作者:Junyi Ao, Rui Wang , Long Zhou , Shujie Liu, Shuo Ren, Yu Wu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei
机构:(1)Department of Computer Science and Engineering, Southern University of Science and Technology (2)Department of Computing, The Hong Kong Polytechnic University (3)Department of Computer Science and Technology, Tongji University
链接:https://arxiv.org/pdf/2110.07205.pdf

摘要
受 T5(Text-ToText Transfer Transformer)在预训练自然语言处理模型方面的成功启发,我们提出了一个统一模态 SpeechT5 框架,该框架探索了编码器解码器预训练以进行自监督语音/文本表示学习。 SpeechT5 框架由一个共享的编码器-解码器网络和六个特定于模态(语音/文本)的前/后网络组成。通过前置网络对输入的语音/文本进行预处理后,共享编码器-解码器网络对序列到序列的转换进行建模,然后后置网络基于解码器输出以语音/文本模态生成输出。特别是 SpeechT5 可以对大量未标记的语音和文本数据进行预训练,以提高语音和文本建模的能力。为了将文本和语音信息对齐到一个统一的语义空间,我们提出了一种随机混合的跨模态矢量量化方法来桥接语音和文本。对各种口语处理任务的广泛评估,包括语音转换、自动语音识别、文本到语音和说话人识别,显示了所提出的 SpeechT5 框架的优越性。

介绍
从 ELMo 和 BERT 开始,大量工作表明,预训练模型可以在各种任务中带来显着改进,包括自然语言处理 (NLP)、图像识别和语音处理。 通过在大量未标记数据上预训练具有自我监督任务的共享模型来学习通用表示,正在成为解决问题的新原理。 特别是,“Text-To-Text Transfer Transformer”(T5)利用统一的文本到文本框架,在各种 NLP 任务上取得了最先进的结果,包括机器翻译、问答、情感分类等等。 T5 的基本思想是将每个 NLP 问题视为“文本到文本”问题,并采用迁移学习来提升下游任务的性能。
同时,自监督的speech representation learning也得到了研究并显示出可喜的结果,这得益于丰富的学习表示形式。一部分优秀的成果,例如 WAV2vec2、APC、MPC 和 Hubert,被提出用来改进具有语音预训练的声学编码器。 另一些方法试图通过利用语音语言预训练来增强一些口语理解任务。
但是,这些模型中的大多数都依赖于类似于 BERT 的仅编码器模型,并且具有针对不同任务的特定于任务的模型架构。 如何设计一个统一的编码器-解码器模型,可以利用未标记的语音和文本数据来改进各种口语处理,还没有得到很好的探索。 受 T5 方法的启发,我们尝试通过编码器-解码器框架将每个口语处理任务转换为语音/文本到语音/文本问题,例如自动语音识别 (ASR)、文本到语音 (TTS)、 语音转换 (VC) 和说话人识别 (SID),如图 1 所示,这使我们能够在不同的任务中使用相同的预训练模型。
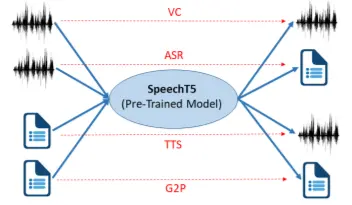
为了实现这一点,我们提出了 SpeechT5,一种用于口语处理任务的统一模态编码器-解码器预训练方法。 SpeechT5 包含一个编码器 - 解码器骨干网络和特定于模态的 pre-post 网络。 使用 pre-nets,输入语音/文本被嵌入到共享向量空间中,encoderdecoder 骨干网络对序列到序列的转换进行建模,模型特定的 post-nets 从中生成语音/文本输出。 SpeechT5 是通过利用大规模未标记文本和语音语料库的去噪序列到序列方法进行预训练的。 为了将文本和声学信息对齐到一个统一的语义空间中,所提出的 SpeechT5 模型 (1) 将文本和语音表示映射到一个共享的向量量化空间,以及 (2) 随机混合量化的潜在表示和上下文表示,这可以明确引导量化器学习跨模态信息。
我们在各种下游口语处理任务上微调 SpeechT5,包括 VC、ASR、TTS 和 SID。 广泛的结果表明,与强基线相比,所提出的 SpeechT5 模型在这些口语处理任务上取得了显着的改进。 具体而言,所提出的 SpeechT5 方法在 VC 任务上的表现优于最先进的语音转换器网络 (VTN),并达到了 90.97% 的最先进结果。 它还在 SID 任务上优于 SpeechNet 和预训练模型,例如 SUPERB。 此外,SpeechT5 在 ASR 任务上也分别比基于编码器-解码器的 ASR 模型(即 Fairseq)和一些基线模型获得了大约 10.0% 和 6.5% 的增益,并且比强 Transformer TTS 模型获得了显着的改进( Li et al., 2019) 在 TTS 任务的单词错误率和平均选项分数方面分别下降了 13.4% 和 5.8%。 本文的贡献总结如下:
• 据我们所知,这是第一项研究用于各种口语处理任务的统一编码器-解码器框架的工作。
• 我们提出了一种跨模态联合预训练方法,该方法通过大规模未标记语音和文本数据学习声学和文本表示之间的潜在对齐。
• 对口语处理任务的大量实验证明了所提出的 SpeechT5 方法的有效性和优越性。
SpeechT5
1、模型架构
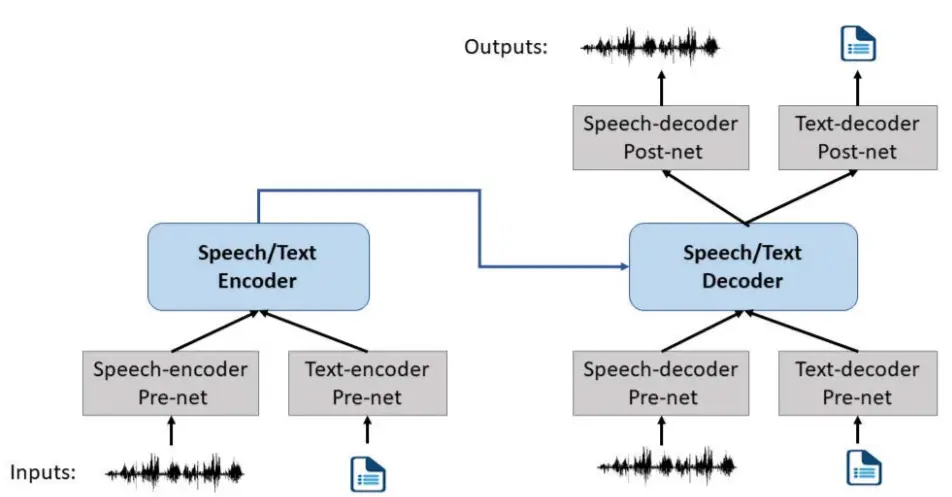
所有口语处理任务都以语音或文本作为输入或输出。 下图显示了所提出的 SpeechT5 模型的模型架构,它由一个编码器-解码器模块和六个特定于模态的前/后网络组成。 预网络将输入语音/文本转换为统一空间,共享编码器-解码器网络对序列到序列的转换进行建模。 然后基于解码器的输出,post-nets 生成语音/文本形式的输出。
输入与输出:
为了在不同的口语处理任务集上训练单个模型,我们将我们考虑的所有任务转换为语音/文本到语音/文本格式,其中输入/输出是语音序列或文本序列。 使用 librosa 工具从每一帧中提取的 80 维 log-Mel 滤波器组特征被视为一个标记。 如果输出是语音模态,我们使用声码器将 log-Mel 滤波器组特征转换为波形。 对于文本,我们使用一元语言模型将文本拆分为一系列标记。
编码器-解码器:
该模型类似于 Transformer。 编码器由一堆块组成,每个块包含两个子组件:一个自注意力层,然后是一个小的前馈网络。 层归一化和残差连接应用于每个子组件的输入。 解码器具有与编码器相似的架构,不同之处在于它在处理编码器输出的每个自注意力层之后包含一个交叉注意力机制。 此外,解码器中的自注意力机制还使用了一种自回归或因果自注意力的形式,它只允许模型注意过去的输出。 我们使用简单的相对位置嵌入来增强模型能力,其中我们只将相对位置嵌入添加到自注意力的点积权重中。
语音预/后处理网络:
语音编码器预网络和语音解码器预网络之间存在一些差异。 在语音编码器预网络中,我们应用两个卷积层(通过卷积步幅)对它们进行下采样并处理局部关系。 在语音解码器预网络中,log-Mel 滤波器组被输入到一个神经网络中,该神经网络由三个具有 ReLU 激活的全连接层组成。 为了支持多扬声器 TTS 和 VC,由公共 x 向量提取的扬声器嵌入与语音解码器预网络的输出连接。 然后由具有 ReLU 激活的线性层处理。 对于语音解码器后网络,我们分别使用两个不同的线性投影来预测 log-Mel 滤波器组和停止标记,并使用 5 层一维卷积层产生残差来细化对数的重构 - 梅尔滤波器组。
文本预/后处理网络:
我们使用共享嵌入作为文本编码器 pre-net 和解码器 pre/post 网络。 pre-net将token索引转化为embedding向量,post-net将隐藏状态转化为token分布的概率,通过softmax函数归一化。 自回归生成的解码器的输入文本发生了变化。 在推理过程中,解码器使用自己过去的信息来预测下一个标token。
2、预训练
借助大规模的未标记语音和文本语料库,我们可以分别对统一模态模型进行预训练,并通过联合预训练方法将文本和声学信息进一步对齐到统一的语义空间中。
语音学习:
语音学习的目标是利用未标记的语音数据来学习语音理解和生成任务的一般语音表示。 为此,SpeechT5 模型被训练为具有两种类型的口语建模任务的统一编码器解码器模型:双向掩码预测和序列到序列的生成。
形式上,语音模块的输入是一个 80 维 log-Mel 滤波器组 X = (x1, ..., xn) 的序列。语音模块由语音编码器预网络和变压器编码器组成,生成隐藏表示 S = (s1, ..., sn)。类似于 BERT 中的掩码语言建模,我们遵循 Hubert 使用声学单元发现模型为 Transformer 编码器的输出提供帧级目标 Z = (z1, ..., zn)。具体来说,我们使用跨度掩码策略,其中 p% 的时间步被随机选择作为起始索引,并且 l 步的跨度被屏蔽。
此外,我们建议通过语音解码器 pre-net、Transformer 解码器和语音解码器 post-net 来重建原始语音。解码器是自回归的,因为在解码当前输出 yt 时,会考虑编码器 S = (s1, ..., sn) 和先前生成的特征 y1:t−1。受到现代 seq2seq TTS 模型成功的启发,我们通过最小化它们的 L1-距离来强制相应的输出 yt 接近原始帧 xt。
此外,我们还使用二元交叉熵(BCE)作为停止标记。 为了解决停止token和正常token之间的不平衡问题,我们对尾部正在计算 BCE 损失的停止token施加正权重。
文本学习:
语言模块旨在提供上下文理解和生成。 总体而言,对于未标记的文本数据,SpeechT5 通过以下方式进行训练:(1)使用具有屏蔽跨度的任意噪声函数破坏文本,以及(2)学习生成可以重建原始文本或屏蔽文本的相应目标。 对于无监督目标,我们可以使用 BART 式或 T5 式掩码策略和目标序列。 在 BART 风格中,该模型旨在从嘈杂的源文本中重建原始文本。 但是,在 T5 样式中,所有选定的片段都从文本中删除并连接为目标序列,而其余部分则连接为源序列。
联合预训练:
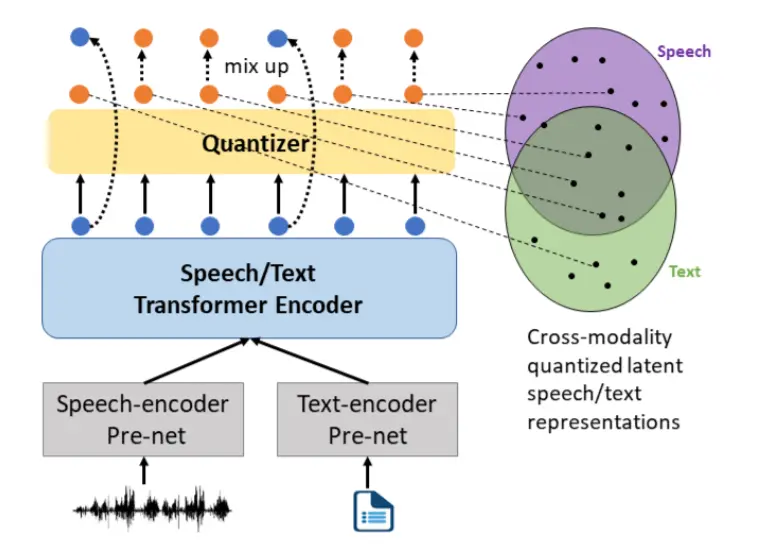
上述预训练方法只能单独利用语音数据或文本数据对声学信息或语言信息进行建模。但是,一些口语任务需要建立语音和文本之间的跨模态映射,例如 ASR 和 TTS。预训练中语音和文本之间的对齐学习将有利于下游任务。出于这个动机,我们提出了一种统一模态预训练方法来学习表征,这些表征通过离散向量量化来捕获模态不变信息。
具体来说,我们的目标是利用矢量量化嵌入作为语音和文本之间的桥梁,并通过共享码本对齐语音表示和文本表示,如下图所示。受 VQ-VAE 和 SemFace 的启发,我们首先使用量化器将编码器输出的这些密集语音或文本表示 si 转换为来自固定大小的码本 CK 的离散表示 ci,其中包含 K 个可学习的嵌入。然后,我们在相应的时间步长中用量化的潜在表示随机替换一部分上下文表示,并计算混合表示的交叉注意力,这可以明确指导量化器利用跨模态信息。
3、微调
在预训练之后,我们使用下游任务的相应损失对编码器解码器模型进行微调。 我们的目标是衡量一般的口语学习能力。 因此,我们在一系列不同的基准测试中研究下游性能,包括 ASR、TTS、VC 和 SID。
我们考虑的四个语音处理任务可以通过连接编码器-解码器模型和相应的 pre-net 和 post-net 来完成。 例如语音-编码器pre-net、encoder-decoder、text-decoder pre-net、text-decoder post-net可以构成ASR模型,训练损失为最大交叉熵损失。