

前言
这里讨论的随机数(random number)为随机实数, 对于随机整数(random integer)会叫做...随机整数, 嗯.
实际上自己并没有学过概率论什么的, 自己本质上就是一个小会高数的高中生罢了. 以下内容赌的成分偏多 (
在实际应用中, 生成任意随机数都可以分为三步: 1) 生成随机整数. 2) 从随机整数得出均匀分布随机数. 3) 从均匀分布随机数里得出其他分布随机数.
随机整数
生成随机整数的方法有很多, 有简单的线性同余发生器(Linear congruential generator, LCG), 有复杂的梅森旋转器(Mersenne twister), 甚至可以使用现实电路产生真随机数. 这里并不会详细介绍产生随机整数的方法, 有兴趣的可以去翻翻wiki(见底部).
大部分随机整数生成器会指定整数分布的区间 [MIN, MAX], 给出的随机整数将会均匀分布在区间里. 常用的随机整数生成器区间为 , 或是
, 刚好是uint32和uint64可以表示的全部范围. 确保随机整数分布的均匀性是非常重要的, 因为这是为了方便后续步骤变换随机数的分布方式.
# 如果下面出现代码的话, 将会以这个函数代指随机整数的生成方法
# 调用一次将会返回一个随机整数
def random_integer() -> int: ...
均匀分布随机数
常用的均匀分布随机数的分布区间为 [0, 1), 需要注意的是半开区间, 也就是说实数1是不能取到的.
把均匀分布的随机整数转化为均匀分布的随机数是非常简单的, 把随机数减去MIN再除以MAX-MIN+1就可以得到分布在[0,1)里的随机数了. 因为一开始生成的随机整数不是连续分布的, 所以使用这种方法转化的随机数也不是连续分布的, 但是对于实际使用来说已经足够好了.
def random() -> float:
return float(random_integer() - MIN) / (MAX - MIN)
了解了如何生成均匀分布的随机数, 接下来就是生成其他分布形式的随机数了. 因为这里是说通用的生成方法, 所以有必要了解什么是随机数的分布.
概率密度函数
概率密度函数(probability density function, pdf)是一个用来描述随机数分布在给定区间的可能性的函数. 对指定区间下的pdf进行积分即为随机数分布在这个区间里的概率. 即
例子: 给出一个随机数生成方式: 2 * random(), 对应的pdf为
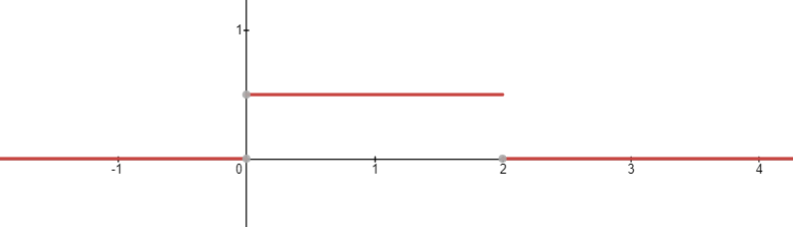
则生成随机数会以50%概率分布在0到1里, 以100%概率分布在-2到2里, 以此类推.
另外一个著名的例子就是正态分布, 下面给出标准正态分布的pdf:
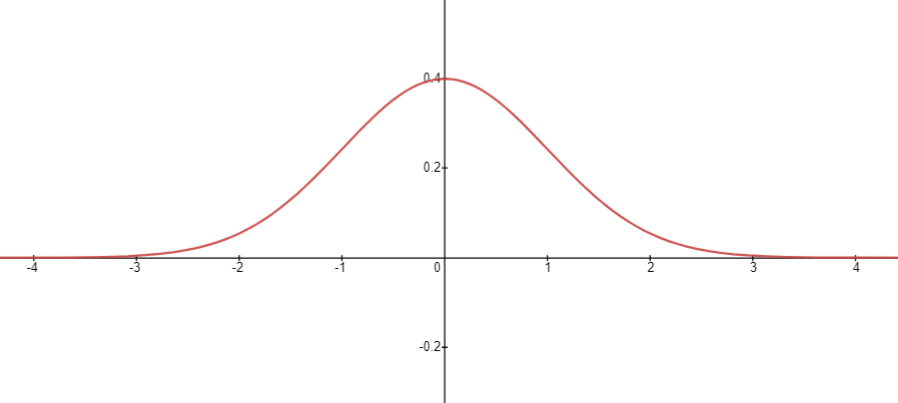
符合标准正态分布的随机数会以68.27%概率分布在-1到1之间, 95.45%分布在-2到2之间, 并且以50%分布在0到+∞之间.
累积分布函数
累积分布函数(Cumulative Distribution Function, cdf)定义为随机分布小于给定数字的概率, 根据pdf的定义, cdf为
根据cdf, 随机数分布在特定区间下的概率可以表示为
例子: 以2*random()生成的随机数的cdf为
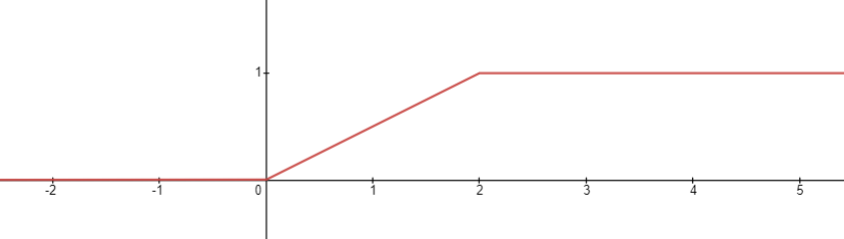
而标准正态分布的cdf为
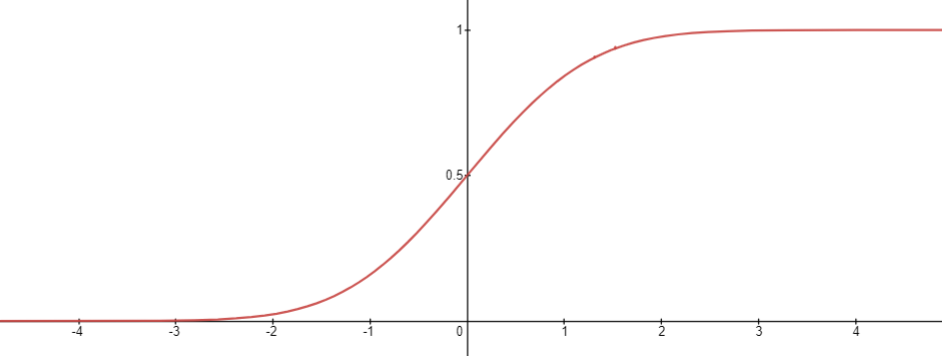
逆累积分布函数
因为pdf为随机数的概率密度函数, 所以pdf会符合关于"概率"的规则: pdf必定大于等于0 (不存在负数概率), pdf在全体实数上积分为1(概率总和为1). 因为cdf是pdf的积分, pdf的第一条特性定义了cdf必定是单调递增的, pdf的第二条特性定义了cdf有下界0和上界1.
因为cdf是单调递增的, 所以cdf存在逆函数, 并且cdf的逆也是单调递增的. cdf有下界0和上界1说明cdf的逆定义域为[0, 1]
从均匀随机数里生成任意分布的随机数
暴论: 已知某种特定分布的逆累积分布函数inv-cdf, 则把均匀分布的随机数经过inv-cdf处理后得到的随机数符合这种分布, 即
其中X是均匀分布随机数, 则Y符合特定分布.
这是十分容易证明的: , 因为X是均匀分布的, 所以有
, 如此可知Y满足特定分布.
例子: 三角形分布
三角形分布因为它的pdf形如三角形而得名. 三角形分布需要给出下限a, 上限b, 和众数c.
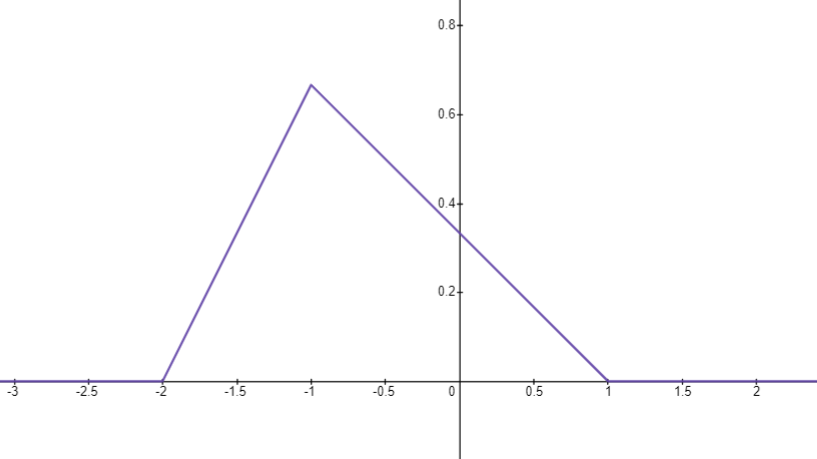
a=-2, b=1, c=-1
三角形分布的pdf定义为
对pdf积分求逆得到逆累积分布函数:
如果X是均匀分布的随机数, 那么是三角形分布, 可以简单地写一个jio本进行验证
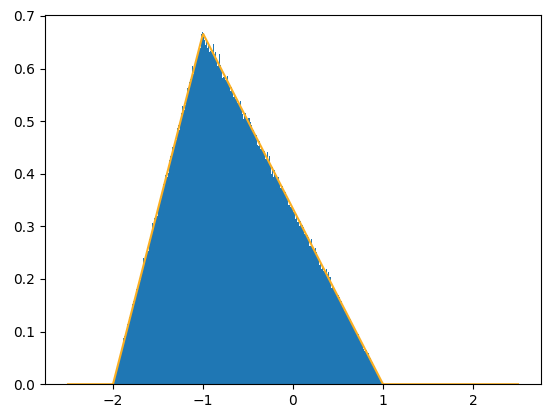
统计区间宽度0.01, 采样次数1000000
例子2: 正态分布
正态分布的pdf为
那么cdf为
其中 称为误差函数(error function), 则cdf的逆为
需要注意到的是, erf并不是初等函数, erf的逆也不能直接求出. 但幸运的是, 目前erf的逆有许多近似的方法. 使用一种快速但低准确度的逆erf进行验证随机数的正确性:
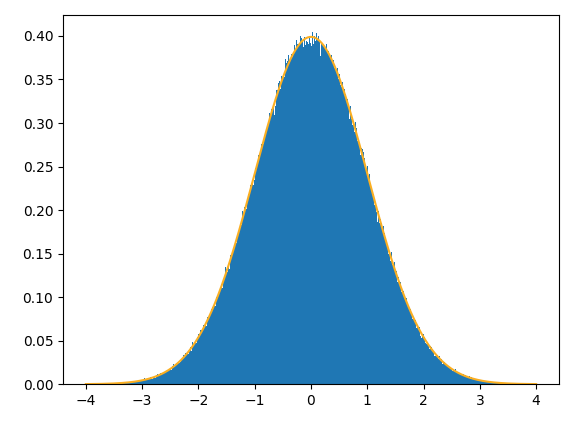
统计区间宽度0.01, 采样次数1000000
关于逆变换采样的讨论
1) 逆变换采样具有通用性, 所有随机分布都有相应的分布函数pdf, 由pdf推导出cdf的逆即可生成任意分布的随机数. 但是需要手动计算积分和求逆, 很有可能不存在初等函数可以表示的解. 2) 大部分随机过程都是由随机整数生成器为基础, 而随机整数生成器存在周期性, 比如说LCG只有长度的周期, 而梅森旋转器的周期长达
. 使用其他产生特定分布的方法可能会使得周期产生变化, 比如使用LCG与C++TR1里的方法产生正态分布会使得周期缩短至
, 这是因为在C++TR1里的生成正态分布的方法需要取两次随机数才可以生成一个正态分布随机数. 而对于逆变换采样, 不管什么分布都只需要取一次随机数. 3) 逆变换采样具有对比拒绝采样(rejection sampling)更快的运算速度. 对于拒绝采样以及其衍生算法, 需要采用大量的判断语句, 而分支对运行速度是不好的 (特别是GPU运算). 因为逆变换采样需要用到大量初等函数, 所以面对其他的优化算法就显得特别累赘了.
示例代码在下面贴出, 运行需要Python3 + numpy + matplotlib.
import numpy as np
from numpy.random import random # uniform random number in range [0, 1)
from matplotlib import pyplot as plt
def erfinv(x: float) -> float:
# Mike Giles - Approximating the erfinv function
w = -np.log(1. - x*x)
if w < 5.:
w -= 2.5
p = (((((((2.81022636e-08 * w + \
3.43273939e-07) * w + \
-3.5233877e-06) * w + \
-4.39150654e-06) * w + \
0.00021858087) * w + \
-0.00125372503) * w + \
-0.00417768164) * w + \
0.246640727) * w + \
1.50140941
else:
w = np.sqrt(w) - 3.
p = (((((((-0.000200214257 * w + \
0.000100950558) * w + \
0.00134934322) * w + \
-0.00367342844) * w + \
0.00573950773) * w + \
-0.0076224613) * w + \
0.00943887047) * w + \
1.00167406) * w + \
2.83297682
return p * x
class RandomDistribution: # basic interface
def pdf(self, x: float) -> float: # probability density function
raise NotImplementedError
def __call__(self) -> float: # ganerate a random number with a distribution
raise NotImplementedError
class Triangular(RandomDistribution):
def __init__(self, _min: float, _max: float, _mode: float) -> None:
assert _min < _max and _min <= _mode <= _max
self.min = _min
self.max = _max
self.mode = _mode
# precompute some values
self._call_coff1 = (_mode - _min) / (_max - _min)
self._call_coff2 = (_max - _min) * (_mode - _min)
self._call_coff3 = (_max - _min) * (_max - _mode)
self._pdf_coff1 = 2. / self._call_coff2
self._pdf_coff2 = 2. / self._call_coff3
def pdf(self, x: float) -> float:
if self.min <= x < self.mode:
return self._pdf_coff1 * (x - self.min)
elif self.mode <= x < self.max:
return self._pdf_coff2 * (self.max - x)
else:
return 0
def __call__(self) -> float:
x = random()
if x < self._call_coff1:
return self.min + np.sqrt(self._call_coff2 * x)
else:
return self.max - np.sqrt(self._call_coff3 * (1. - x))
class Normal(RandomDistribution):
def __init__(self, sigma: float, mu: float) -> None:
assert sigma > 0.
self.sigma = sigma
self.mu = mu
# precompute some values
self._call_coff1 = sigma * np.sqrt(2.)
self._pdf_coff1 = 1. / (self._call_coff1 * np.sqrt(np.pi))
self._pdf_coff2 = 1. / (2 * sigma*sigma)
def pdf(self, x: float) -> float:
return self._pdf_coff1 * np.exp(-np.square(x - self.mu) * self._pdf_coff2)
def __call__(self) -> float:
return self._call_coff1 * erfinv(2. * random() - 1.) + self.mu
def test_random_distribution(generator: RandomDistribution, _min: float, _max: float, interval: float, n_samples: int) -> None:
n_counting = int((_max - _min) / interval)
_coff1 = n_counting / (_max - _min)
counting = np.zeros([n_counting], float)
for _ in np.arange(n_samples):
y = generator()
index = int(_coff1 * (y - _min))
if 0 <= index < n_counting:
counting[index] += 1.
counting *= 1. / (n_samples * interval)
x_counting = np.linspace(_min, _max, n_counting)
pdf = np.array([generator.pdf(x) for x in x_counting])
plt.bar(x_counting, counting, width=interval)
plt.plot(x_counting, pdf, color="#FBAF22")
plt.show()
#####################################################################################
test_random_distribution(Triangular(-2, 1, -1), -2.5, 2.5, 0.01, 1000000)
test_random_distribution(Normal(1., 0.), -4, 4, 0.01, 1000000)END.
吐槽
为什么会有一篇这样的东西出来呢. 其实是最近自己在用C艹写光追, 打算自己造轮子的时候遇上了"如何生成正态分布随机数"这个难题(baidu-less). 然后灵机一动自己发现了这种计算方法, 但是直到专栏写到一半才看到了原来这种方法叫逆变换采样. 嗨, 还以为发现了什么新大陆.
关于上面的示例代码, 原本是打算用C艹写的, 顺便做一波性能分析, 但是突然发现C艹画图实在太麻烦的(相对于matplotlib), 于是还是滚回了心爱的python下. 原本代码是打算发到gayhub上的, 但是感觉为了一个100多行的文件去开一个仓库也太小题大做了, 而且发百度云有点low, 也不知道有没有其他分享代码的方法, 就直接在文章结尾贴出了.
更多资讯:
梅森旋转器: en.wikipedia.org/wiki/Mersenne_Twister
线性同余发生器: en.wikipedia.org/wiki/Linear_congruential_generator
概率密度函数: en.wikipedia.org/wiki/Probability_density_function
累积分布函数: en.wikipedia.org/wiki/Cumulative_distribution_function
逆变换采样: en.wikipedia.org/wiki/Inverse_transform_sampling
如何产生正态分布的随机数?zhihu.com/question/29971598
逆误差函数(1) Anthony J. Strecok - On the Calculation of the Inverse of the Error Function
逆误差函数(2) Mathematics of Computation - Rational Chebyshev Approximations for the Inverse of the Error Function
逆误差函数(3) Mike Giles - Approximating the erfinv function
