

1. there are actually three ADaM standard data structures:
the subject-level analysis dataset (ADSL)
the Basic Data Structure (BDS)
the Occurrence Data Structure (OCCDS)
其中,
ADSL : 试验参与者级别分析数据集。特点:每个患者仅包含一条记录。用于记录患者的非时间变化性信息。
BDS: 基本数据结构。 特点:按照每个患者 每个参数 每个时间点 占用一条记录的结构。一般记录发现类中的数据或有效性数据。
OCCDS:发生数据结构。特点:按照分层结构进行记录。 用于记录副作用、既往药物史等。
2. There is also much more room for personal discretion in creating ADaM datasets than their corresponding SDTM datasets.
3. ADaM datasets contain both source and derived data
4. analysis Data Model (ADaM) datasets are much more flexible than SDTM (Study Data Tabulation Model) datasets, but they are also more complex.
5. ADaM datasets must also be analysis-ready and contain traceability between ADaM and SDTM
6. ADaM is not perfect and it does not always provide the necessary data that easily supports all necessary analyses for review
7. All ADaM datasets, however, must pass validation by using Pinnacle 21 (formerly as OpenCDISC) Validator before NDA submission.

Several factors will impact the quality of ADaM datasets (影响ADaM的质量) – (1). personal preference, (2). fully understanding of the needs of the specific study requirements, (3). the optimum number of analysis datasets to be generated, and (4). the degree of self- sufficiency to allow analysis and review with minimum programming or data processing, i.e. one proc away or analysis-ready.

生成ADaM需要阅读参考的文献:


THREE ADAM DATA STRUCTURES:
There are three ADaM standard data structures: 1. The subject-level analysis dataset (ADSL), 2. The Basic Data Structure (BDS), and 3. The Occurrence Data Structure (OCCDS).
The ADaMIG document only describes the first two ADaM standard data structures and the third one is in a separate document – “ADaM Data Structure for Occurrence Data”.
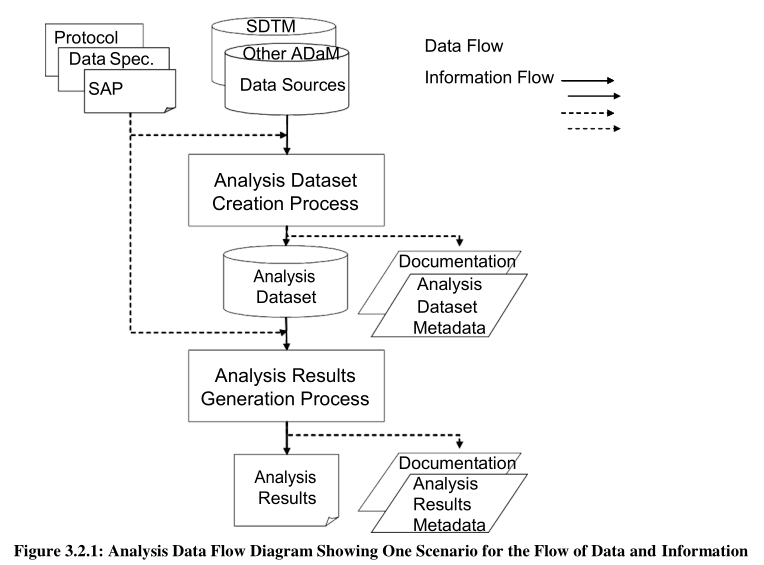
Generate the SUBJECT-LEVEL analysis dataset ( ADSL )
ADSL数据集结构中每个受试者都有一条记录,并包含一些变量,如受试者水平人群标志、计划和实际治疗变量、人口信息、随机化因素、亚组变量和重要日期。ADSL包含必需的变量(如ADaMIG中指定的)以及其他在描述受试者在试验中的经历时很重要的受试者水平变量。即使没有提交其他分析数据集,基于CDISC的临床试验数据提交也需要ADSL及其相关元数据。

无论临床实验设计是何种类型,受试者水平分析数据集 (ADSL)的结构是每个受试者一条记录。ADSL用于提供描述受试者属性的变量。这种结构允许其与其他任何数据集(包括SDTM和分析数据集)进行简单的合并。
ADSL 旨在提供有关受试者的描述性信息。它可以用于多种类型的分析,包括描述性分析、分类分析和建模。
ADSL是用于 其他分析数据集 的 受试者水平变量 的主要来源,例如人群标记和治疗变量。当合并ADSL到其他分析数据集时,只应包含那些与该分析数据集相关的领域。
ADSL的结构的金标准:
The structure of subject-level analysis dataset (ADSL) contains one record per subject regardless of the type of clinical trial design. This is the golden rule(金标准) that every programmer must follow.
Each study must have only one ADSL as a starting point in terms of the ADaM build. ADSL is a central location for important variables that describe a subject’s experience in the trial, which can then be used in all types of analysis.
For example, the variable SAFFL (Safety Population Flag) would be used for a variety of efficacy analyses and safety analyses.
两个ADaMIG版本的比较:
1. In ADaMIG v1.0, the standard variables that are required to be in every ADSL fall into five categories. V1.0的 standard variables分为 five categories。
2. The ADaMIG v1.1 not only includes two more categories – Dose Variables and Subject-Level Trial Experience Variables, but also brings more group variables such as REGIONy, AGEGRy, and TSEQPGy, etc., which are certainly helpful for subgroup analysis.
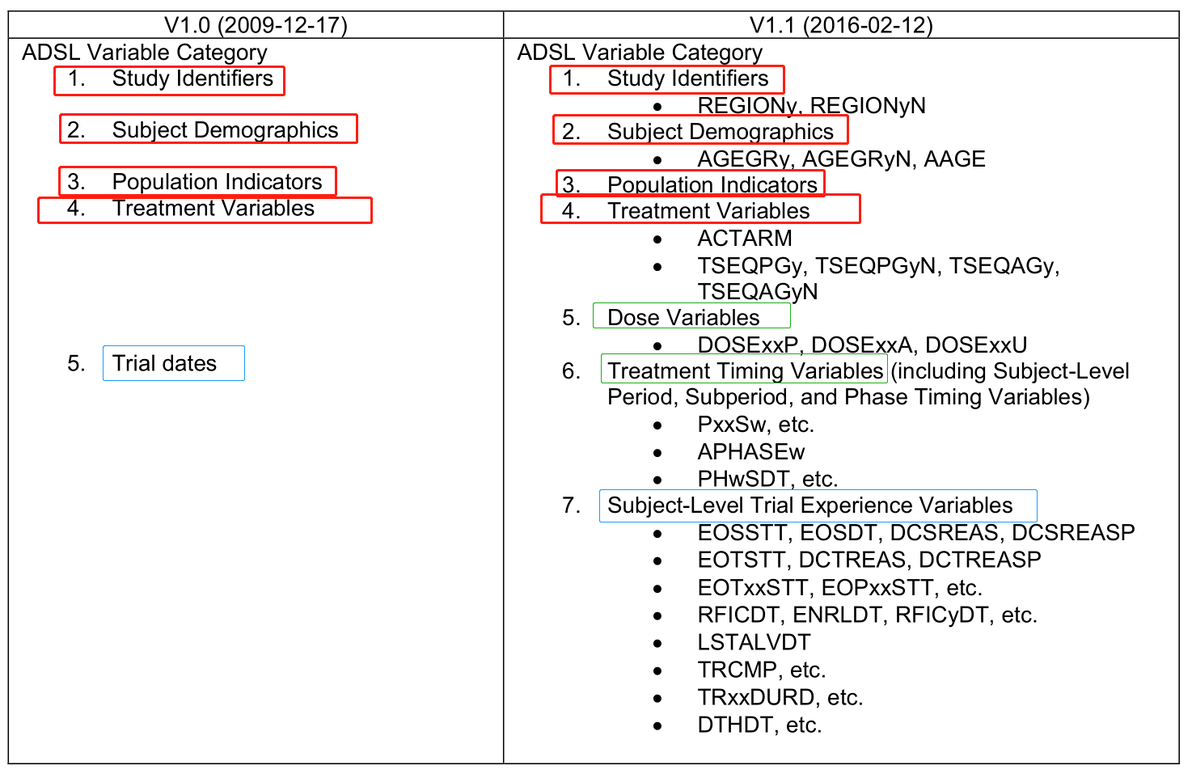
Here is the comparison of the two ADaM versions (v1.0 & v1.1) in term of ADSL. Some new group variables are listed here as well.
标准 ADSL 变量
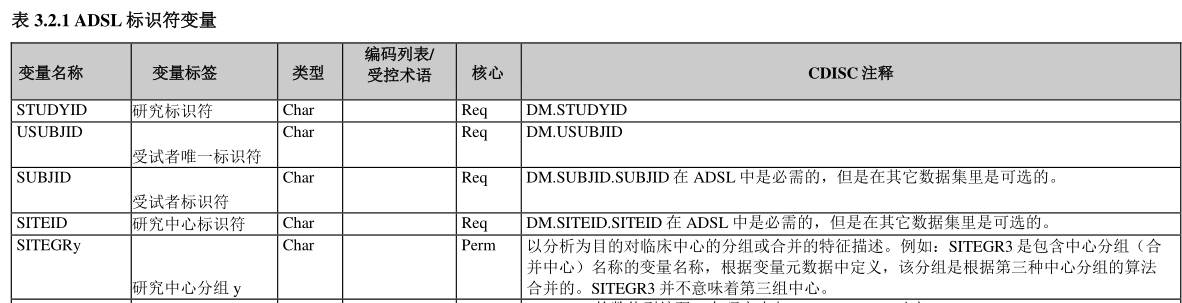
Table 3.2.1 ADSL Identifier Variable
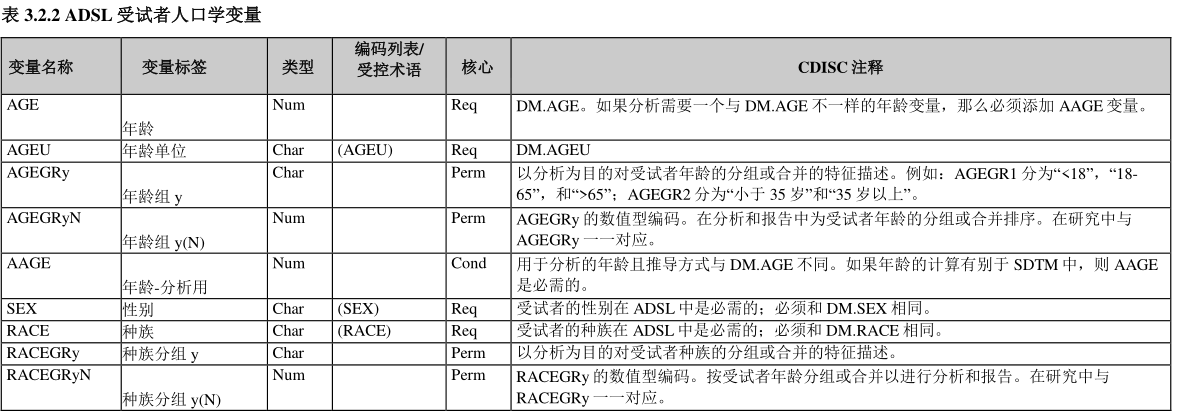
Table 3.2.2 ADSL Subject Demographics Variables
Table 3.2.3 ADSL Population Indicator Variables
Table 3.2.4 ADSL Treatment Variables
Table 3.2.5 ADSL Dose Variables
Table 3.2.6 ADSL Treatment Timing Variables
Table 3.2.7 Subject-Level Period, Subperiod, and Phase Timing Variables
Table 3.2.8 ADSL Subject-Level Trial Experience Variables
ADSL 标识符变量
ADSL 受试者人口学变量
ADSL 人群标志变量
ADSL 治疗组变量
ADSL 服药剂量变量
ADSL 治疗时间变量
受试者级别的阶段,子阶段,和分期时间变量
ADSL 受试者级别试验经历变量
将所有的生命体征变量vital signs variables 放在一个地方: ADVS。
In real practice, some programmers like to include some vital signs variables with their values at baseline, such as height, weight, BMI, and BSA in ADSL. We personally do not recommend this way because those variables are only used for a few of tables and figures. We prefer to have all vital signs variables in one place – ADVS.
新版本ADaMIGv1.1 包含一些 trial experience variables。最好将这些变量放在ADDS,以避免ADSL含有太多变量。
The new version includes some trial experience variables such as DCSREAS (“Reason for Discontinuation from Study”) and DCTREAS (“Reason for Discontinuation of Treatment”). Keeping these variables in ADSL, would save time and reduce the number of ADaM datasets needed for a simple phase 1 study. For those complicated studies, however, it may be better to have those variables added into a new ADaM dataset such as ADDS to avoid too many variables in ADSL.
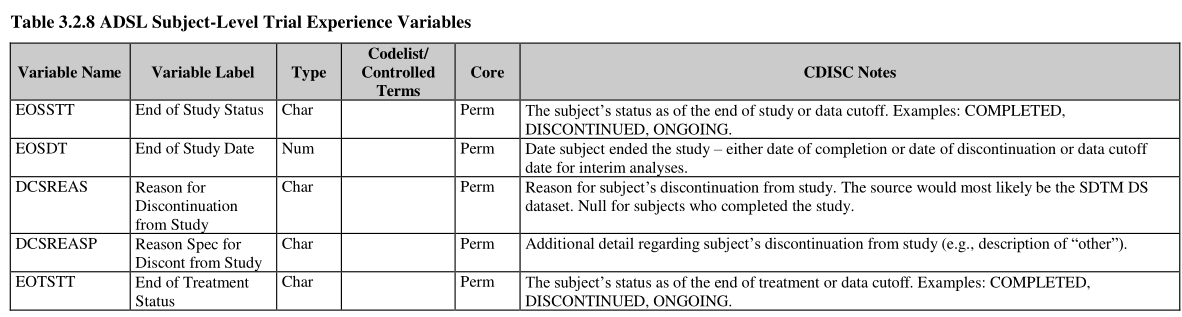
ADSL Subject-Level Trial Experience Variables ,ADSL 受试者级别试验经历变量
Some programmers like to have the numeric version of flag variables (e.g. “1”/”0” for “Yes”/”No” values). These numeric variables actually do not add any value to the dataset or programming process.
我们倾向于保留这些适用于ADSL中所有类型的表格和图表的变量。
Besides those required variables, how many conditionally required variables and permissible variables that should be added into the ADSL dataset, depend on the actual needs (e.g. how many unique tables/figures, what are their structure, etc.) of the specific study? We prefer to keep these variables that will apply for all types of tables and figures in the ADSL.
ADSL的作用:ADSL will be used to merge with some SDTM datasets to generate other ADaM datasets.
使ADaM dataset尽可能精简
A word of caution is that ADSL is not a dataset that you want to over populate(过度填充) with variables. An ADSL dataset with many variables (e.g. 50+) does not necessarily bring convenience to your programming work and data review.
It is important to keep each ADaM dataset as lean as possible and have only the necessary variables that describe attributes/experience of a subject.
所有的程序员需要站在审计统计师的立场上考虑(以加速审计)。
Please do not forget that the ultimate goal for the creation of ADaM datasets is to facilitate the regulatory review of new drug applications. All programmers need to put themselves into the regulatory statisticians’ shoes. Doing so will help get your NDA/BLA reviewed by the FDA quickly.
2. Generate the Basic Data Structure ( BDS ) Datasets
ADaM 文档介绍了 ADaM 基本数据结构,一个 BDS 数据集中,每个受试者在每个分析参数及每个分析时间点上 可包含 一条或多条记录。
分析时间点信息在特定条件下是必需的,其取决于所作分析。
在没有 分析时间点信息的情况下,结构是每个受试者每个分析参数一条或多条记录。
通常在一个研究中会创建多个 BDS 数据集,ADaMIG 在本节定义了用在 BDS 数据集中的标准变量。
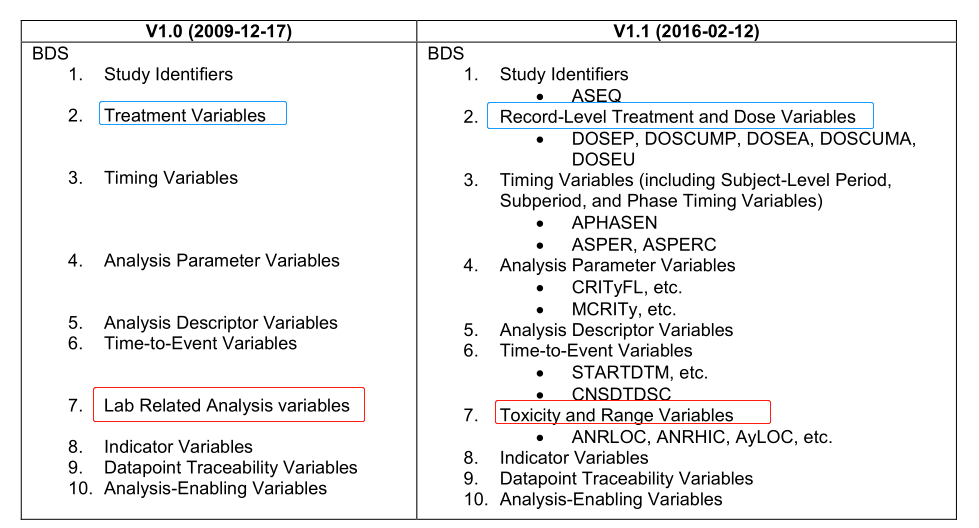
3.3.1 Identifier Variables for BDS Datasets
3.3.2 Record-Level Treatment and Dose Variables for BDS Datasets
3.3.3 Timing Variables for BDS Datasets
3.3.4 analysis Parameter Variables for BDS Datasets
3.3.5 analysis Descriptor Variables for BDS Datasets
3.3.6 Time-to-Event Variables for BDS Datasets
3.3.7 Toxicity and Range Variables for BDS Datasets
3.3.8 Indicator Variables for BDS Datasets
3.3.9 Datapoint Traceability Variables
3.3.1 BDS 数据集的标识变量
3.3.2 BDS 数据集的研究记录水平的治疗变量和剂量变量
3.3.3 BDS 数据集中的时间变量
3.3.4 BDS 数据集分析参数变量
3.3.5 BDS 数据集的分析描述符变量
3.3.6 BDS 数据集中的达到事件时间变量
3.3.7 BDS 结构数据集的毒性和范围变量
3.3.8 BDS 数据集中的标识变量
3.3.9 数据点的可追溯性变量
This type of ADaM dataset must have the variables : (1) PARAM (Parameter) and (2) AVAL (analysis Value) and/or (3) AVALC (analysis Value (C)).
PARAM 描述应足够详细以便能够清晰的解释AVAL 和/或 AVALC 的内容。PARAM 必须包括所有与参数分析目标相关的描述和限定的信息。例如单位、样本类型、位置、姿势、器械类型和转换函数,这些与分析相关的限定信息可能被包含在 PARAM 里面。
PARAM, AVAL, and AVALC
了解 SDTM 发现类变量--TEST 和 ADaM BDS 变量 PARAM 的关键区别很重要。
SDTM 的--TEST 是与其他限定符变量,例如样本类型、机器类型、身体位置等,结合起来描述收集的结果。
相反,ADaM BDS 中的变量 PARAM 是不需要任何附带的限定符变量。PARAM 是描述 AVAL 或 AVALC 的唯一变量。不允许使用任何限定符变量。
创建 PARAM 是为了满足分析需求,而不仅仅是因为收集了一些信息。该值可能是由某一类或者某几类 SDTM 域和/或某个 ADaM 数据集的任意组合的受试者数据高度衍生出来的。ARAM 描述了 AVAL 或 AVALC 中的内容。
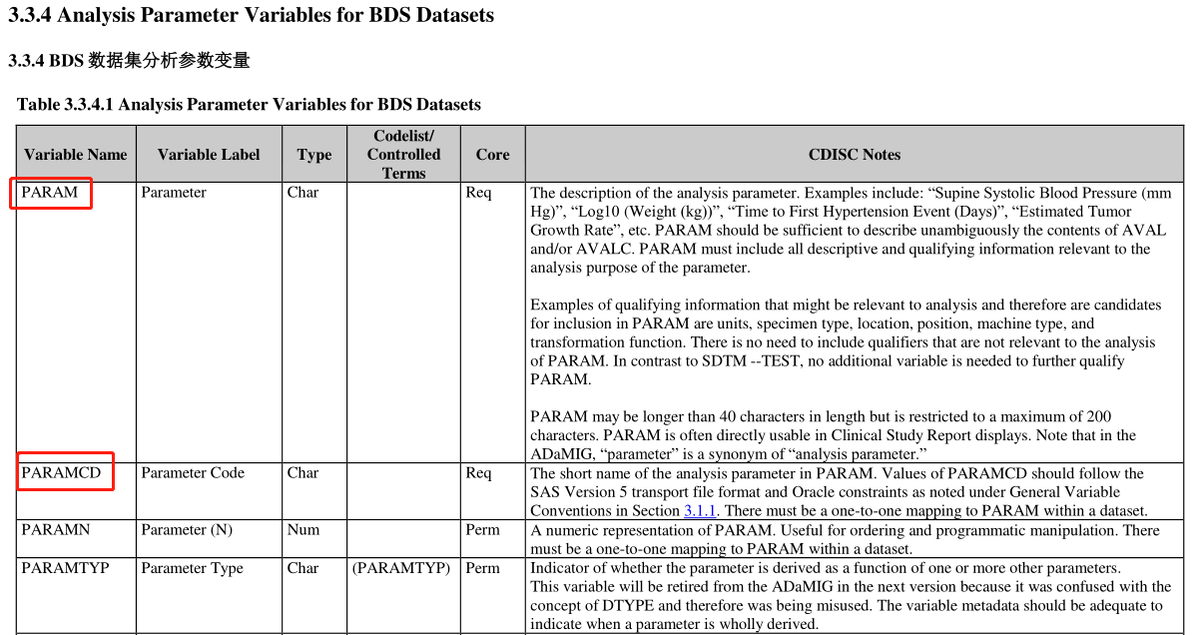
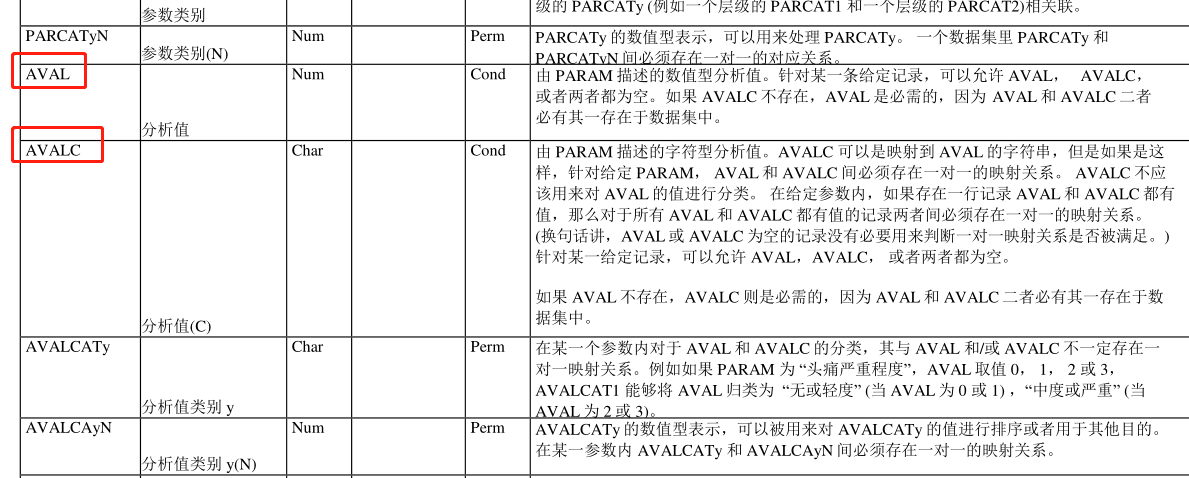
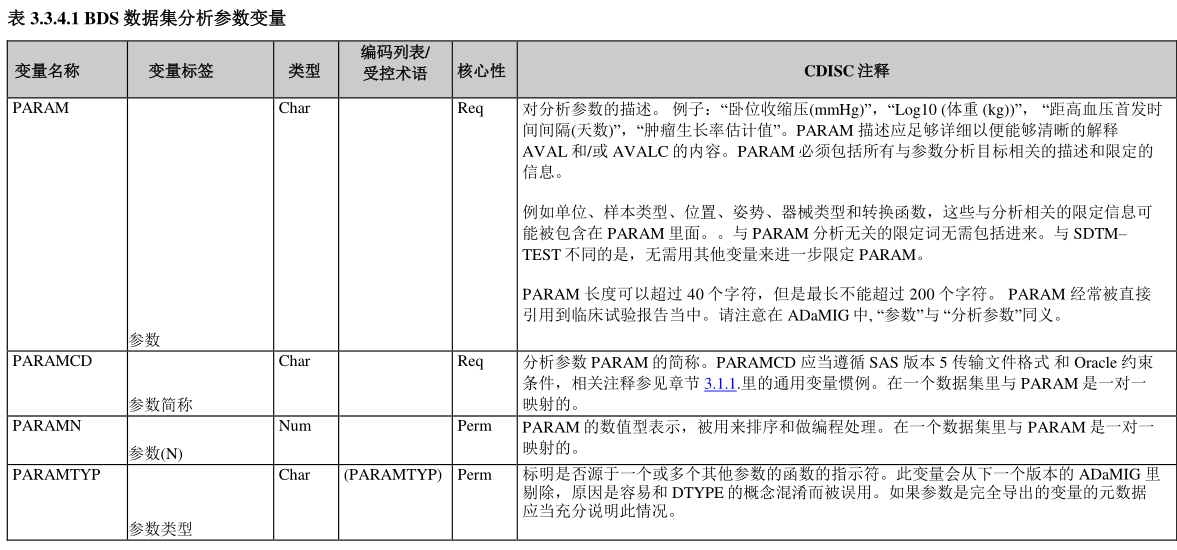
The difference between ADSL and BDS is that a subject may have one or more records in the BDS dataset. Their predecessors are the SDTM findings class datasets.( BDS dataset 的 predecessors 是 SDTM findings class datasets。)
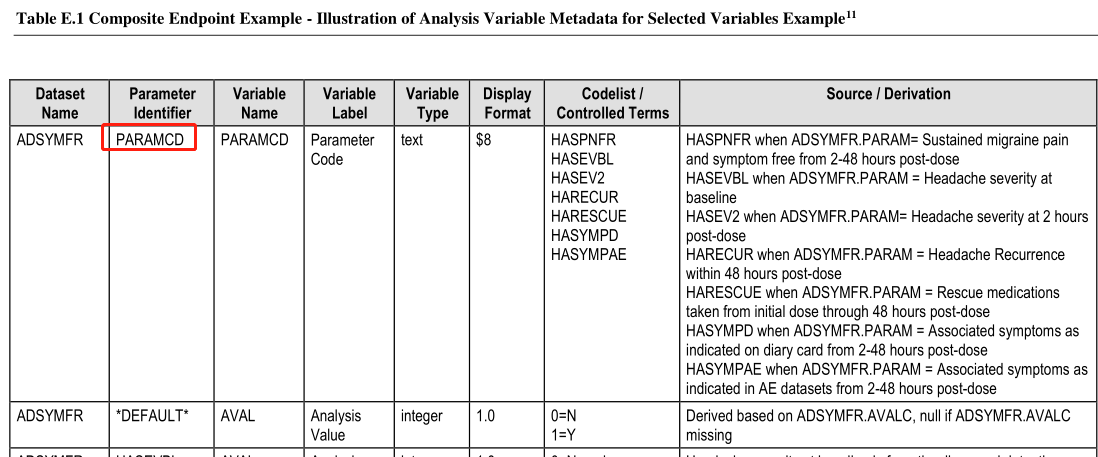
analysis Variable Metadata 表E.1 复合终点例子-选择变量的分析变量元数据的举例说明
analysis Variable Metadata分析变量元数据
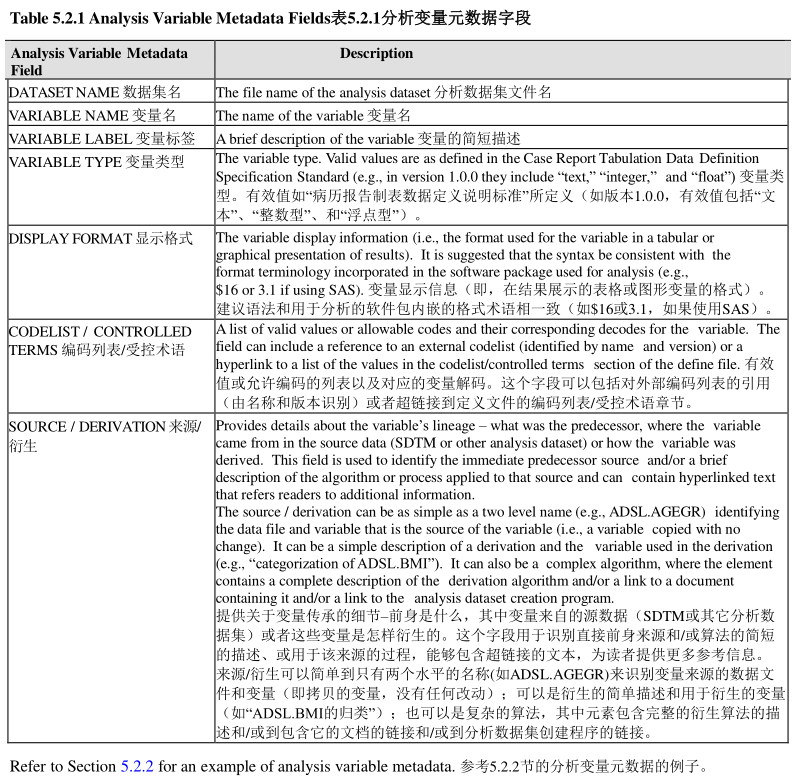
Here is the list of some of them:

All SDTM findings class datasets have a similar structure (see blow SDTM Finding Class datasets). In addition to the three common variables – STUDYID, DOMAIN, and USUBJID, they all have eight similar variables – XXSEQ, XXTESTCD, XXTEST, XXCAT, XXSCAT, XXORRES, XXSTRESC, and XXDTC. The ‘XX’ in the variable names stands for the domain name (e.g. VS) of a SDTM findings class dataset.
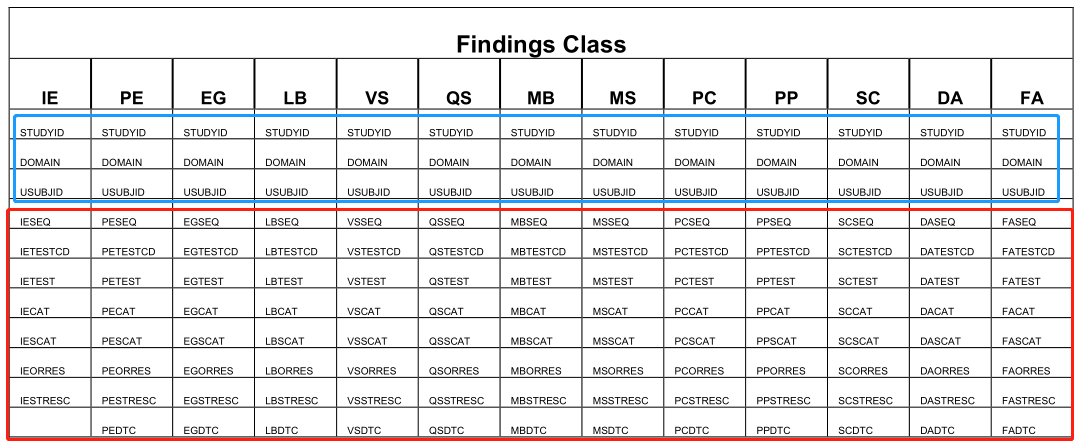
从SDTM 生成 BDS:
XXTESTCD and XXTEST are used to generate variables PARAMCD and PARAM, respectively.
XXORRES and XXSTRESC are used to generate variable AVAL or AVALC.
ADT will usually be derived from XXDTC.
Most SDTM findings class domains have variables – XXSTRESN, XXBLFL, VISITNUM, and VISIT.
If XXSTRESN is available, Variable AVAL can be generated from XXSTRESN.
Variables ABLFL, AVISITN, and AVISIT are normally derived from XXBLFL, VISITNUM, and VISIT correspondently.
Then AVAL, ABLFL, AVISITN, and AVISIT can be used to generate values for variables - BASE and CHG, etc.
The majority of other variables in this type of ADaM dataset are directly copied from ADSL and its corresponding SDTM dataset.
Some other ADaM variables mentioned in ADaMIG may be also needed depending upon the analysis needs of a specific study. For example, vital signs shift tables require variables – ANRIND (analysis Reference range Indicator) and BNRIND (baseline Reference range Indicator). So, it is quite straightforward to generate the BDS type of ADaM datasets.
There are no major differences between ADaMIG v1.0 and ADaMIG v1.1. Most of the differences are caused by the newly added ADSL variables in v1.1. The category “Lab Related analysis variables” in v1.0 has been changed to “Toxicity and Range Variables” in v1.1. Here is the comparison of the BDS parts in the two ADaM versions. Again, some new group variables are listed here as well.
Some programmers, statisticians, and clinicians do not like the BDS, which vertically presents the data. Instead, they like to have all tests in one row within the same visit for a subject in datasets such as ADLB and ADVS. We totally understand the convenience for them but the essential reason to follow the ADaM structure is that you want to have your NDA/BLA reviewed by the FDA as quickly as possible. The quicker the review and approval, the earlier your approved drug will reach the market obtaining a winning competitive advantage, and can begin to generate revenue.
3. Generate the Occurrence Data Structure ( OCCDS ) Datasets
In contrast (对比) to the BDS datasets, the OCCDS type of ADaM Datasets do not have variables PARAM (Parameter) and AVAL (analysis Value) and/or AVALC (analysis Value (C)) because they are from the SDTM interventions class 干预类 and events class 事件类 datasets.
When using these SDTM datasets to generate ADaM datasets, they do not fit in well with the BDS structure and are more appropriately analyzed using their SDTM structure with added analysis variables.
Here are the reasons from the introduction section of the ADaM document titled “analysis Data Model (ADaM) Data Structure for Adverse Event analysis” (version 1.0, 2012):
There is no need for AVAL or AVALC. Occurrences are counted in analysis, and there are typically one or more records for each occurrence.
A dictionary is used for coding the occurrence, and it includes a well-structured hierarchy of categories and terminology. Mapping this hierarchy to BDS variablesPARAM and generic *CAT variables would lose the structure and meaning of the dictionary.
Dictionary content is typically not modified for analysis purposes. In other words, there is no need for analysis versions of the dictionary hierarchy.
The most common OCCDS datasets are ADAE, ADCM, ADMH, ADEX, ADCE, and ADDS.
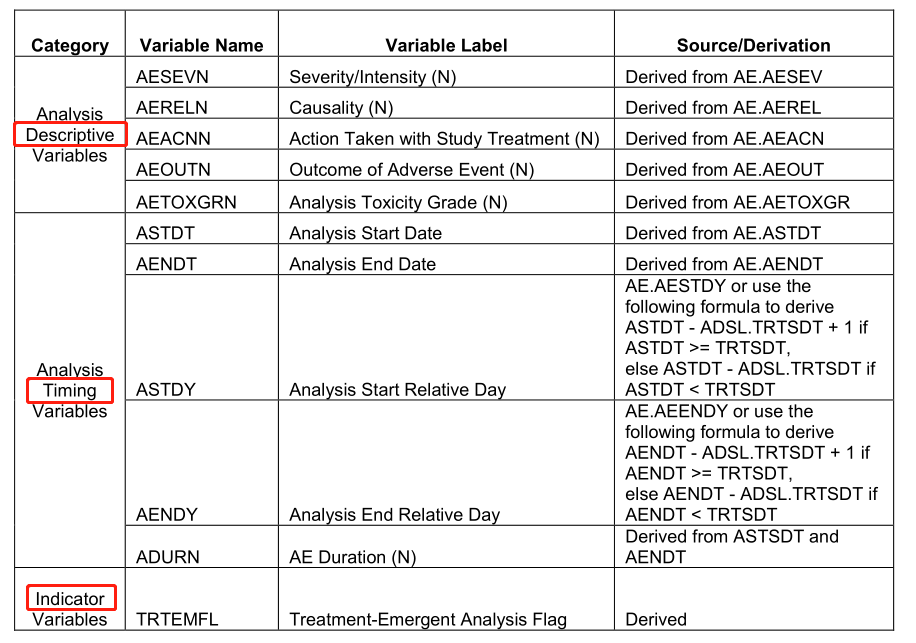
Most of the variables in this type of datasets come directly from the ADSL and its corresponding SDTM datasets such as AE, CM, MH, etc. Only a few variables that need to be created, e. g., the following numeric variables AESEVN, AERELN, AEACNN, and AEOUTN, timing variables such as ASTDT, AENDT, ASTDY, AENDY, and ADURN, and a flag variable TRTEMFL, need to be created from SDTM.AE and ADSL. These variable are extremely helpful in increasing programming efficiencies.
问:How many ADaM DataSets are Needed?
ADaM is optimized to support data derivation and analysis. So, besides the unique ADSL, how many other ADaM datasets with the BDS and OCCDS structures are needed? The answer depends on how many tables and figures are needed and what are their structures (shells).
Not every SDTM dataset needs a corresponding ADaM dataset. For programming efficiency, we need to optimize the number of ADaM datasets.
In general, the number of ADaM datasets should be much smaller than the number of SDTM datasets.
Some programmers like to create ADaM datasets from the SDTM special-purpose class datasets such as ADDM. We do not recommend this practice because most of the SDTM special-purpose class datasets contain a few variables. Although SDTM.DM has 20 variables, most of these variables also exist in ADSL. It is not necessary to have a separated ADDM even in this case.
问: How many Variables are Needed in an ADaM Dataset?
How many variables should an ADaM dataset contain? In other words, how many variables are enough to support the efficient generation, replication, and review of analysis results? If the primary programmer, validation programmer, and study statisticians all put themselves in the FDA statisticians’ shoes, they will have the best answer.
Some variables, such as those directly taken from SDTM datasets, provide traceability between the analysis data and its source data (ultimately SDTM).
Some derived variables facilitate clear and unambiguous communication of the scientific and statistical aspects of the trial.
Variables被用于多个tables/figures,放在单独的ADaM数据集。
Variables that will be used for multiple tables/figures will stay within their respective ADaM datasets.
Variables that are used to generate only one table or figure, may be not necessarily need to be created in the ADaM dataset depending on the programming efficiency. It may be more convenient to have this variable derived within the table or figure program.
也需要考虑数据集的大小问题。
We also need to consider the size issue of a dataset. The more variables a dataset contains, the bigger its’ size. Datasets with very large size, may not be accepted by the FDA IT storage system.
结论:
BDS and OCCDS datasets discussed above are interchangeable in order 可以互换顺序, depending on your preference and actual programming needs. The documents - analysis Data Model (ADaM) (v 2.1, 2009), analysis Data Model Implementation Guide (ADaMIG) (v 1.1, 2016), and ADaM Data Structure for Occurrence Data, are good reference documents as an overview of the process, but the key to generating ADaM datasets is the actual needs of the specific study, traceability, and statistical programming and analysis efficiency.
