
最近美术想了一个需求,想要实现全屏同时播放上千个粒子系统。这个需求确实挺疯狂的,因为对于CPU粒子来说,改动很大;而对于GPU粒子来说基本不可能(?)。老大对于这个需求非常质疑,我本人倒是很感兴趣,在寻找渲染实例化对象的实例化的(InstancedBaseInstance)方法的时候,发现高版本openGL的很多有意思的地方。在本文,总结一下高版本openGL draw call的类型。还是之前的结论,在不考虑设备兼容性问题的时候,openGL简直无敌,要啥有啥。
封面图来自Daniel Rákos 的GPU based dynamic geometry LOD
Direct rendering
Direct rendering和其他drawcall类型最显著的区别,就是Direct rendering的所有数据都是从CPU传来的,而其他的渲染方式都有数据是从openGl object(GPU)传来。
Basic Drawing

Multi-Draw
创建或者修改VAO都是一个很费的操作,因此有了这个功能,在一个VAO中存储多个mesh,然后批量绘制(batch)

实际上相当于
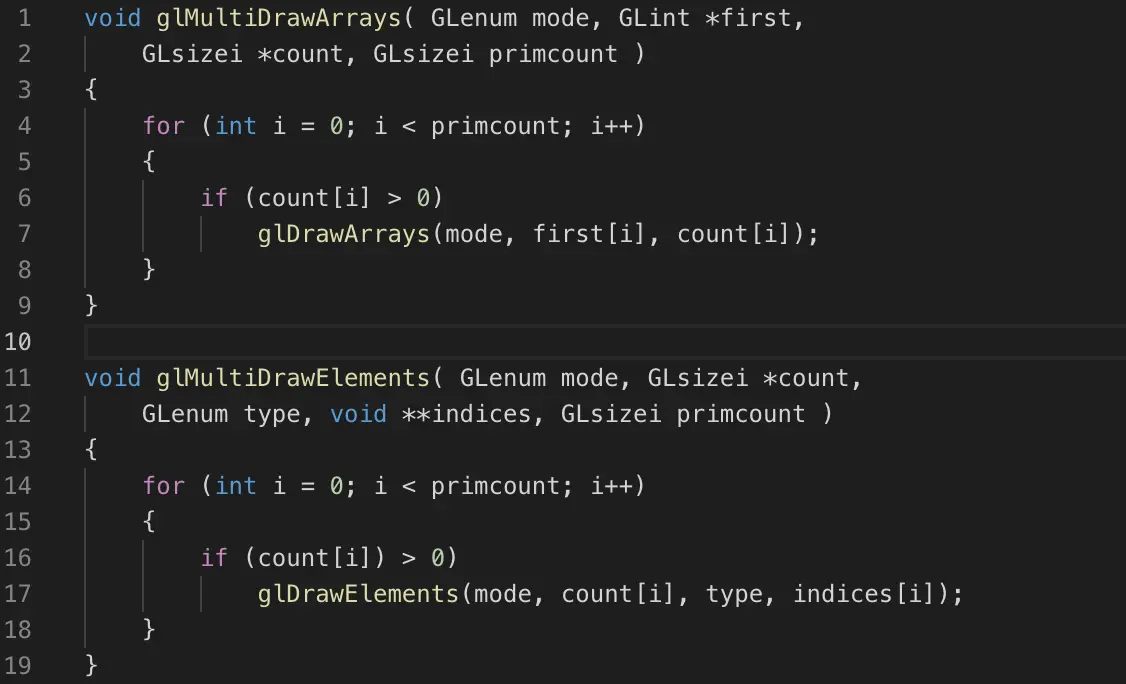
Multi-Draw所有物体使用相同材质
Base Index
将多个模型存在同一个VBO中,如下所示
[A00 A01 A02 A03 A04... Ann B00 B01 B02... Bmm]
glDrawArrays的话指定start index和count就能画出指定的模型了,glDrawElements却存在一些小问题,就是B的索引并非m,而是m + nn。调整一下其实没多麻烦,但openGL还是提供了接口,可以选择一个basevertex作为索引基础(nn),其他的索引自动加上这个basevertex的索引

Instancing
这个应该都很熟悉了,不多介绍了
void glDrawArraysInstanced( GLenum mode, GLint first,
GLsizei count, GLsizei instancecount );void glDrawElementsInstanced( GLenum mode, GLsizei count,
GLenum type, const void *indices, GLsizei instancecount );
gl_InstanceID还有Instanced_Array是实例之间的唯一差距。

在 openGL 4.2 版本或者支持扩展 ARB_base_instance,实例化的实例化已经成为可能!

gl_InstanceID不随baseinstance变化,因此每实例差异只能靠Instanced_Array来实现。在 openGL 4.6 或者 ARB_shader_draw_parameters扩展的情况下,可以通过gl_BaseInstance访问函数中的baseinstance参数
Range
“Range”版本的glDrawElements也用来处理多个模型存储在同一个VBO的情况,但是不会有索引数组越界的错误

Combinations
Combinations和openGL的primitive restart特性紧密相关。
Base vertex可以和MultiDraw, Range, 或 Instancing结合
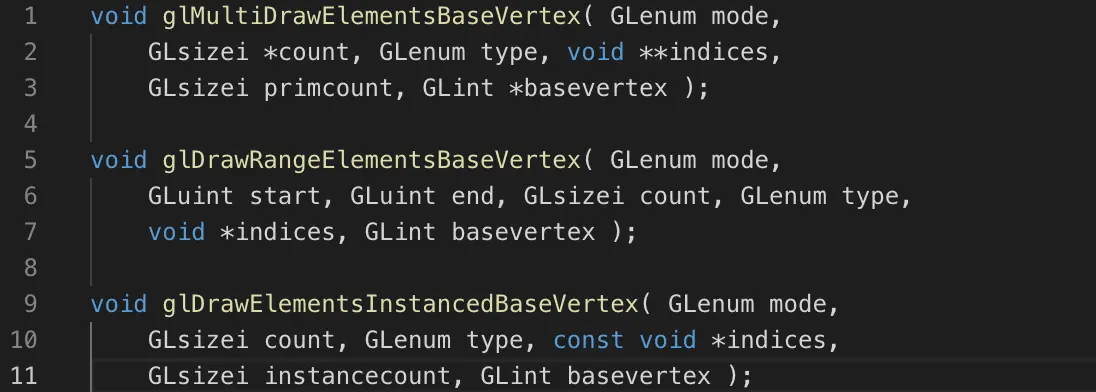
在openGL 4.2版本或者ARB_base_instance,BaseVertex 也能和 BaseInstance 结合

Transform feedback rendering
可以使用Transform Feedback来生成顶点信息用于渲染。通常的数据流程是GPU->CPU->GPU,但有一些API允许在CPU读取确切数据之前直接绘制。

在 openGL 4.2版本或者支持ARB_transform_feedback_instanced 的设备上,上述两个函数的实例化版本也可以使用

Indirect rendering
该特性的目的是允许直接渲染GPU中的数据,省去GPU->CPU->GPU的拷贝过程。运行时数据来源可能是Compute Shader,也可能是Geometry Shader + Transform Feedback,甚至可能是openCL/CUDA。
所有Indirect rendering都适用于下列情况:
Indexed rendering
Base vertex (for indexed rendering)
Instanced rendering
Base instance (if OpenGL 4.2 or ARB_base_instance is available). Does not require rendering more than one instance

此函数功能上等价于
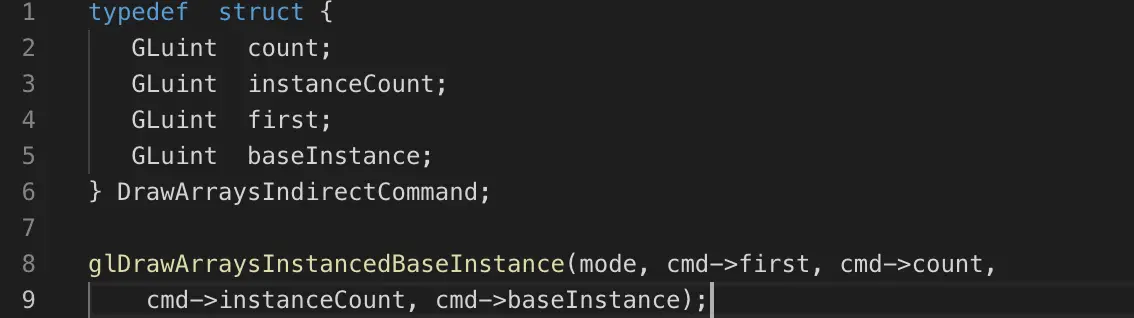
在openGL 4.3或者ARB_multi_draw_indirect扩展下,也可以用于multi draw

对于索引渲染

在功能上等价于
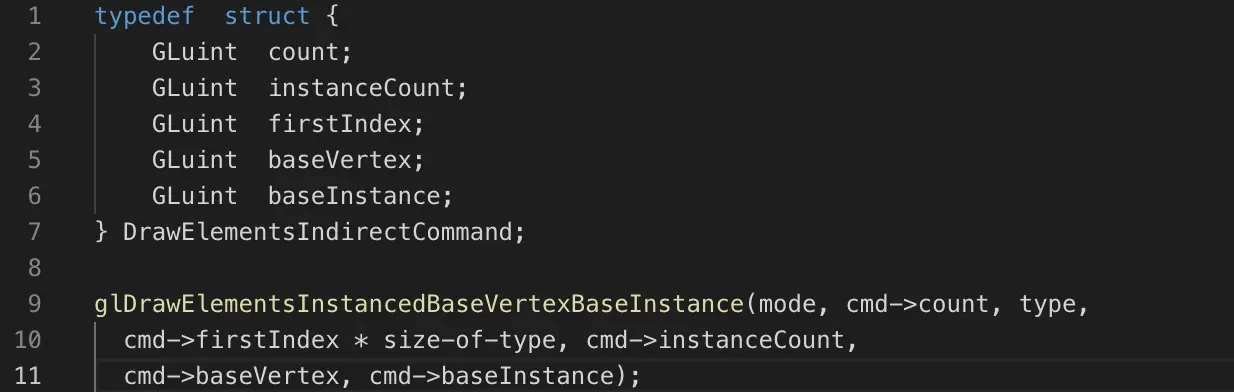
在openGL 4.3或者ARB_multi_draw_indirect扩展下,也可以用于multi draw

Conditional rendering
条件渲染就是只在某些条件下渲染,在某些条件下就不渲染。最经典的运用就是Occlusion Query。

支持的命令如下
Every function previously mentioned. IE, all functions of the form
glDraw*orglMultiDraw*.glClearandglClearBuffer.glDispatchComputeandglDispatchComputeIndirect.
参数中mode可以是如下选项:
GL_QUERY_WAIT: OpenGL will wait until the query result is returned, then decide whether to execute the rendering command. This ensures that the rendering commands will only be executed if the query fails. Note that it is OpenGL that’s waiting, not (necessarily) the CPU.
GL_QUERY_NO_WAIT: OpenGL may execute the rendering commands anyway. It will not wait to see if the query test is true or not. This is used to prevent pipeline stalls if the time between the query test and the execution of the rendering commands is too short.
GL_QUERY_BY_REGION_WAIT: OpenGL will wait until the query result is returned, then decide whether to execute the rendering command. However, the rendered results will be clipped to the samples that were actually rasterized in the occlusion query. Thus, the rendered result can never appear outside of the occlusion query area.
GL_QUERY_BY_REGION_NO_WAIT: As above, except that it may not wait until the occlusion query is finished. The region clipping still holds.