

相信很多朋友都遇到过乱码的问题,尤其是经常接触日本那边的软件的朋友。那么,这些乱码是如何产生的?又该如何避免呢?本篇文章将简单介绍关于计算机中显示字符的方法以及乱码产生的原因,并讨论一些喜(sang)闻(xin)乐(bing)见(kuang)的混淆方式。
0. 一切的开始——二进制
众所周知,计算机依靠二进制储存一切信息,不过这里我们并不想讨论为什么是二进制而不是其他进制,那与本文无关(好吧,其实就是因为使用“通”和“断”两种信息比较方便)。这里引出二进制的目的是为了明确指出:即使是字符,在计算机中也是按照二进制形式保存的,与一般的数字或者可执行的代码片段在形式上并无差异。
既然字符与其他形式的数据并无差异,那计算机是如何识别它们的呢?也就是说,为什么计算机能认出来某一段数据是字符,而另一段数据就不是呢?答案是,其实有一点奇怪,计算机并不能识别出来哪一段数据才是字符,而是可执行的代码片段告诉它应该把某一段数据作为字符来解读,计算机才会把这一段当成字符。
所以,很明显,如果计算机把本来就不是字符串的数据当成字符串来解读(比如尝试用记事本打开二进制文件),就会显示成乱码。这是乱码的第一种产生方式。然而在实践中,会有很多人注意到如果使用中文Windows的记事本尝试打开记录日文的txt文件,大概率也会显示为乱码。这显然不是由于计算机把本来不是文字的数据当做文字进行解读。
下面我们将着重讨论这种情况。
1. 从ASCII码表开始认识字符
如果追溯到原理层面的话,计算机其实是使用一套类似查表的方法来显示字符的。也就是说,二进制保存的是某个字符在某个码表上的序号,而在显示的时候计算机从那个码表中找到序号所对应的字符并把它输出。目前在英语体系中使用相当广泛的一套码表是ASCII码表(其实后面是罗马数字2而非两个大写字母I,更不是小写字母l)。
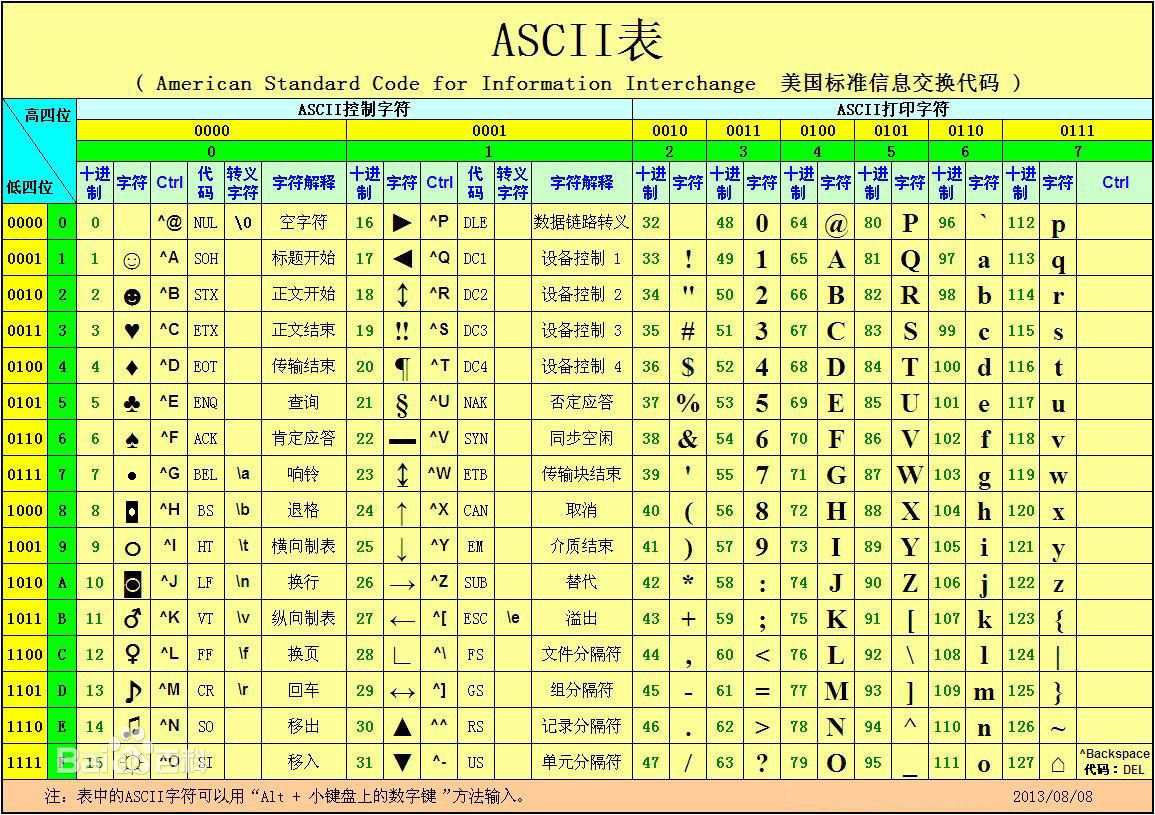
常用的ASCII码表
标准ASCII码表的有效范围是0-127,也就是7比特位,不到1字节。在标准ASCII码表体系下的字符每个占1字节。此外,ASCII码表主要分为两个区域,即控制字符区域和打印字符区域。控制字符区域主要是文件头、文件尾、空格、换行、退格、回车等,没有固定的显示方式甚至不能显示;打印字符区域是我们常用的符号以及英文大小写字母以及阿拉伯数字。
根据上面这张表,我们可以很容易地发现字符A对应的序号是65。事实上,在计算机上,一篇英文文章中的字符A的确是被保存成65的,也就是十六进制的0x41,二进制的0b01000001
由于空间限制,标准ASCII码表不能很好地适用到世界上的各个国家中去。汉语、日语、韩语、阿拉伯语、泰语等等所使用的字符都没有被包括进去,而且由于字符数量繁多造成一个字节根本不够用。为了解决这些问题,国际标准化组织(ISO)提出了双字节字符集的方案以扩充原本的单字节字符集。有了更多的可用空间,东亚国家纷纷出台了自己的标准来让计算机显示自己国家的文字,字符集的差异也是在这时候形成的。
(注:这里省略了扩展ASCII标准的部分,因为与本文核心内容无太大关联)
2. GBK的诞生
ISO只提出了扩展标准ASCII码表的方法,但是没有明确规定扩展后的码表中哪一个序号对应哪一个字符。根据ISO-2022标准,各个国家出台了自己的标准。中国拿出的标准是GB2312,根据这个标准制作的字符集就是GBK字符集。
上文提到过,标准ASCII码表的有效范围是0到127,也就是0b00000000到0b01111111。显然,最高位始终是0。ISO的方案就是在最高位为1的情况下将这个字符视为双字节字符。换句话来说,双字节字符的两个字节都是0b1xxxxxxx的形式。这样一来,双字节字符就可以使用14个比特位,一共能容纳16384个双字节字。
GB2312是根据ISO-2022标准修改过来的,在这16384个空间中编码了常用的6763个简体汉字和682个符号,以及一部分数学符号、罗马希腊的字母和日文的假名。显然,六千多个字是远远不够用的,以至于那时候有些人的名字中含有生僻字的话就不能显示。在这个基础上,中国人认为只要第一个字节的最高位是1就可以代表这是一个双字节字,而不必刻意要求第二个字节的最高位也是1。因此,把第二个字节所有的比特位都拿来编码汉字,就形成了GBK字符集。相比于GB2312标准,GBK的容量达到了32768,相当于凭空多了一倍的容量。
不同于中国政府最终拿出的GBK字符集,日本政府的方案是SHIFT-JIS字符集。其编码方式与GBK大同小异,只是不同的编号对应了不同的字符。
由于这些国家标准出现的很早(GB2312出现于1995年),那时还没有Unicode,因此早期的Windows在针对某个地区进行本土化时也不得不采用相应的方案。中国大陆地区使用GBK,中国台湾、香港地区使用BIG5(繁体中文),日本地区使用SHIFT-JIS。此后,作为一个历史遗留问题(主要是为了向前兼容),Windows直到现在也还是使用这些国家和地区标准作为优先选项的。乱码问题就这样产生了:
假设某一个日本人在文稿中记录了“アニメ”的字样,由于他使用的是日本的Windows,那么系统会优先为他选择SHIFT-JIS编码进行保存。根据查表可知,ア的序号是0x8341,ニ是0x836A,メ是0x8381,因此最终保存在文稿中的是这些序号。现在有一个中国人得到了这份文稿,并且在他的中文Windows上打开,那么Windows会优先为他选择GBK编码进行解析,查表得到的结果是“傾僯儊”,完全就是乱码。
会受到影响的不只是文稿,文件名和文件夹名也会遇到同样的问题。各位MMDer应该没少碰到这种情况。那么问题来了,既然知道了乱码是如何产生的,那有没有什么好的办法解决或者避免呢?这就要请出人类智慧的结晶——Unicode
3. Unicode:被叫做万国码感觉逼格都低了
很早就有人意识到了这种问题,并且尝试解决。现阶段拿出来的方案就是使用一种叫做Unicode的编码规则对所有语言进行统一编码,也就是让所有人都用同样的字符集。
Unicode面临很多挑战,其中最大的挑战就是兼容性。在理想情况下,Unicode应该能无缝对接现行的国家标准,然而事实上我们都知道这不可能,因为各个标准之间有重合的部分。这就涉及到取舍。其次,Unicode如果延续ISO-2022的双字节标准势必还会遇到空间不够用的情况,因为双字节最大只能提供65536个空间。如果在此基础上继续扩张空间,又会造成文本容量暴涨。鉴于目前英语世界使用计算机最广,以及所有遵循ISO-2022的国家标准都向下兼容标准ASCII码表,Unicode采取了一种弹性的编码规则,并衍生出了数种编码规范。我们将会在下一节中具体讨论。
说到底,Unicode依旧采用的是给不同的字符标上不同的序号的原则。在Unicode字符集下表示一个字符一般采用U+xxxx的格式。假设“对”这个字的编号是23545,那么他就可以表示为U+5BF9(23545转化成十六进制)。
需要查表可以参考Unicode字符百科:https://unicode-table.com/cn/
你会发现很多“居然连这个字符都有?!”的例子。
4. 权衡利弊:UTF-8与UTF-16
刚才我们已经提到了,Unicode字符集的本质只是把文字重新进行了统一的编号,而UTF-8和UTF-16(其实还有UTF-32)解决的就是如何保存这些编号的问题。
Unicode目前使用的总序号远大于65536,即两个字节的极限,因此它提出了一种变长编码方式:根据不同的高位组合来表示当前的字符使用了几个字节。UTF-8指的是基本单位为一个字节,每次扩展时增加一个字节;UTF-16指的是基本单位两个字节,每次扩展时增加两个字节。下面我们将详细说明。
英语的文档在互联网上占有很大的篇幅,因为编写网页使用的HTML、CSS和JavaScript中大部分内容都是英语。在以前的ASCII环境下,每一个英语字母只需要一个字节。UTF-8就是为了最大程度的照顾这一事实的。在UTF-8编码下,如果第一个字节最高位是0,则这个字符为一字节字符,此时UTF-8等同于ASCII。而当表示两字节字符时,这两个字节分别是0b110xxxxx和0b10xxxxxx的形式,一共有11个自由的比特位,容量为2048。当表示三字节字符时,三个字节分别是0b1110xxxx和两个0b10xxxxxx,共16个自由比特位,容量为65536。其他情况不再赘述。也就是说,UTF-8需要三个字节才能达到双字节字标称的容量,因此在存储诸如中文、日文、韩文的时候会需要更多的字节,但是相对的在存储英文的时候只需求一字节。目前互联网上的网页几乎都是UTF-8编码。
UTF-16相对于UTF-8而言只需要自己本身的两个字节就可以提供65536的容量(老标准),在存储中文、日文、韩文时往往需求更少的空间,不过相对的在存储英文时同样需求两字节的空间,因此属于对宽字符比较友好而对英文不友好的一种折中。
需要注意的是,全部的Unicode编码方式在文件开头处都有被称为BOM的标志块用来说明当前文本使用的是何种类型的Unicode编码方式。UTF-8文档开头的前三个字节是0xEF,0xBB和0xBF。UTF-16则根据大端序或者小端序使用不同的BOM。小端序使用0xFE和0xFF,代表接下来出现的两两一组的字节中先出现的一个是低地址(即“第一个”字节);大端序使用0xFF和0xFE,代表先出现的是高地址。目前Windows和Linux大多使用小端序,而Mac使用大端序。顺带,小端序即UTF-16LE,也就是MMD的PMX格式使用的编码方式。万恶的VMD文件使用SHIFT-JIS字符集。
到目前为止,最好的处理这些乱码的方式就是把它们先转化成Unicode编码再转换成我们自己的计算机所使用的字符集或者直接输出。主流的高级语言对于不同的字符集都支持的很好,比如Java、C# 和Python,只需要几行代码就可以完成这个过程。但是C++不行,因为std::string没有完成它应尽的义务,只是简单地在字符型数组外面套了一层壳。C系请参考libiconv
5. 趣闻
浏览Unicode码表的时候会发现很多稀奇古怪的字符:
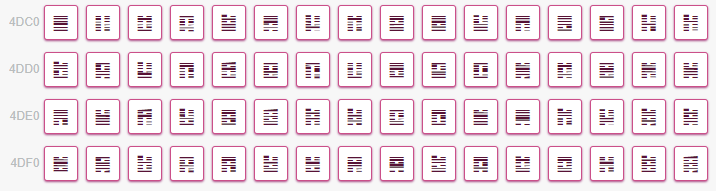
易经六十四卦符号(U+4DC0~U+4DFF)
我们知道八卦符号天生就有“通”“断”两种记号,就像二进制一样。易经六十四卦的每个字符都有六条或通或断的横线,正好可以用来代表计算机中的六个比特位。有一种非常经典的加密方式——Base64——也是使用六位替换八位的,即使用四个字节来表示三个字节的内容。根据Base64的原理,我们也可以自己尝试着使用易经六十四卦来加密一些文本。这里的每一个符号都是合法的Unicode字符,都可以在网页上或者聊天工具的对话框中显示,或者保存为文本形式(一定注意编码,GBK字符集中没有这些符号)。
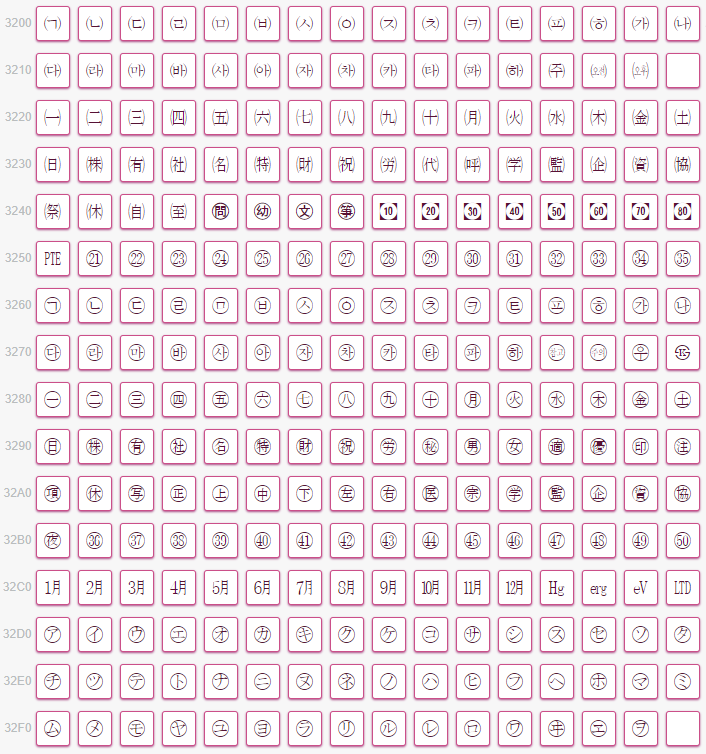
带圈的中日韩字母和月份(U+3200~U+32FF)
这里可以看到有些月份,需要注意的是这些月份都是一个字符,尽管看上去像是1月,然而实际上是㋀,是完全不同的概念。

中日韩字符兼容(U+3300~U+33FF)
这里给出了一个字符的日子和时间,还有五十音图用到的奇怪的字符。配合上面的月份,已经可以组合出很奇怪的密码了。比如㋉㏪

方块元素(U+2580~U+259F)
如果愿意的话,用这些字符画画也是可以的。虽然Unicode码表里面还有更奇怪的花纹,但是这些字符可以很好地拼凑出像素,适当组合的话会形成很漂亮的字符画。

希腊问号(U+037E)
传说中和英文分号放在一起根本区分不出来的符号。可以尝试把你的程序员朋友的代码中所有的分号都替换成这个,如果那之后你还有命活下来的话。(;;←能看出区别吗?)

箭头(U+2190~U+21FF)
各种样式的箭头,你喜欢的样子它都有。
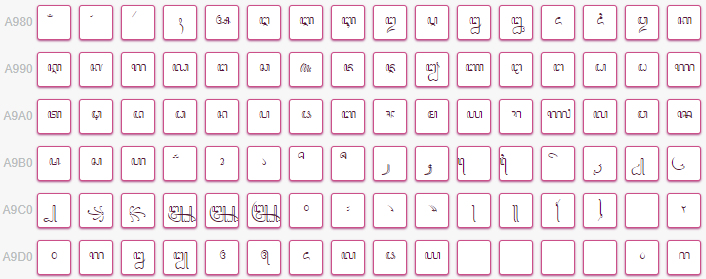
爪哇语(U+A980~U+A9DF)
字符表情和群名片的常客,然而与Java并没有半毛钱关系。

这才是Java☕(U+2615)
