
11.1 迁移学习
本节课ppt:https://c.d2l.ai/stanford-cs329p/_static/pdfs/cs329p_slides_14_1.pdf
==========================================================================
迁移学习是干嘛的呢

00:04
能在一个任务上学习一个模型,然后用其来解决相关的别的任务,这样我们在一个地方花的时间,学习的一些知识,研究的一些看法可以在另外一个地方被使用到;
迁移学习是在深度学习出圈的,因为在深度学习中需要训练很多的深层神经网络,需要很多的数据,代价也很高;
迁移学习的途径:
做好一个模型将其做成一个特征提取的模块(Word2Vec【在文本上做训练一个单层神经网络,在训练好之后,每一个词对应一个特征,然后用这个特征去别的事情】,ResNet【对图片做特征,然后用这个特征来对作为另一个模型的输入,这样假设效果非常好,那么就可以代替人工去抽取特征】,I3D【用来对视频做特征】);
在一个相关的任务上训练一个模型,然后在另一个任务上直接用它;(之后的单元会讲到)
训练好一个模型,然后在一个新的任务上对其做微调,使模型能更好的适应新的任务;
相关的领域:
半监督学习:利用没有标号的数据,让有标号的数据变得好
在极端的条件下,可以做zero-shot(一个任务有很多的类别但不会告诉你样本)或few-shot(一个任务就给你一些样本) learning。
Multi-task learning(多任务学习):每一个任务都有它自己的数据,但是数据不是很够,可是任务之间相关,那么可以将所有的数据放在一起,然后同时训练多个任务出来,这样我们希望能从别的任务之中获益
==========================================================================
在计算机视觉中的应用
转移知识:

03:58
在CV中存在了很多大规模标好的数据集(特别是分类问题,因为标号容易);
在CV的迁移学习,我们是希望存在 很多数据的一些应用上比较好的模型,能将它的知识拓展到我们自己的任务上去;
通常你自己任务的数据集会比大的数据集(ImageNet)要小很多(一开始不会花太多钱去标注很多的数据,正常是,标好了一些看看模型效果怎么样,然后好的话再继续投入进去,这样是一个迭代的过程),然后我们想要快速的迭代,看看能不能用比较大的数据集来将一些学到的东西迁移到我们自己的任务上面去;
==========================================================================
预训练模型(转移知识的办法之一):
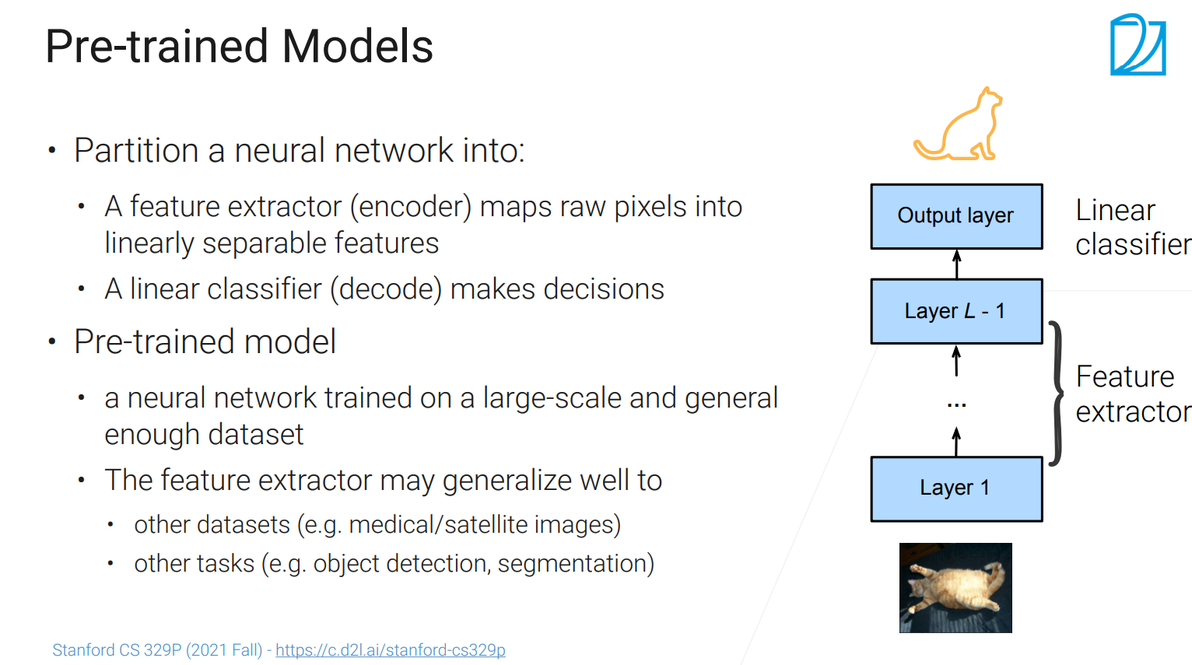
07:02
可以将神经网络分成两块,一块编码器(特征提取器,将原始图片的原始像素转化在一个语义空间中可以线性可分的一些特征(浅表示或语义特征表示)),一块解码器(简单的线性分类器,将编码器的表示映射成想要的标号,或者做一些决策);
预训练模型(Pre-train):在一个比较大的数据上训练好的一个模型,会具有一定的泛化能力(放到新模型上或新的数据集上,这个模型还是有效果的)【虽然是用于图片分类但是也可以试试目标检测】;
==========================================================================
微调(fine-tunning):
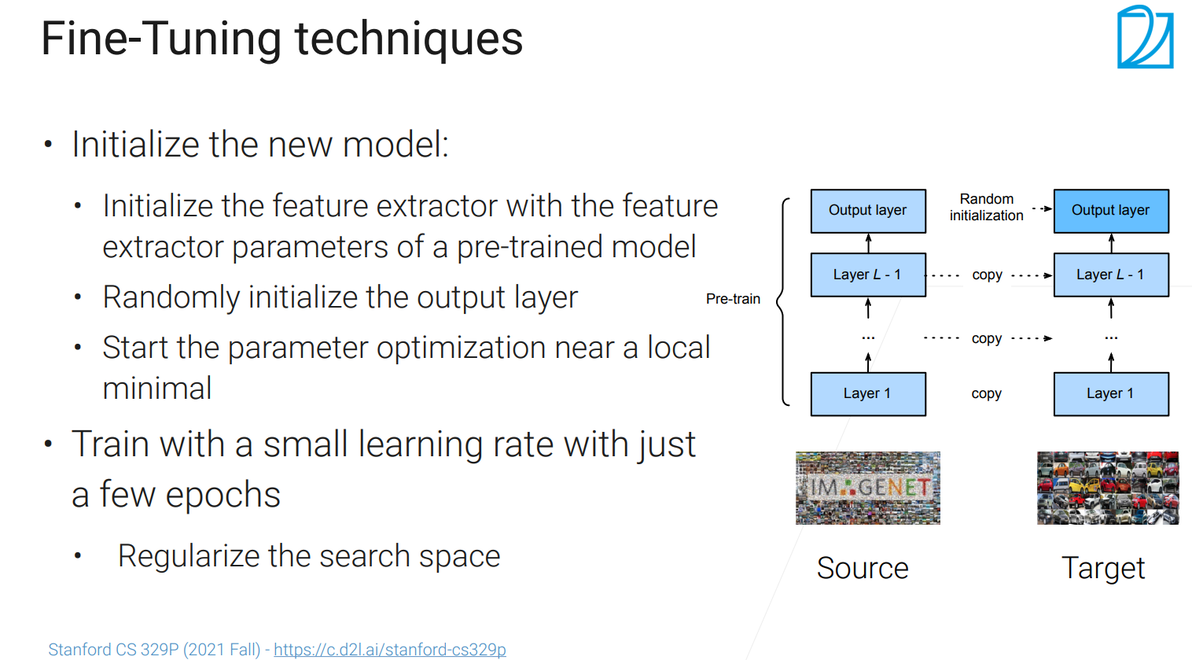
11:14
将预训练好的模型用在新任务上叫fine-tuning(微调)【通常在深度学习里面,微调能带来最好的效果,但是也有一定的开销】
微调是怎么做的:
在新的任务上构建一个新的模型,新的模型的架构要更预训练的模型的架构是一样的;
在找到合适的预训练模型之后要初始化我们的模型(将预训练模型的除了最后一层之外(特征提取器)的权重都复制给我们的模型,最后一层的解码器用的还是随机的权重【因为我们的标号和预训练模型的标号是不一样的】);
具体看例子13:30
在初始化之后,就可以开始学习了,这步跟我们平常的学习没有什么不同的;
有一点点小做法是,限制fine-tune后的学习率。因为我们初始的结果已经比较好了,已经在想要解的附近了,限制学习率可以使得我们可以不会走太远【一般是用1e-3】;另外是说不要训练太长的时间;这些做法都是为了缩小搜索空间;
限制搜索空间的原因:
16:18
==========================================================================
限制搜索空间的其他方法——固定最底层:

18:15
神经网络通常有一个层次化的,最底层一般是学习了底层的特征,上层的更与语义相关,所以一般来说底层与上面层没有太多的关系,在换了数据集之后泛化性都很好;
最后一层还是随机初始化学习,然后只对某一些层进行改动,最下面那些层在微调时就不去动了(可以说是学习率为0);
固定住多少层是要根据应用来看的,假设应用与预训练模型差别比较大的话,可以多训练一些层;
==========================================================================
怎么去找微调模型:
21:45
首先要去找有没有我们想要的预训练模型,然后是看它是在什么样的数据集上训练好的;
可以去的途径(ModelHub、ModelZoom之类的):
Tensorflow Hub: https://tfhub.dev/;(允许用户去提交模型)
TIMM(把pytorch上能找到的各种代码实现弄过来): https://github.com/rwightman/pytorch-image-models;(ross 自己维护的一个包【文档不错,模型性能暂时一般般】)
TIMM使用代码介绍:
23:29
==========================================================================
fine-tuning的一些应用:

25:07
在大的数据集上训练好模型再微调到自己的应用上在CV领域上广泛的应用;
新的任务包含 目标检测、语义分割等(图片类似但是目标不一样);
在医疗领域等(同样的任务但是图片大相径庭);
现在的观点是微调加速了收敛(微调让初始的点不再试一个随机的点而是一个离最终的目标比较近的点,使得损失比较平滑),但是不一定可以提升精度(一般不会让精度变低,因为它只是改变初始值而已,跟随机初始化没区别,只要走的足够远也能摆脱初始值的影响);
==========================================================================
总结:

29:03
通常我们会在大数据上训练预训练好的模型,这种任务通常是图片分类;
然后在关心的任务上把模型的权重初始化成预训练好的模型的权重,当然最后一层也就是解码器是要随机初始化的;
微调一般用一个小一点的学习率进行细微的调整,这样通常会加速收敛,有时可以提升精度但通常不会变差;(所以通常在CV中是经常被推荐的做法)
