df['u_out'] - df['u_out_lag_back2']
print("Step-7...Completed")
df
['R'] = df['R'].astype(str)
df['C'] = df['C'].astype(str)
df['R__C'] = df["R"].astype(str) + '__' + df["C"].astype(str)
df = pd.get_dummies(df)
print("Step-8...Completed")
return
df
print("Train data...\n")
train = add_features(train_df)
print("\nTest data...\n")
test = add_features(test_df)
gc
del test_df
del train_df
.collect()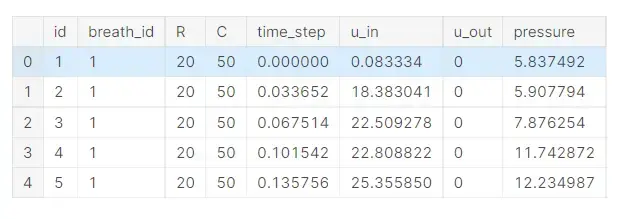
Google Brain - Ventilator Pressure Prediction:
https://www.kaggle.com/c/ventilator-pressure-prediction/discussion/276828
可能有些特征贡献比较小,所以去掉了,但是因为传感器位于末端,存在滞后性,就应该移位。
train需要去掉标签,去掉呼吸机的id
train['u_in_lag'] = train['u_in'].shift(2)
train = train.fillna(0)
test
['u_in_lag'] = test['u_in'].shift(2)
test = test.fillna(0)#让breath_id向右移动一位
df['breath_id_lag']=df['breath_id'].shift(1).fillna(0)
#让breath_id向右移动两位
df['breath_id_lag2']=df['breath_id'].shift(2).fillna(0)
#筛选移位后和未移位一样的id
df['breath_id_lagsame']=np.select([df['breath_id_lag']==df['breath_id']],[1],0)
df['breath_id_lag2same']=np.select([df['breath_id_lag2']==df['breath_id']],[1],0)
targets = train[['pressure']].to_numpy().reshape(-1, 80)
train
.drop(['pressure','id', 'breath_id','one','count',
'breath_id_lag','breath_id_lag2','breath_id_lagsame',
'breath_id_lag2same'], axis=1, inplace=True)
test
= test.drop(['id', 'breath_id','one','count','breath_id_lag',
'breath_id_lag2','breath_id_lagsame',
'breath_id_lag2same'], axis=1)
print(f"train: {train.shape} \ntest: {test.shape}")求这几个量在干嘛?
pressure = targets.squeeze().reshape(-1,1).astype('float32')
P_MIN = np.min(pressure)
P_MAX = np.max(pressure)
P_STEP = (pressure[1] - pressure[0])[0]
print('Min pressure: {}'.format(P_MIN))
print('Max pressure: {}'.format(P_MAX))
print('Pressure step: {}'.format(P_STEP))
print('Unique values: {}'.format(np.unique(pressure).shape[0]))
gc
del pressure
.collect()Min pressure: -1.8957443237304688
Max pressure: 64.82099151611328
Pressure step: 0.07030248641967773
Unique values: 950
63
模型定义
def dnn_model():
x_input
= Input(shape=(train.shape[-2:]))
x1
= Bidirectional(LSTM(units=768, return_sequences=True))(x_input)
x2 = Bidirectional(LSTM(units=512, return_sequences=True))(x1)
x3 = Bidirectional(LSTM(units=256, return_sequences=True))(x2)
z2
= Bidirectional(GRU(units=256, return_sequences=True))(x2)
z3 = Bidirectional(GRU(units=128, return_sequences=True))(Add()([x3, z2]))
x
= Concatenate(axis=2)([x3, z2, z3])
x = Bidirectional(LSTM(units=192, return_sequences=True))(x)
x
= Dense(units=128, activation='selu')(x)
x_output
= Dense(units=1)(x)
model
= Model(inputs=x_input, outputs=x_output,
name ='DNN_Model')
return model
with tpu_strategy.scope():
VERBOSE = 0
test_preds = []
kf = KFold(n_splits=7, shuffle=True, random_state=2021)
for fold, (train_idx, test_idx) in enumerate(kf.split(train, targets)):
X_train, X_valid = train[train_idx], train[test_idx]
y_train, y_valid = targets[train_idx], targets[test_idx]
model
= dnn_model()
model.compile(optimizer="adam", loss="mae")
lr
= ReduceLROnPlateau(monitor="val_loss", factor=0.75,
patience =10, verbose=VERBOSE)
save_locally
= tf.saved_model.SaveOptions(experimental_io_device='/job:localhost')
chk_point = ModelCheckpoint(f'./Bidirect_LSTM_model_{fold+1}C.h5', options=save_locally,
monitor ='val_loss', verbose=VERBOSE,
save_best_only =True, mode='min')
es
= EarlyStopping(monitor="val_loss", patience=50,
verbose =VERBOSE, mode="min",
restore_best_weights =True)
model
.fit(X_train, y_train,
validation_data =(X_valid, y_valid),
epochs =300,
verbose=VERBOSE,
batch_size=BATCH_SIZE,
callbacks =[lr, chk_point, es])
load_locally
= tf.saved_model.LoadOptions(experimental_io_device='/job:localhost')
model = load_model(f'./Bidirect_LSTM_model_{fold+1}C.h5', options=load_locally)
y_true
= y_valid.squeeze().reshape(-1, 1)
y_pred = model.predict(X_valid, batch_size=BATCH_SIZE).squeeze().reshape(-1, 1)
score = mean_absolute_error(y_true, y_pred)
print(f"Fold-{fold+1} | OOF Score: {score}")
test_preds
.append(model.predict(test, batch_size=BATCH_SIZE).squeeze().reshape(-1, 1).squeeze())2021-10-12 09:11:04.581550: W tensorflow/core/framework/cpu_allocator_impl.cc:80] Allocation of 1324462080 exceeds 10% of free system memory.
Fold-1 | OOF Score: 0.16112606056581755
2021-10-12 09:55:45.931863: W tensorflow/core/framework/cpu_allocator_impl.cc:80] Allocation of 1030144000 exceeds 10% of free system memory.
2021-10-12 09:56:13.009091: W tensorflow/core/framework/cpu_allocator_impl.cc:80] Allocation of 1324462080 exceeds 10% of free system memory.
Fold-2 | OOF Score: 0.16258001095851782
2021-10-12 10:45:27.179649: W tensorflow/core/framework/cpu_allocator_impl.cc:80] Allocation of 1030144000 exceeds 10% of free system memory.
2021-10-12 10:45:49.792617: W tensorflow/core/framework/cpu_allocator_impl.cc:80] Allocation of 1324462080 exceeds 10% of free system memory.
Fold-3 | OOF Score: 0.16502696102577724
Fold-4 | OOF Score: 0.1614873964707711
Fold-5 | OOF Score: 0.16390962046846733
Fold-6 | OOF Score: 0.16005591422945886
Fold-7 | OOF Score: 0.1603692169639012
选择五个模型取平均值
submission = pd.read_csv('../input/ventilator-pressure-prediction/sample_submission.csv')
submission["pressure"] = sum(test_preds)/5
submission.to_csv('mean_submission.csv', index=False)取中间数
submission["pressure"] = np.median(np.vstack(test_preds),axis=0)
submission["pressure"] = np.round((submission.pressure - P_MIN)/P_STEP) * P_STEP + P_MIN
submission["pressure"] = np.clip(submission.pressure, P_MIN, P_MAX)
submission.to_csv('median_submission.csv', index=False)👇🏻 添加助理领取呼吸机Baseline👇🏻
