
PySceneDetect详情出门左转官网:
https://pyscenedetect.readthedocs.io/en/latest/
本教程仅适用Win系统
Mac系统可以跳转以下参考链接:
跟着教程步骤走,
实现下图拉片效果:
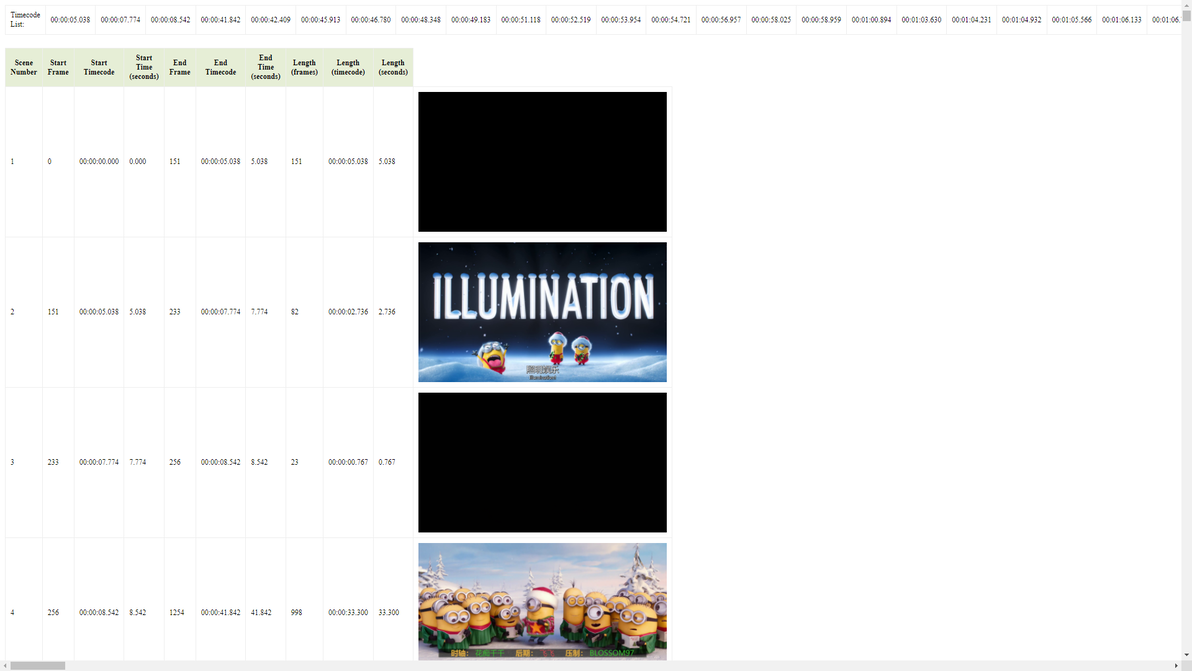
PySceneDetect生成html预览网页
步骤一:下载并安装Python 3
下载地址:
https://www.python.org/downloads/windows/
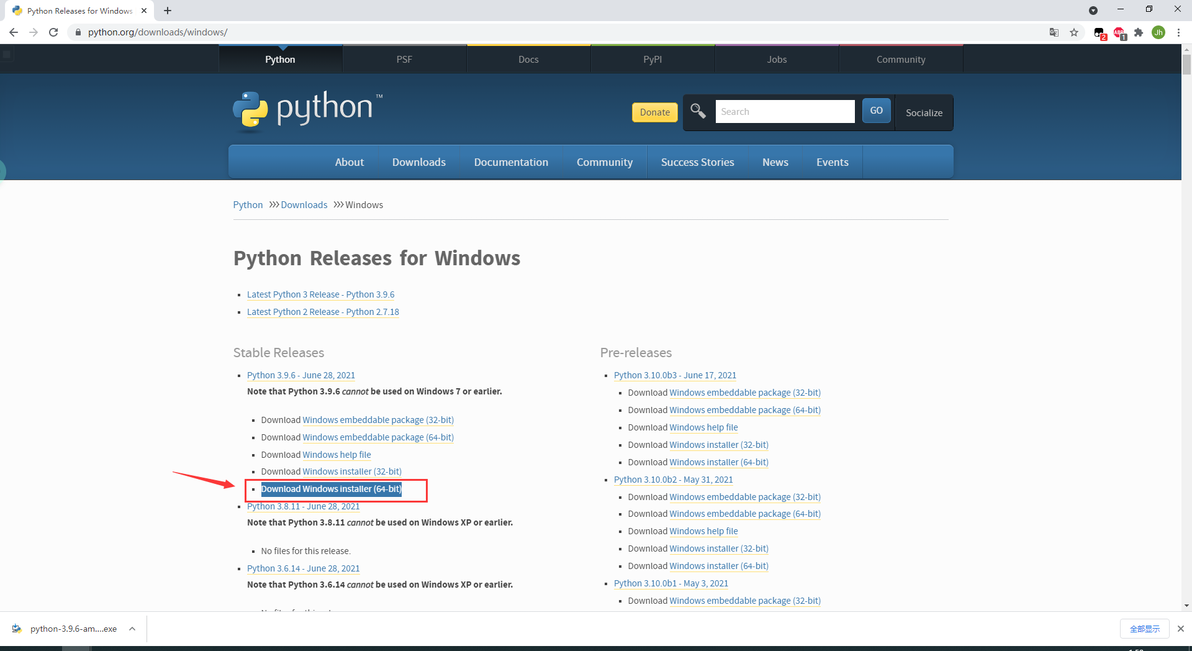
下载并安装Python 3
1.1、鼠标左键双击下载好的安装包
(python-3.9.6-amd64.exe),
点击运行
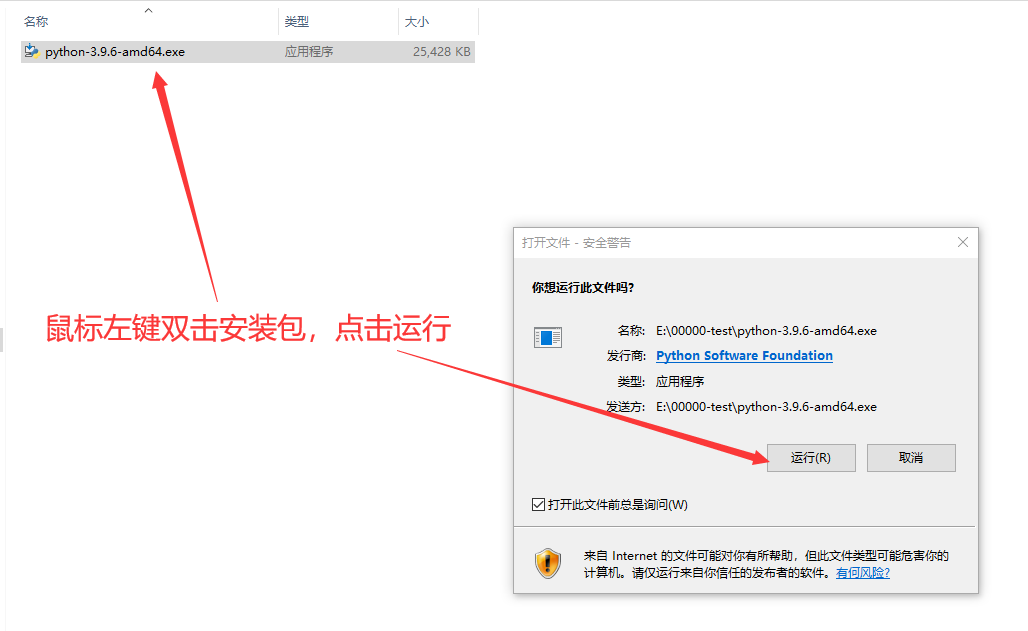
Python3安装步骤1.1
1.2、在下方Add Python 3.9 to Path处打勾,
并选择自定义安装
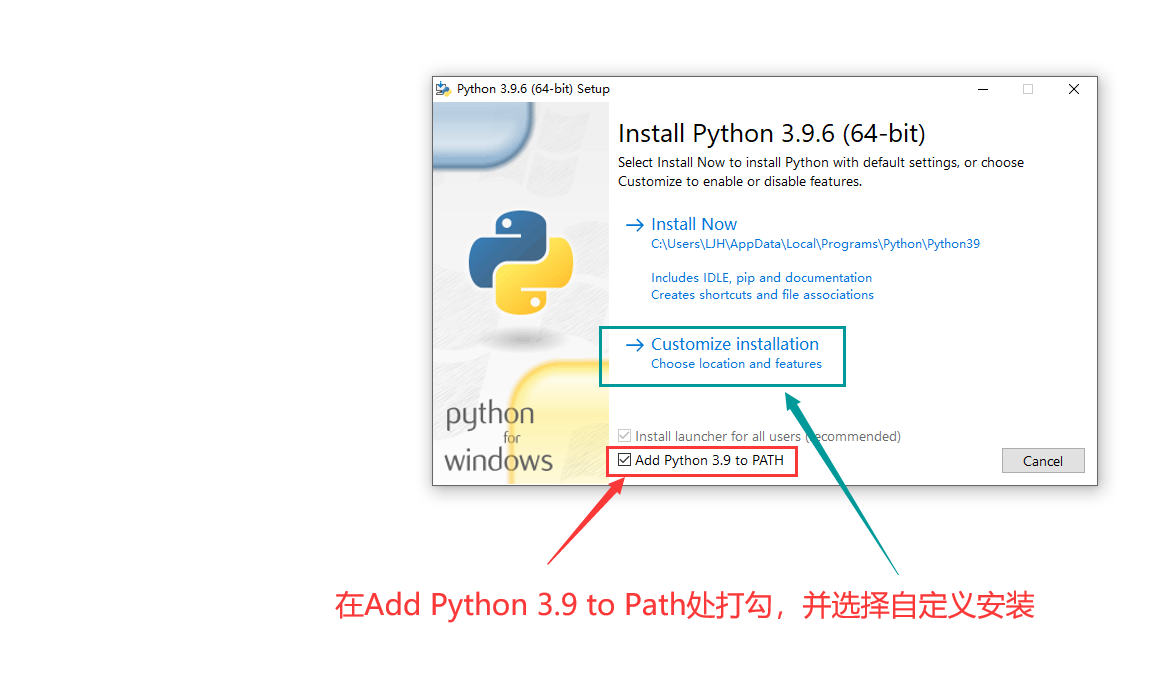
Python3安装步骤1.2
1.3、选择Next
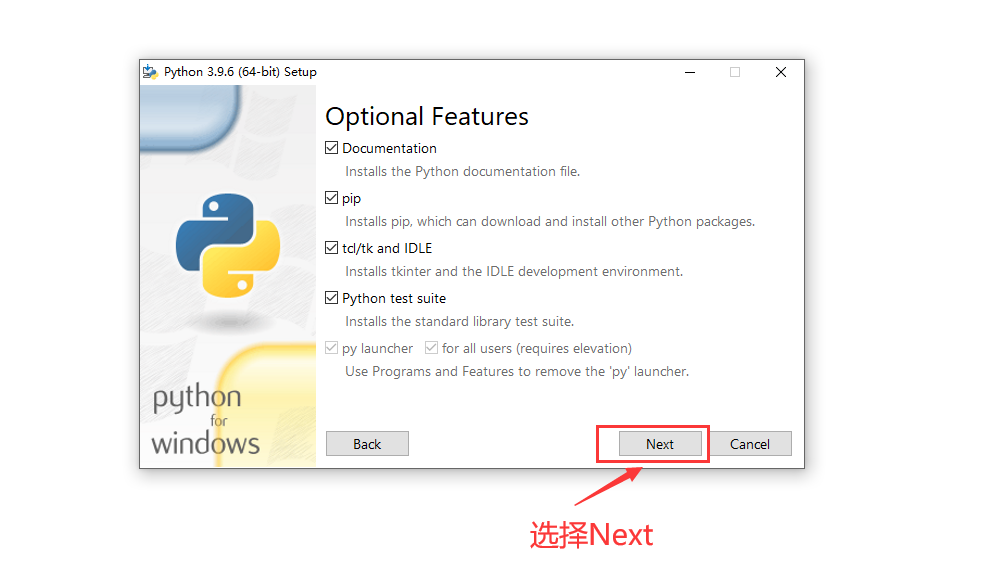
Python3安装步骤1.3
1.4、Browse可选择自定义安装位置,
然后点击Install安装
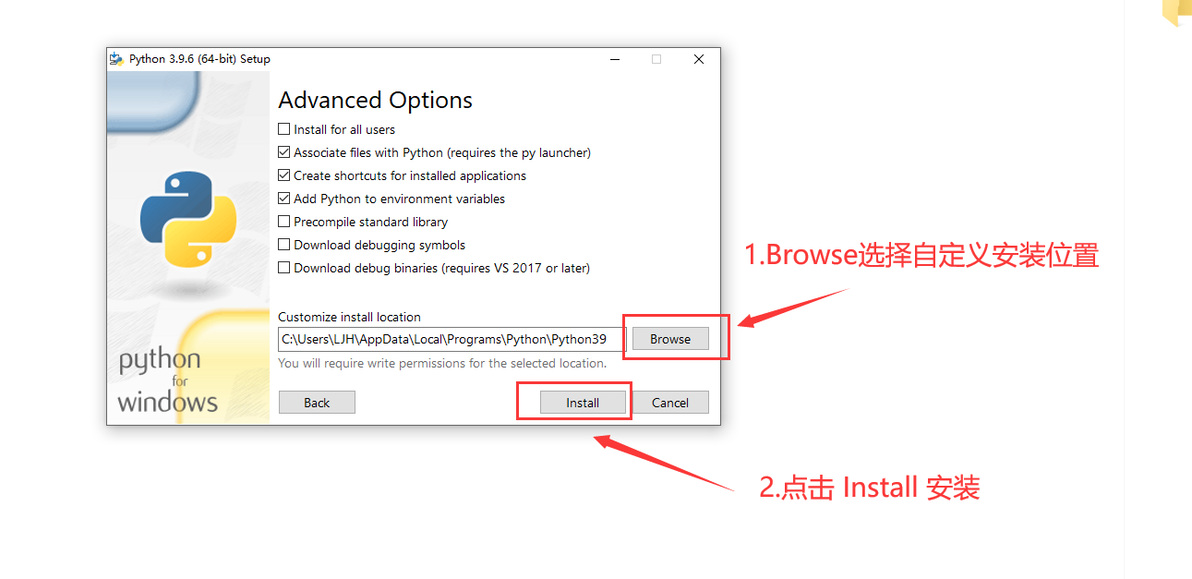
Python3安装步骤1.4
1.5、Pythona安装完成,点击Close关闭窗口
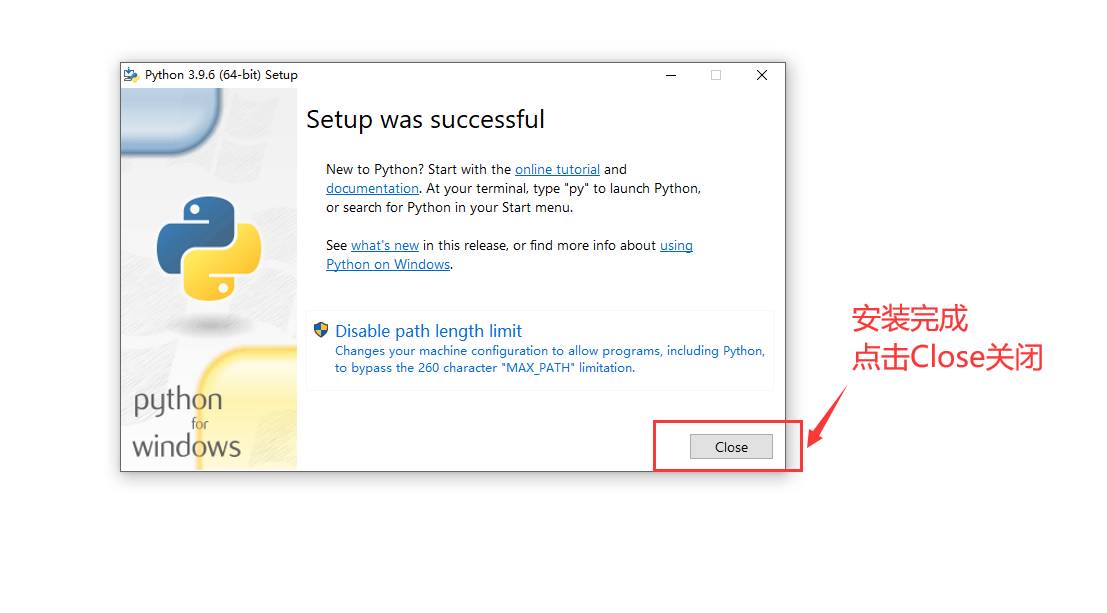
Python3安装步骤1.5
步骤二:安装scenedetect[opencv]模块
2.1通过按快捷键Win + R,
打开运行窗口
输入cmd
快速打开cmd窗口
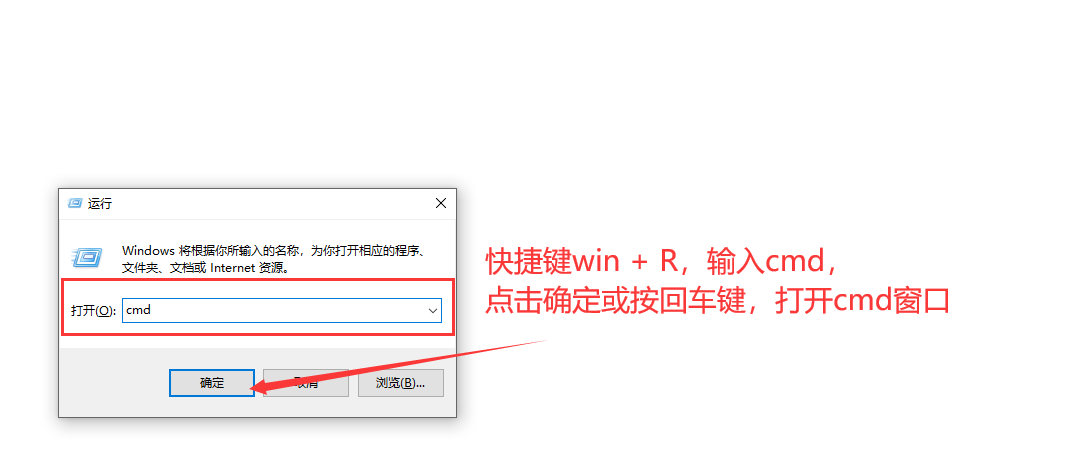
打开cmd窗口
2.2在cmd窗口输入 pip list 可以查看Python3已安装的模块
(注:未安装Python,pip指令无法使用)
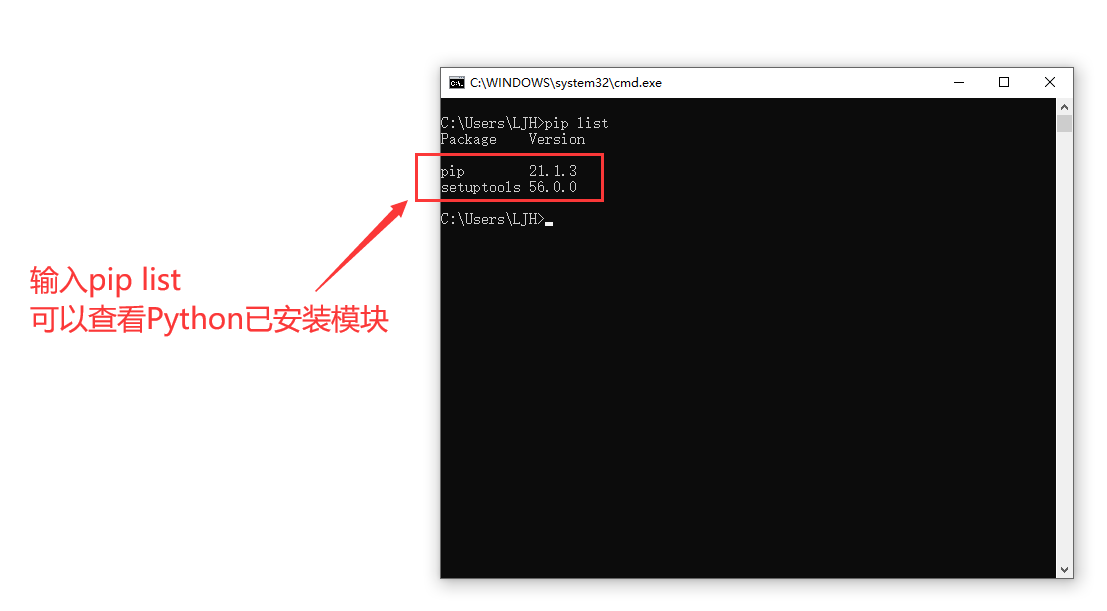
查看Python3已安装模块
2.3在cmd窗口输入以下命令安装场景检测所需模块
pip install scenedetect[opencv]
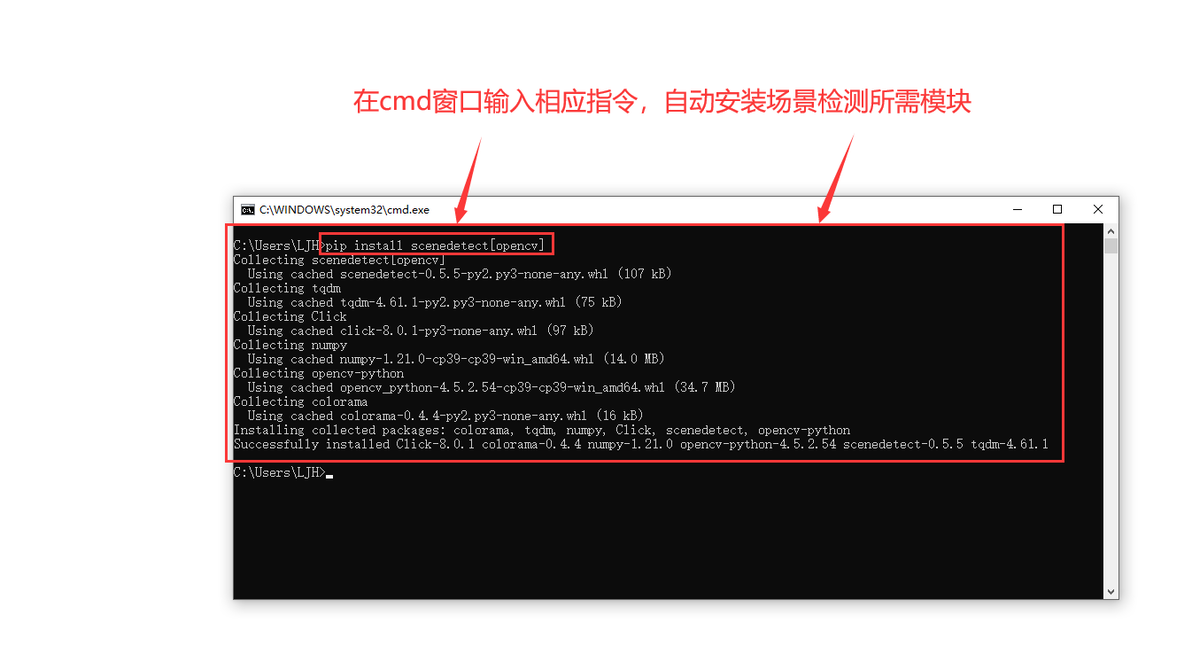
安装场景检测所需模块
2.4可以通过步骤2.2相应操作,
检验是否已安装场景检测所需模块:
click
colorama
numpy
opencv-python
scenedetect 0.5.5
tqdm
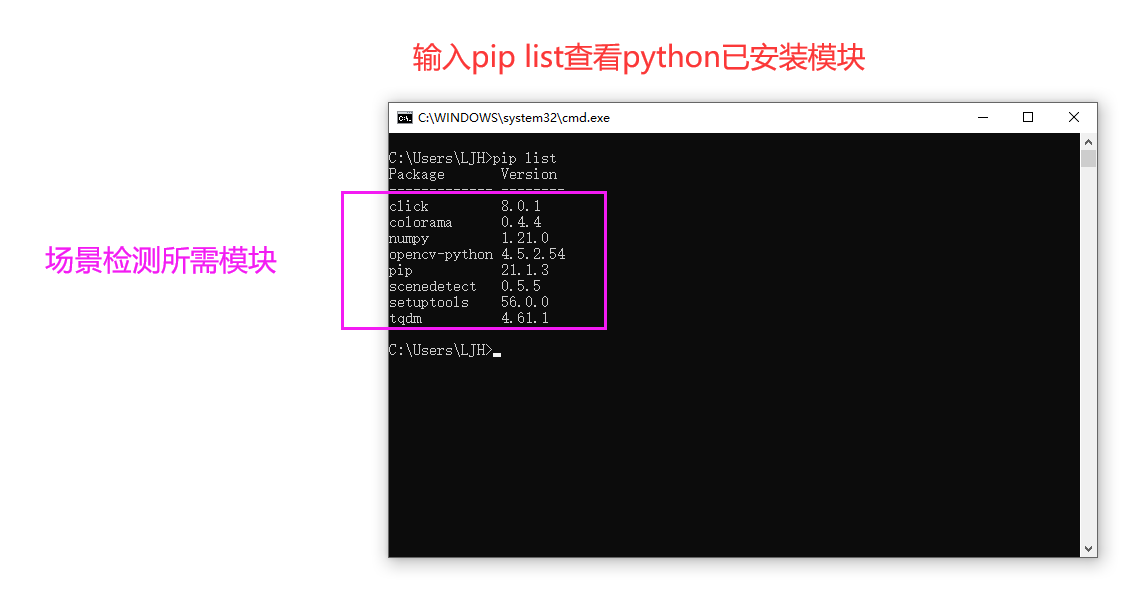
检验场景检测所需模块
步骤三:场景检测,
批量制作html预览网页
3.1将要制作成预览网页的视频,
放置在不含中文路径下
(视频存储路径含中文,某些批处理指令可能会失效)
(建议视频文件名也改成非中文名称)
(文件名后期可以使用文件重命名工具(ReNamer)7.2批量改回)
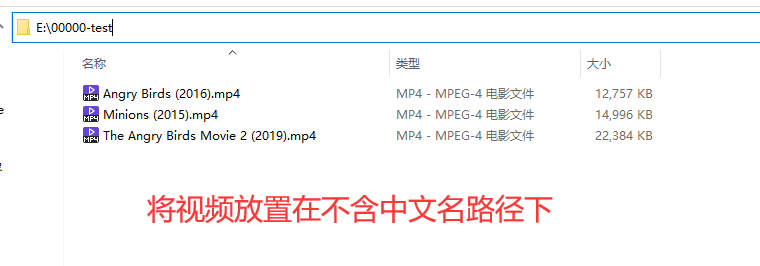
视频存放位置推荐
3.2、在视频存放路径目录下,
鼠标右键,新建一个文本文档(也叫txt文档)
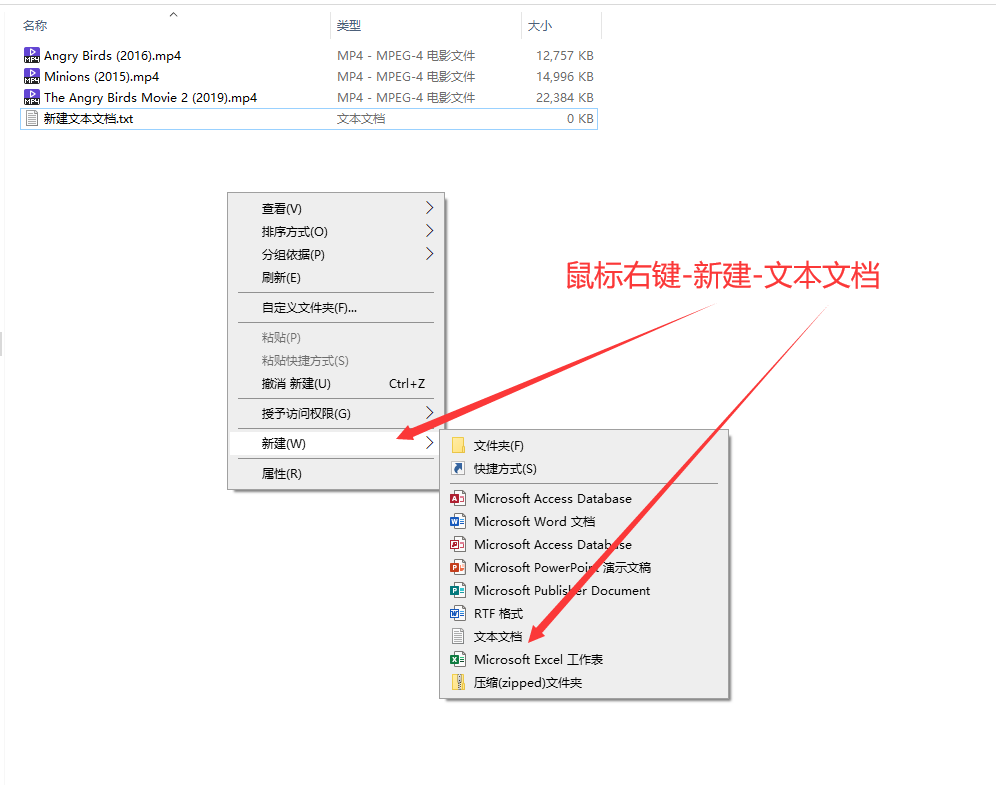
新建txt空白文档
3.3、在txt文档中,输入以下批处理指令:
for %%i in (*) do scenedetect -i "%%i" -s "%%i.stats.csv" detect-content -t 27 list-scenes save-images -n 1 -p -o "%%i_Output_dir" export-html -w 400
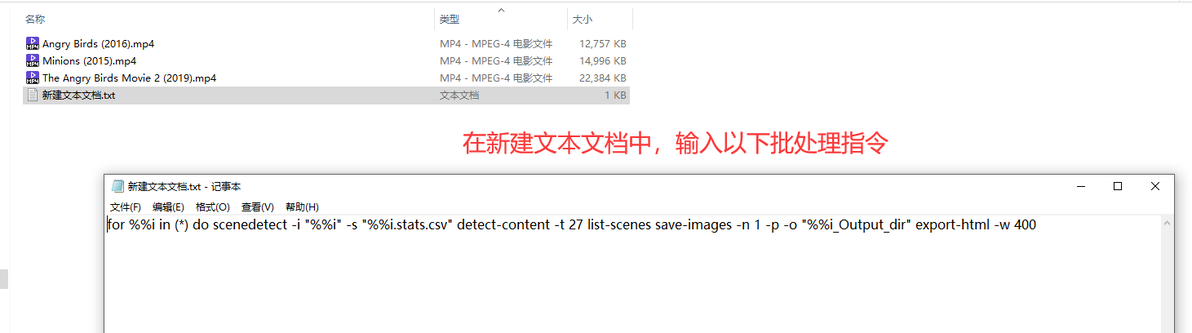
在txt文本中输入批处理指令
然后将文件后缀拓展名txt改为bat
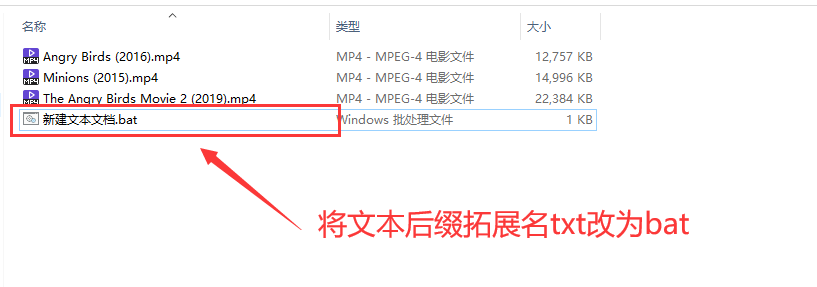
文本后缀拓展名txt改为bat
3.5、鼠标左键双击bat文件,生成html预览网页文件
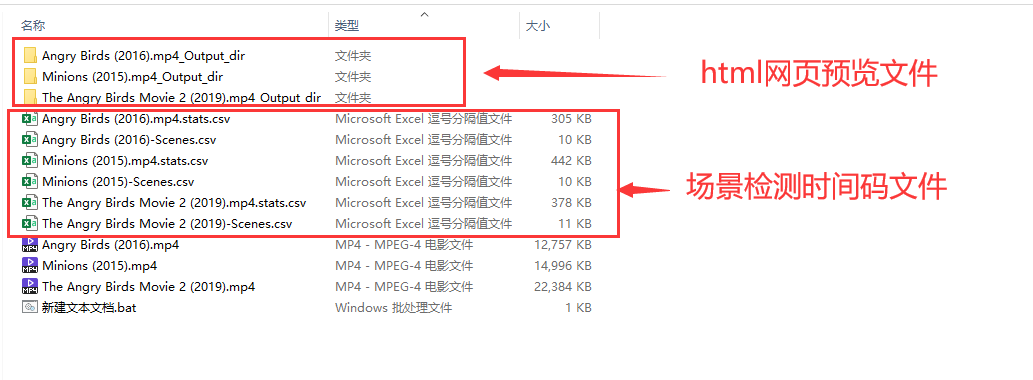
生成html网页预览文件
3.6、鼠标左键双击打开html预览网页
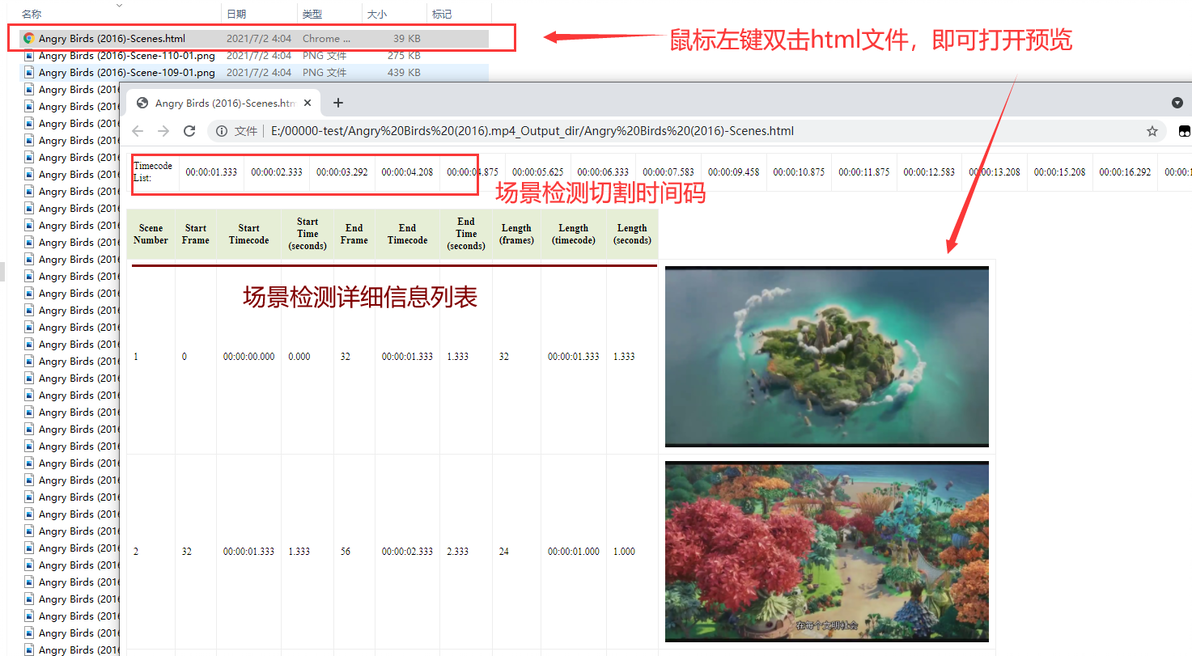
html预览网页
以上效果满意的
以下内容可忽略
四、补充(参数)说明:
4.1、for循环说明:
本教程使用的是批处理for循环
for %%i in () do
4.11、for循环命令语句在不同环境下表现出来的行为虽然基本一样,
但是在细节上还是稍有不同。
在cmd窗口中:
FOR %variable IN (set) DO command [command-parameters]
在批处理文件中:
FOR %%variable IN (set) DO command [command-parameters]
两者最明显的一个差异就是:
在cmd窗口中,for之后的形式变量i必须使用单百分号引用,即%i;
而在批处理文件中,引用形式变量i必须使用双百分号,即%%i。
4.12、for语句的基本要素:
1、for、in和do是for语句的关键字,它们三个缺一不可;
2、%%i是for语句中对形式变量的引用,
就算它在do后的语句中没有参与语句的执行,也是必须出现的;
3、in之后,do之前的括号不能省略;
4、set表示字符串或变量,command表示字符串、变量或命令语句;
4.13、for语句的注意事项:
1、for语句的形式变量i,
可以换成26个字母中的任意一个,
这些字母会区分大小写,
也就是说,%%I和%%i会被认为不是同一个变量;
2、in和do之间的set表示的字符串或变量可以是一个,也可以是多个,
每一个字符串或变量,我们称之为一个元素,
每个元素之间,用空格键、跳格键、逗号、分号或等号分隔;
3、for语句依次提取set中的每一个元素,
把它的值赋予形式变量i,
带到do后的command中参与命令的执行;
并且每次只提取一个元素,然后执行一次do后的命令语句,
而无论这个元素是否被带到command中参与了command的运行;
当执行完一次do后的语句之后,
再提取set中的下一个元素,再执行一次command,
如此循环,直到set中的所有元素都已经被提取完毕,该for语句才宣告执行结束;
其中,第3点是最为关键的,它描述了for语句的执行过程,是for语句的精髓所在
4.2、批处理通配符说明:
通配符(?和*)常用来代替未具体指明的文件和数据。
?代表单个字符。
* 代表全部字符。
4.3、批处理双引号''说明:
如果调用bat时文件名有特殊字符,执行出错
那么需要将参数放在双引号"%%i"中,
4.4、PySceneDetect场景检测各模块说明
4.4.1、Global Options(全局选项)
用法:
scenedetect [OPTIONS] COMMAND1 [ARGS]... [COMMAND2 [ARGS]...]...
[OPTIONS]——选项:
-i, --input VIDEO——
[必需] 输入视频文件。
-o, --output DIR ——
所有文件的输出目录。
-f, --framerate FPS——
强制帧率,以帧/秒为单位(例如 -f 29.97)。
-d, --downscale N ——
将帧缩小的整数因子(例如 2, 3, 4 ...),
其中帧被缩放到宽度/N x 高度/N(因此 -d 1 意味着没有缩小)。
每个增量将处理速度提高 4 倍(例如,-d 2 比 -d 1 快 4 倍)。
较高的值可用于对精度影响最小的高清内容。
[默认:2 为 SD,4 为 720p,6 为 1080p,12 为 4k]
-fs, --frame-skip N——
在处理过程中跳过 N 帧
(-fs 1 每隔一帧跳过一次,处理 50% 的视频,
-fs 2 处理 33% 的帧,-fs 3 处理 25%,等等。 .)
以牺牲准确性为代价降低处理速度。
[默认值:0]
-m, --min-scene-len TIMECODE——
任何场景的最小尺寸/长度。
时间码可以指定为精确的帧数、以秒为单位的时间后跟 s,
或格式为 HH:MM:SS 或 HH:MM:SS.nnn 的时间码
[默认:0.6s]
--drop-short-scenes——
丢弃比 `--min-scene-len` 短的场景,而不是将它们与邻居组合
-s, --stats CSV——
用于写入帧指标的统计文件 (.csv) 的路径。
如果文件存在,将处理任何指标,否则将创建一个新文件。
可用于确定各种场景检测器选项的最佳值,
并缓存帧计算以加速多个检测运行。
-v, --verbosity LEVEL——
要显示的调试/信息/错误信息的级别。
设置为 none 将抑制除操作生成的所有输出
(例如时间码列表输出)。
-l, --logfile LOG——
用于写入应用程序日志信息的日志文件路径,主要用于调试。
如果您要提交错误报告,请确保也设置“-il debug”。
-q, --quiet——
抑制 PySceneDetect 的所有输出,但来自指定命令的输出除外。
等效于设置“--info-level none”,并覆盖当前信息级别,
即使指定了--info-level/-il。
-h, --help——
显示此消息并退出
4.4.2、time Command(时间命令)
用法:
scenedetect time [OPTIONS]
设置输入视频的开始/结束/持续时间。
时间值可以指定为帧 (NNNN)、秒 (NNNN.NNs)
或时间码 (HH:MM:SS.nnn)。
[OPTIONS]——选项:
s, --start TIMECODE——
视频中开始检测场景的时间。
TIMECODE 可以指定为确切的帧数
(-s 100 从第 100 帧开始),
时间以秒为单位,后跟 s
(-s 100s 从 100 秒开始),
或格式为 HH:MM:SS
或 HH:MM:SS.nnn 的时间码
(-s 00:01:40 从 1 分 40 秒开始)。
[默认值:0]
-d, --duration TIMECODE——
处理视频的最长时间
TIMECODE 格式与其他参数相同。
与 --end / -e 互斥。
-e, --end TIMECODE——
视频中结束检测场景的时间。
TIMECODE 格式与其他参数相同。
与 --duration / -d 互斥。
-h, --help——
显示此消息并退出。
4.4.3、detect-content Command(内容检测命令)
用法:
scenedetect detect-content [OPTIONS]
对输入视频执行内容检测算法。
[OPTIONS]——选项:
-t, --threshold VAL——
delta_hsv 帧度量必须超过以触发新场景的阈值(浮点数)。
指 stats 文件中的帧度量 delta_hsv_avg。
[默认值:30.0]
说明:内容感知场景检测器会找到两个后续帧之间的差异超过设置的阈值
-h, --help——
显示此消息并退出。
4.4.4、detect-threshold Command(阈值检测命令)
用法:
scenedetect detect-threshold [OPTIONS]
对输入视频执行阈值检测算法。
[OPTIONS]——选项:
-t, --threshold VAL——
delta_rgb 帧度量必须超过以触发新场景的阈值(整数)。
指 stats 文件中的帧度量 delta_rgb。
[默认值:12]
说明:通过将当前帧的强度/亮度与设置的阈值进行比较,
并在该值超过阈值时触发场景切换/中断.
在 PySceneDetect 中,
该值是通过对帧中每个像素的 R、G 和 B 值求平均值来计算的,
产生一个表示平均像素值(从 0.0 到 255.0)的单个浮点数。
-f, --fade-bias PERCENT——
时间码偏斜从 -100 到 100 的百分比 (%),用于放置剪切。
-100 表示开始帧,+100 表示结束帧,0 是两者的中间。
[默认值:0]
-l, --add-last-scene ——
如果设置,如果视频以淡出结束,
则会为最后一个淡出位置生成一个额外的场景。
-p, --min-percent——
百分比 (%) 从 0 到 100 的像素数量必须满足阈值
才能触发场景更改。
[默认值:95]
-b, --block-size N——
图像中每次迭代求和的行数(在某些情况下可以调整性能)。
[默认值:8]
-h, --help —— 显示此消息并退出。
4.4.5、list-scenes Command(场景列表命令)
用法:
scenedetect list-scenes [OPTIONS]
打印场景列表并输出到 CSV 文件。
默认文件名是 $VIDEO_NAME-Scenes.csv。
[OPTIONS]——选项:
-o, --output DIR——
用于保存视频的输出目录。
如果设置,则覆盖全局选项 -o/--output。
-f, --filename NAME——
用于场景列表 CSV 文件的文件名格式。
您可以在文件名中使用 $VIDEO_NAME 宏。
请注意,您可能必须使用单引号将名称括起来。
[默认:$VIDEO_NAME-Scenes.csv]
-n, --no-output-file——
禁止将场景列表 CSV 文件写入磁盘。
如果设置,-o/--output 和 -f/--filename 将被忽略。
-q, --quiet——
禁止 list-scenes 命令打印的表的输出
-s, --skip-cuts——
跳过输出切割列表作为 CSV 文件的第一行。
如果需要符合 RFC 4810,请设置此选项。
4.4.5、save-images Command(保存图像命令)
用法:
scenedetect save-images [OPTIONS]
为每个检测到的场景创建图像。
[OPTIONS]——选项:
-o, --output DIR——
用于保存图像的输出目录。
如果设置,则覆盖全局选项 -o/--output。
-f, --filename NAME——
文件名格式,*无* 扩展名,用于保存图像文件。
您可以在文件名中使用 $VIDEO_NAME、$SCENE_NUMBER、
$IMAGE_NUMBER 和 $FRAME_NUMBER 宏。
请注意,您可能必须将格式括在单引号中。
[默认:$VIDEO_NAME-Scene-$SCENE_NUMBER-$IMAGE_NUMBER]
-n, --num-images N——
要生成的图像数量。
将始终包括开始/结束帧,
除非 N = 1,在这种情况下,图像将是场景中点的帧。
-j, --jpeg——
将输出格式设置为 JPEG。
[默认]
-w, --webp——
设置输出格式为 WebP。
-q, --quality Q——
JPEG/WebP 编码质量,从 0-100(越高表示质量越好)。
对于 WebP,100 表示无损。
[默认:JPEG:95,WebP:100]
[0<=x<=100]
-p, --png——
将输出格式设置为 PNG。
-c, --compression C——
PNG 压缩率,从 0-9。
较高的值会产生较小的文件,但会导致较长的压缩时间。
此设置不会影响图像质量,只会影响文件大小。
[默认值:3]
[0<=x<=9]
-m, --frame-margin N——
保存图像时在场景开始和结束时要忽略的帧数
[默认值:1]
-s --scale S——
重新缩放保存图像的可选因子。
缩放因子为 1 不会导致重新缩放。
值 <1 导致保存的图像更小,而值 >1 导致图像大于原始图像。
如果指定了高度 -h 或宽度 -w 值,则忽略此值。
-h --height H——
保存图像高度的可选值。
无论纵横比如何,同时指定高度和宽度 -w 会将图像调整为精确大小。
仅指定高度会将图像重新缩放到该高度的像素数,同时保留纵横比。
-w --width W——
保存图像宽度的可选值。
无论纵横比如何,同时指定宽度和高度 -h 会将图像调整为精确大小。
仅指定宽度会将图像重新缩放到该像素宽度,同时保留纵横比。
4.4.6、export-html Command(导出html命令)
用法:
scenedetect.py export-html [OPTIONS]
将场景列表导出到 HTML 文件。
默认情况下需要保存图像。
[OPTIONS]——选项:
-f, --filename NAME——
用于场景列表 HTML 文件的文件名格式。
您可以在文件名中使用 $VIDEO_NAME 宏。
请注意,您可能必须使用单引号将格式名称括起来。
[默认:$VIDEO_NAME-Scenes.html]
--no-images——
导出包含或不包含已保存图像的场景列表。
-w, --image-width pixels——
生成的 HTML 表中图像的宽度(以像素为单位)。
-h, --image-height pixels——
生成的 HTML 表中图像的高度(以像素为单位)。
4.4.7、split-video Command(分割视频命令)
用法:
scenedetect split-video [OPTIONS]
使用 ffmpeg 或 mkvmerge 拆分输入视频。
[OPTIONS]——选项:
-o, --output DIR——
用于保存视频的输出目录。
如果设置,则覆盖全局选项 -o/--output。
-f, --filename NAME——
文件名格式,保存图像文件时使用。
您可以在文件名中使用 $VIDEO_NAME 和 $SCENE_NUMBER 宏。
请注意,您可能必须使用单引号将名称括起来。
[默认:$VIDEO_NAME-Scene-$SCENE_NUMBER]
-h, --high-quality——
以更高质量编码视频,如果存在,则覆盖 -f 选项。
相当于指定 --rate-factor 17 和 --preset slow。
-a, --override-args ARGS——
在分割和重新编码场景时覆盖传递给 FFmpeg 的编解码器参数/选项。
在指定的参数周围使用双引号 (")。
必须至少指定要使用的音频/视频编解码器
(例如 -a "-c:v [...] 和 -c:a [...]")。
[默认值:“-c:v libx264 -preset veryfast -crf 22 -c:a copy”]
-q, --quiet——
抑制来自外部视频分割工具的输出。
-c, --copy——
复制而不是使用 mkvmerge 重新编码而不是 ffmpeg 来分割视频。
在此模式下,除了 -o/--output 和 -q/--quiet 之外的所有其他参数都将被忽略,
并且输出文件将被命名为 $VIDEO_NAME-$SCENE_NUMBER.mkv。
分割视频时明显更快,但是,有时可能无法准确分割输出视频,
尤其是在场景长度非常短或输入视频被严重压缩的情况下。
这可能会导致较小的场景与其他场景合并,或者场景边界会及时移动 -
因此在使用此选项时,写入的视频数量可能与检测到的场景数量不匹配。
-crf, --rate-factor RATE——
视频编码质量(x264 恒定速率因子),
从 0 到 100,其中较低的值代表更好的质量,0 表示无损。
[默认值:22,如果设置了 -h/--high-quality:17]
-p, --preset LEVEL——
视频压缩质量预设(x264 预设)。
可以是以下之一:超快、超快、非常快、更快、快、中、慢、慢和非常慢。
更快的模式运行所需的时间更少,但输出文件可能更大。
[默认值:非常快,如果设置了 -h/--high 质量:慢]
参考:
1.批处理-For详解
https://blog.csdn.net/weixin_34009794/article/details/85815189
2.PySceneDetect v0.5.5 手册
https://pyscenedetect.readthedocs.io/projects/Manual/en/latest/
3.【春星开讲】批量自动切分电影镜头然后截图并制作为网页
——工具人APPA
