

上节课的ALL函数在今后的课程上还会经常拿出来讲,大家需要慢慢吸收。本节课的知识,只要你遵循数据库原理,表格都是1对多关系,1端主键不为空不重复,且1端主键元素数大于等于多端外键的元素去重后的个数(数据库:实时参照完整性),可以当本节课就是在浪费时间。只是《The Definitive Guide to DAX》举了例子,国内就有人依此抬扛,并且组建了DAX原理大军。

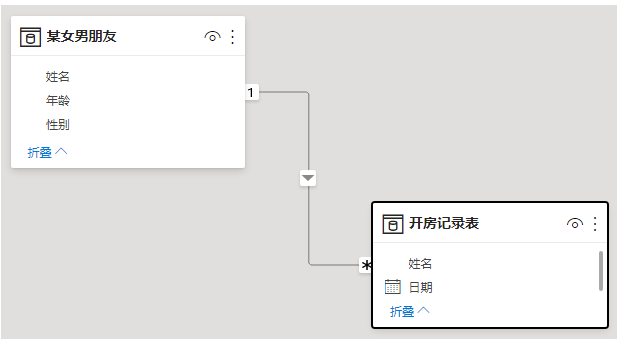
图1-9-1
如图1-9-1,1端表姓名有3个人,多端表姓名有4个人,这是1对多,但它是典型的实时参照不匹配。接下来我们主要是在这种情况下举例:
VALUES与DISTINCT函数都是表函数,返回的都是一张表
参数有两种情况:
VALUES(列) 、 VALUES(表)
DISINCT(列) 、DISTINCT(表)
我们先来看参数是列的情况:
DISTINCT(列):对某列去重,返回一张单列的表,他不会考虑表之间的关系问题。
我们分别对多端表和一端表,使用【新建表】:
表1 = DISTINCT('开房记录表'[姓名])

表2 = DISTINCT('某女男朋友'[姓名])

VALUES(列):对某列去重,返回一张单列的表,他会判断是否关系正常,如果实时参照不匹配会返回空行。
会有两种情况:
1.如果这两张表没有关系,效果等同于DISTINCT(列)
表3 = Values('开房记录表'[姓名])
表4 = Values('开房记录表'[姓名])
2.如果这两张表是正常的一对多关系,这时又会有两种情况
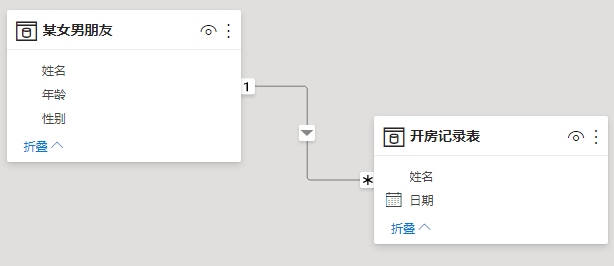
情况1:一端姓名3个人,多端姓名3个人,一端主键人数大于等于多端姓名人数。效果等同于DISTINCT(列)
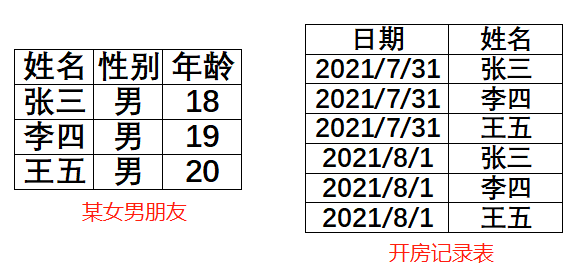
表5 = Values('开房记录表'[姓名])
表6 = Values('开房记录表'[姓名])
【重点】情况2:一端主键小于多端外键数量,例如1端只有3个人,而多端有4个人。
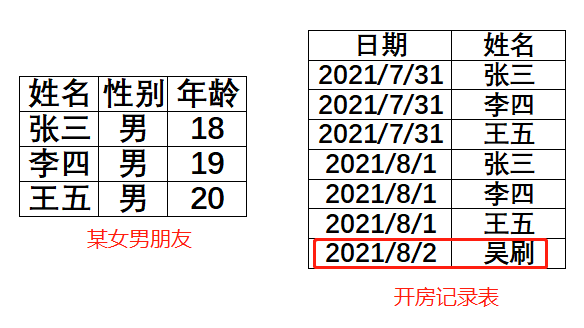
某女男朋友分别是张三,李四,王五,但是她突然与一个不认识的人叫吴刷的开房了,这种情况,他们的关系有问题,是否违法,需由有关部门调查。我们讨论的不是法律问题,而是遇到这种问题时,谁来发出预警?答:Values
表7 = Values('开房记录表'[姓名])
表8 = Values('某女男朋友'[姓名])

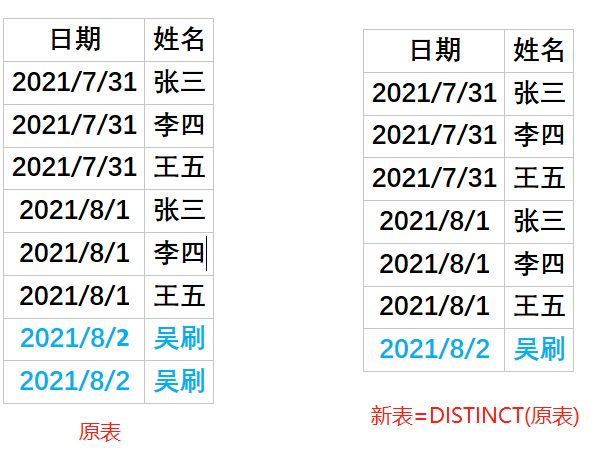
其实,绕了这么一大圈就是表8出问题了。这里多了一个空,而这个空,就是告诉你,有一个或多个跟她开过房的人其实她们并不认识。请有关部门调查。
当你的表出现这种情况时,就是告诉你,你的1对多关系中,出现了实时参照不匹配的情况,请检查表格。
假设,你开一个小卖部,你只卖食品,你的商品表中也只登记了这相关食品,但是你在销售记录中发现了「骨灰盒」、「寿衣」之类的销售时,赶快抽自己一个大嘴巴,上班要迟到了。
再举个例子,华为专卖店,只卖华为产品,你拿着一台新买的小米手机,让他们用POS扫一下,看看它多少钱?扫描结果是没有此商品,因为人家一端表中没有小米手机的信息。
我在2020年6月《PowerBI基础篇重制版》里面跟大家说,建议使用SQL拿到一张干净的表,你就可以避开99%的原理。如果不是多表连线,这两个函数在参数是列的时候就没有区别。
接下来,我们看一下他的应用:
大家都知道聚合函数CountRows参数是一张表,之前我们可以用Filter筛选表或ALL全选表,通过缩小或扩大表的范围后放到CountRows(表)里面计算行数。
如果我们只想计算某个表中的某个列它去重之后的行数。这个时候我们就用到了Values或DISTINCT。我们以实时参照不匹配举例:
新建度量值,并放到矩阵中:
D行数 = countrows(DISTINCT('某女男朋友'[姓名]) )
V行数 = countrows(VALUES('某女男朋友'[姓名]) )
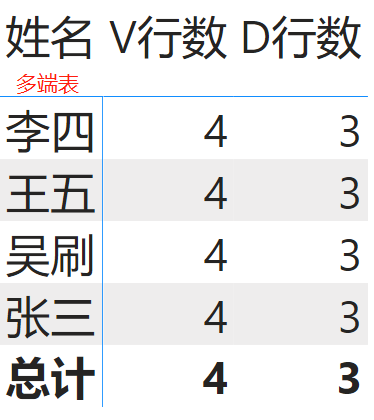
如上图,当矩阵行标题是多端表中的姓名时,多端不能筛选一端,所有度量值没有筛选功能,但是由于Values检测到实时参照不匹配的情况,多了一个空行,它的总行数就是4,而DISTINCT的总行数就是3。
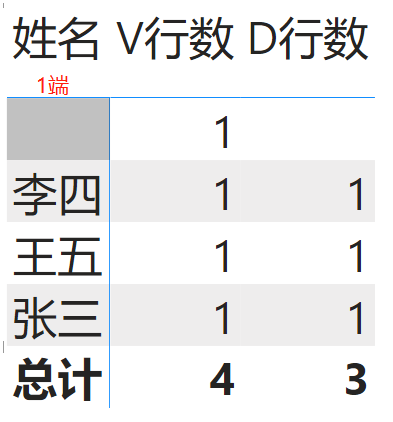
如上图,当矩阵行标题是一端表中的姓名时,可以筛选了,Values检测到实时参照不匹配的情况,多了一个空行,它的总行数就是4,筛选后每个人都是1,而DISTINCT的总行数就是3。
当出现实时参照不匹配的时候,如果我们需要不显示这个空行,就会用到DISTINCT(列)。
开始时就告诉大家,ALL函数以后要讲的地方多了去了,这节课我们就再讲讲,其它ALL(列)与Values(列)只是功能不同,前者是全选,后者是去重。但是,它们有一个共同点:都会考虑是否出现了实时参照不匹配情况,如果出现了,就会在你all(一端表[列名])时,出现空行。
我们可以使用《火力全开》笔记第8课讲的ALLNOBLANKROW函数处理空行问题。
ALL(列) 与 ALLNOBLANKROW(列)
Values(列) 与 DISTINCT(列)
左边函数会检测空行,右边函数会忽略检测。
我们写两个度量值:
all行数 = countrows(all('某女男朋友'[姓名]) )
ALLNOBLANKROW行数 = countrows(ALLNOBLANKROW('某女男朋友'[姓名]) )

如上图所示,我们使用卡片图展示两个度量值的结果,all行数 =4,因为它检测到了实时参照不匹配,产生了一个空行。而ALLNOBLANKROW行数忽略了检测,返回的就是3。
这里给大家讲一个故事:2020年10月7日我20岁生日当天晚上,DAX原理之父某枫讲师1分钟内在我的powerbI所有视频下留言,称我不讲原理是坑人误导人。后来我看了一下他讲的内容,完全是看完《The Definitive Guide to DAX》着魔了,书中确实是这样讲的,但是在实际工作中,一对多关系,是要尊寻实际参照完整性的,没有意义的事情我何必在新手小白的课程中反复强调呢?数据库的基础知识很重要,不懂数据库,必会走火入魔。
并不是所有事都可以拿来抬扛,我曾经在知乎上给部分讲师讲过一个道理:
假设有一个叫吴刷的人,正在被警方围剿,这时他突然原地起飞,飞出地球之外。注意细节,他是原地起飞。高度不影响经纬度。那么他这种行为,在没有改变经纬度的情况算不算逃跑呢?如果是罗老师讲法,我们可以研究探讨。如果今天要执行抓捕行动,你问领导遇到这种情况,我可不可以采取必要措施,领导可能会说你科幻电影看多了。
刚才我们说了参数为列的情况,现在我们说说参数为表的情况:
DISTINCT(表) :只有每个列都重复,才会去重。
DISTINCT表 = countrows(DISTINCT('开房记录表'))
《The Definitive Guide to DAX》上面的解释翻译成中文:对表去重但是不考虑空行。
刚才你们是否发现了一个问题,Values(1端表[列]) 才会有空行的问题,Values(多端表[列])没有空行问题,因为检测实时参照不匹配的问题,是从一端检测多端的。
我们只会将DISTINCT函数用到多端表上,一端特点是什么?答:主键不为空不重复。那么你用DISTINCT(1端表)和直接用这张1端表有什么区别呢?根本就没有重复,谈何去重?既然我们不应用到一端,又谈何检测实时参照不匹配呢?
总结:
DISTINCT(表) :只有每个列都重复,才会去重。
这就是喜欢英语和喜欢数学的区别,拥有逻辑思维的人,不会全信任何书籍,要自己测试,依据事实说话。
Values(表) :复制一张表,但是当参数是一端表时,会考虑实时参照不匹配。反之,参数是多端时就不会考虑了。
VALUES表 = Countrows(VALUES('某女男朋友'))

你看出现空行了吧?同理,ALL(表)也会遇到同样问题,我们会使用ALLNOBLANKROW(表)处理,详见《火力全开》笔记第8课
忠告:别研究这些没用的东西,你只要正确建立表和表关系,一对多关系,主键不为空不重复,一端主键永远不小于多端外键。满足了这个条件后,原理就变简单了,就可以用以下语言代替:
Values和Distinct当参数为列时,都是返回去重后的单列表。
(指定多列去重我们以后再讲,这两个函数只支持一个参数,不支持指定多列去重)
Values(表):复制一张表。
Distinct(表):所有列都重复才去重并返回去重后的表。
让所有关于这两个函数的原理,灰飞烟灭吧!
