TLDR
本节课介绍了多种并行策略同时执行的Hybrid parallelism, 介绍了alpa论文,里面有如何自动找到多种并行超参数的方法。然后介绍了分布式训练中带宽和延迟的问题,为了解决带宽问题,可以采用梯度压缩的方式,其中包括梯度剪枝,可以通过Gradient Compression w/ Momentum Correction或者PowerSGD来实现,还包括梯度量化,可以用1-Bit SGD或者TernGrad来实现。为了解决延迟的问题,可以采用Delayed Gradient Update, 来让多GPU运行时的计算时间覆盖communication时间。
Overview

03:06Review Parallelization Methods05:19How to auto-parallelize
10:06bandwidth and latency bottleneck17:07Gradient compression
37:02Gradient Quantization
40:46Delayed gradient update
Paper List
CMU15-849: Machine Learning Systems by Zhihao Jia
Alpa: Automating inter- and intra-operator parallelism for distributed deep learning [Zheng et al., 2022]
Deep Gradient Compression: Reducing the Communication Bandwith for Distributed Training [Lin et al., 2017]
PowerSGD: Low-Rank Gradient Compression for Distributed Optimization [Vogels et al., 2019]
TernGrad
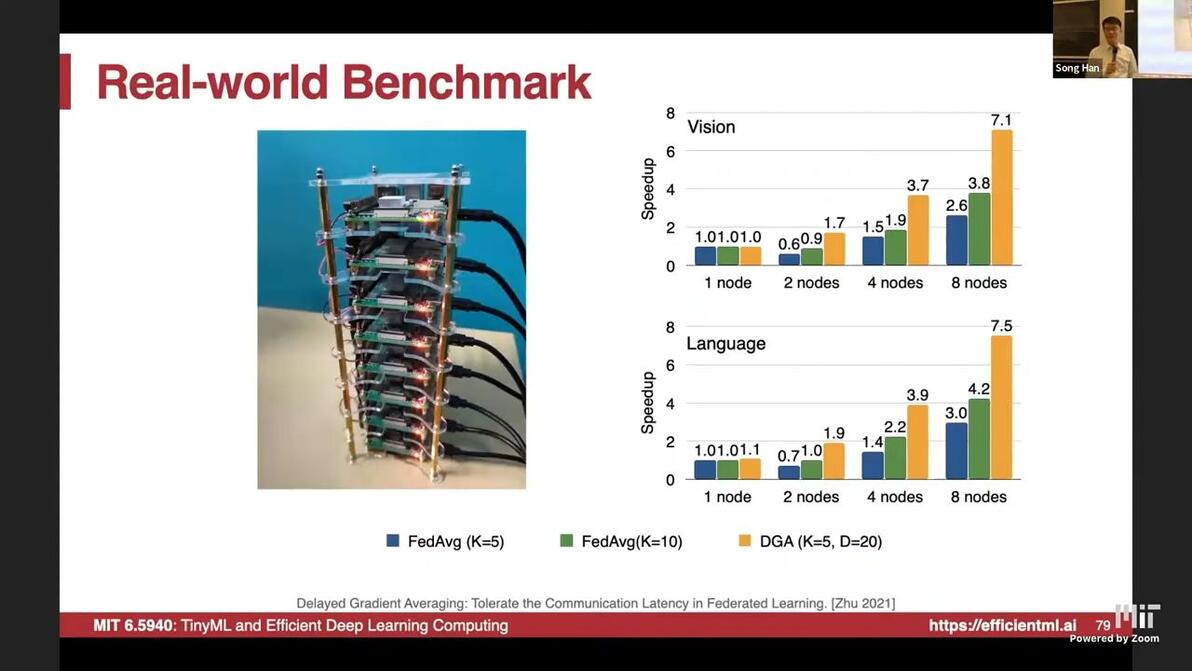
Delayed Gradient Averaging: Tolerate the Communication Latency in Federated Learning [Zhu 2021]
Lecture Notes
03:06Review Parallelization MethodsDP: high utilization, high memory cost, low communication
PP: low utilization, low memory cost, medium communication
TP: high utilization, low memory cost, high communication

Hybrid: DP+PP
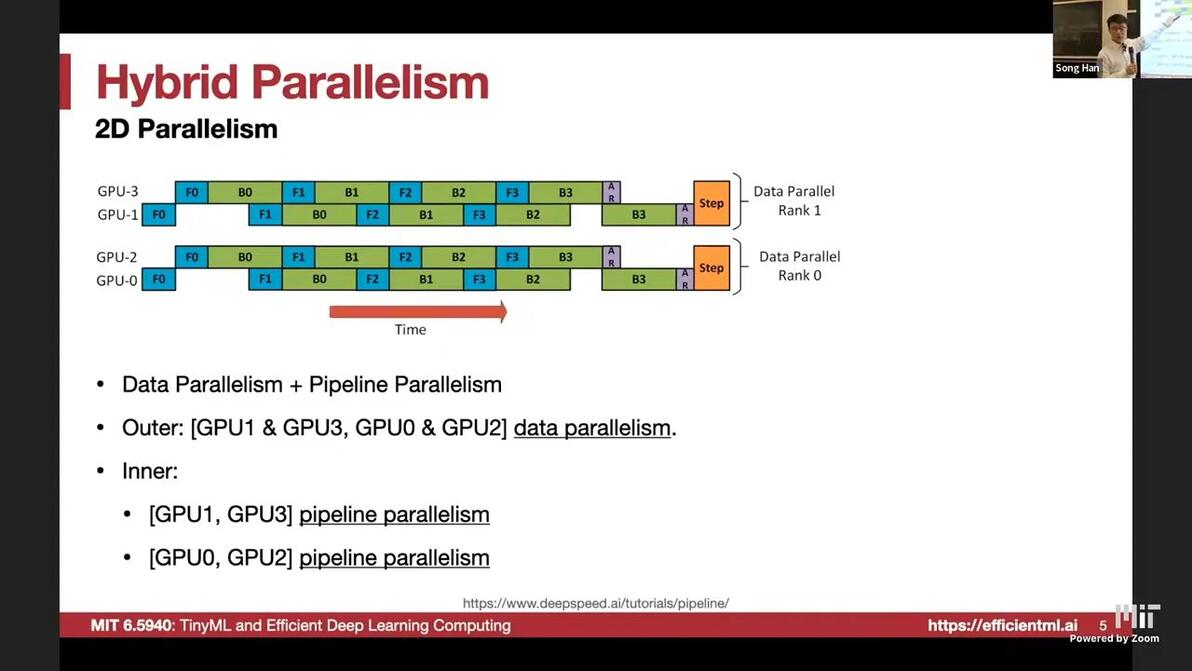
PP+TP
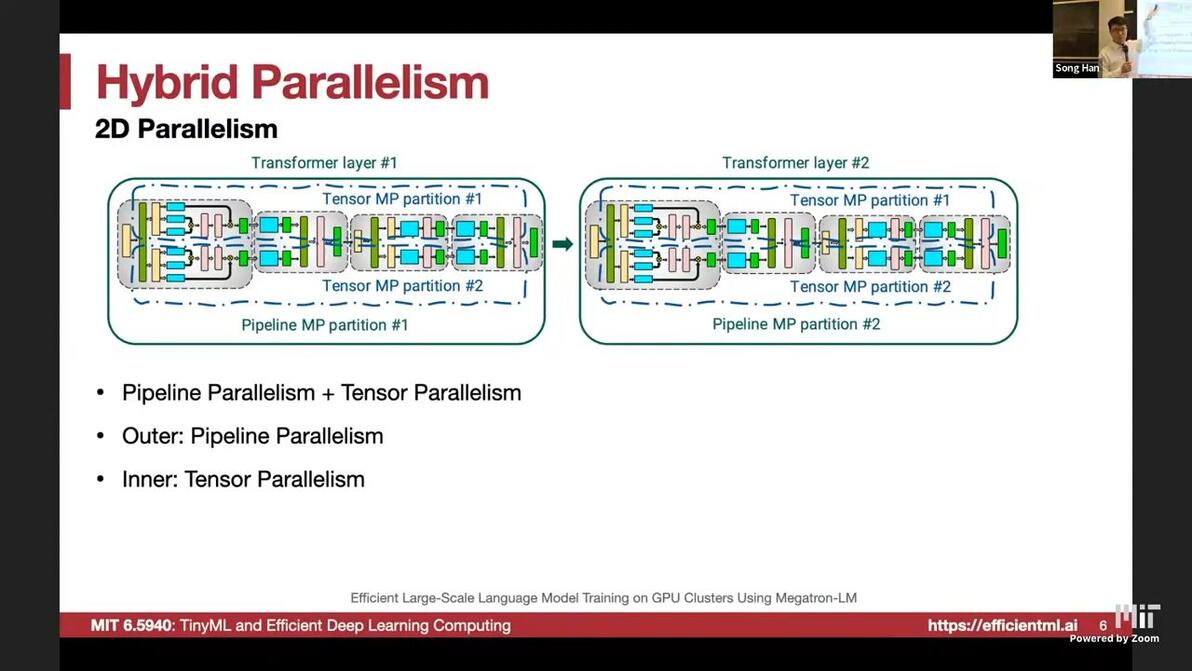
3D Parallelism: PP+TP+DP

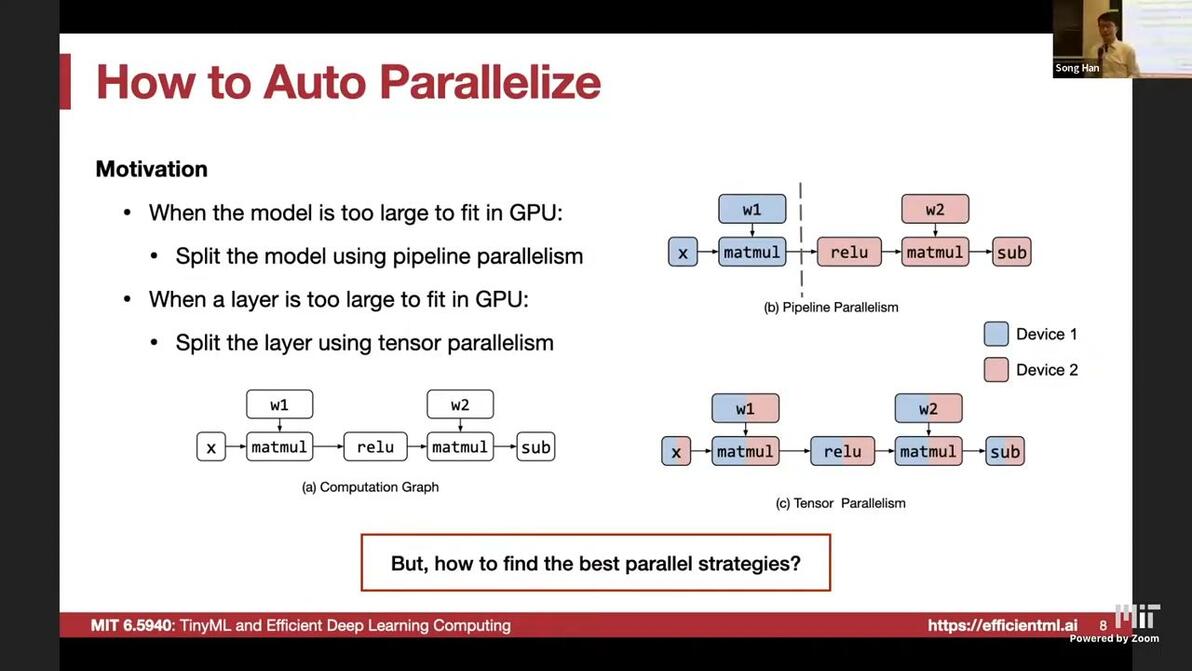
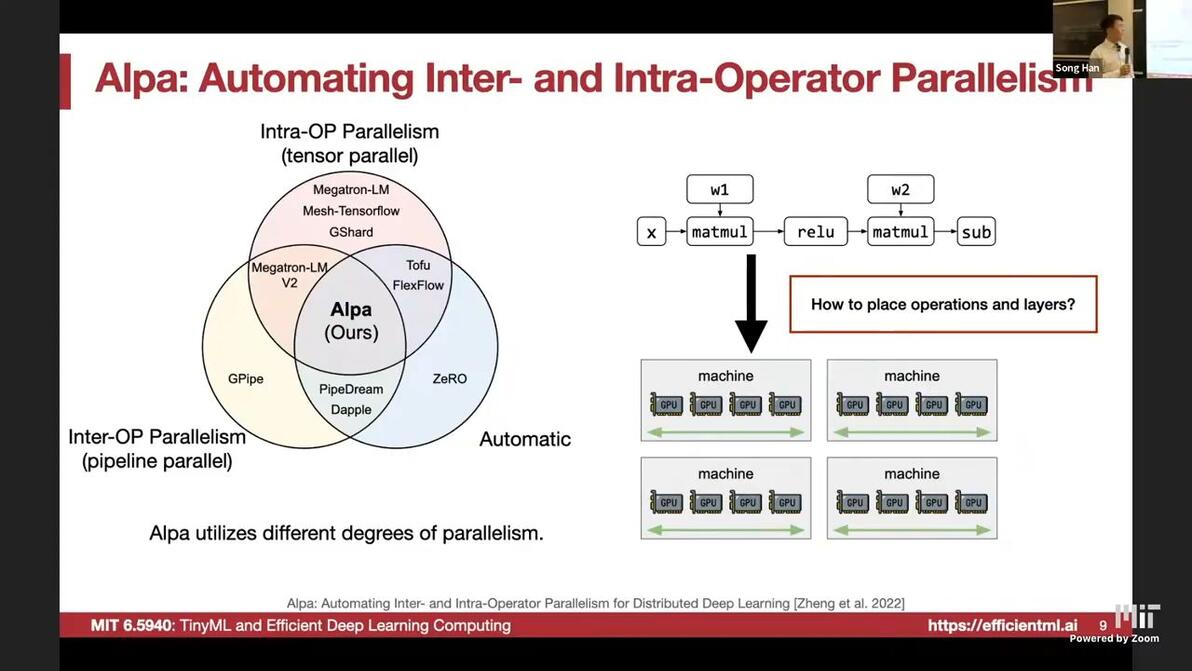
05:19How to auto-parallelize
Alpa: Automating inter- and intra-operator parallelism for distributed deep learning [Zheng et al., 2022]
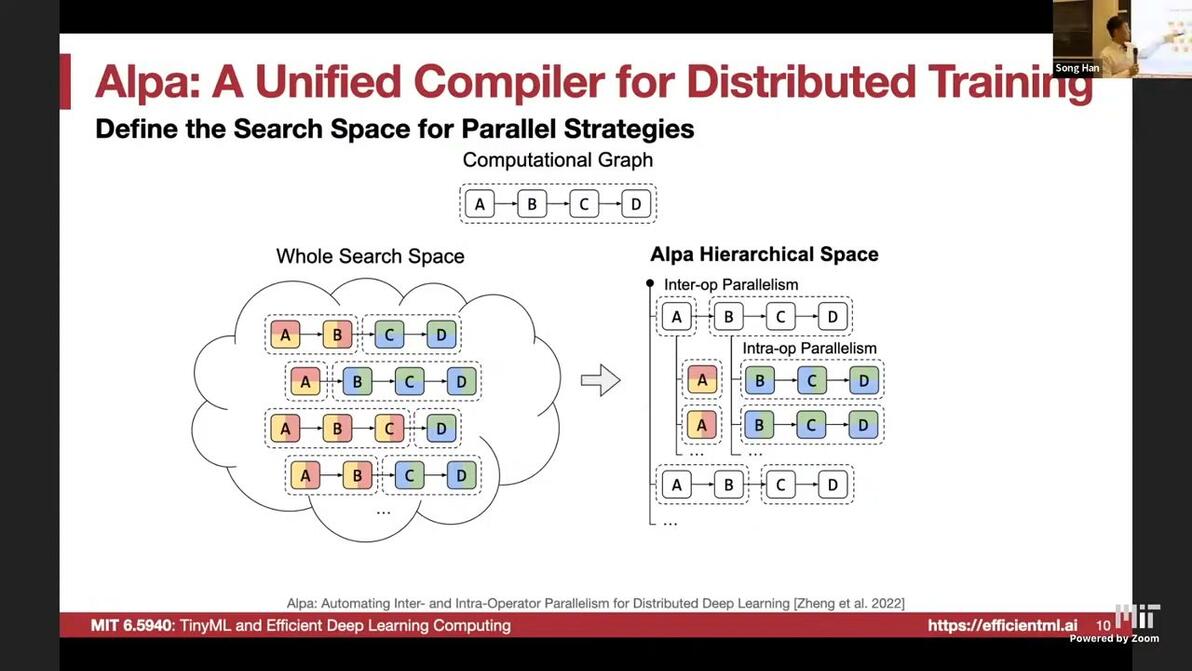
Define the search space for parallel strategies
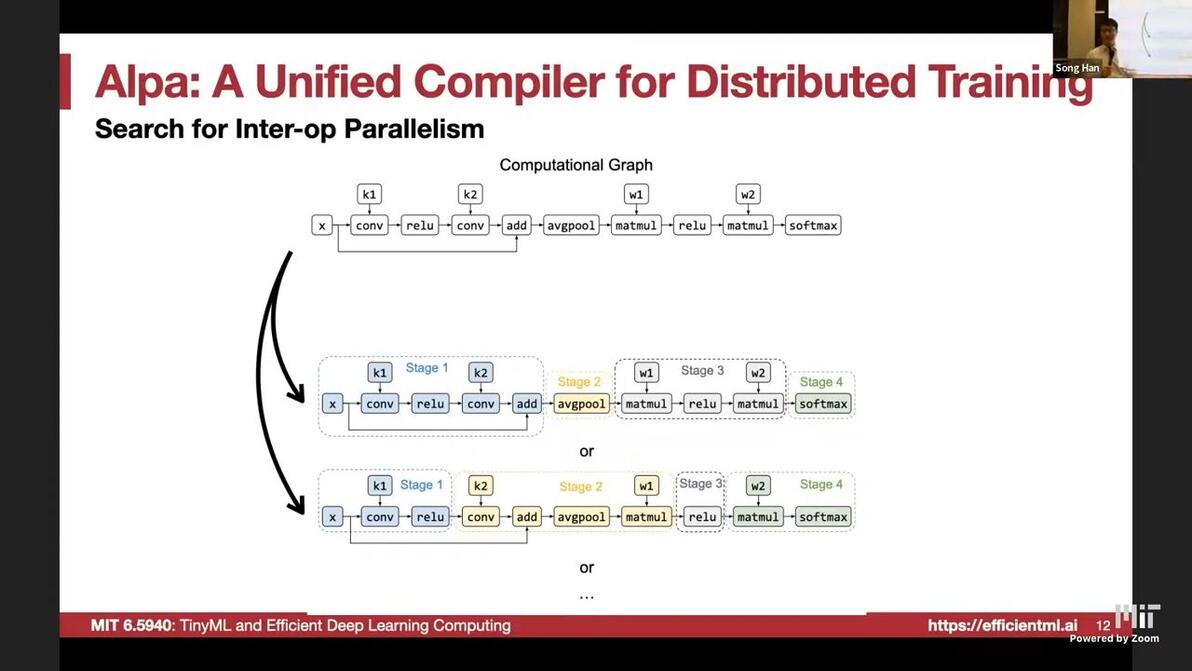
search for inter-op
workload roughly equal to avoid starvation
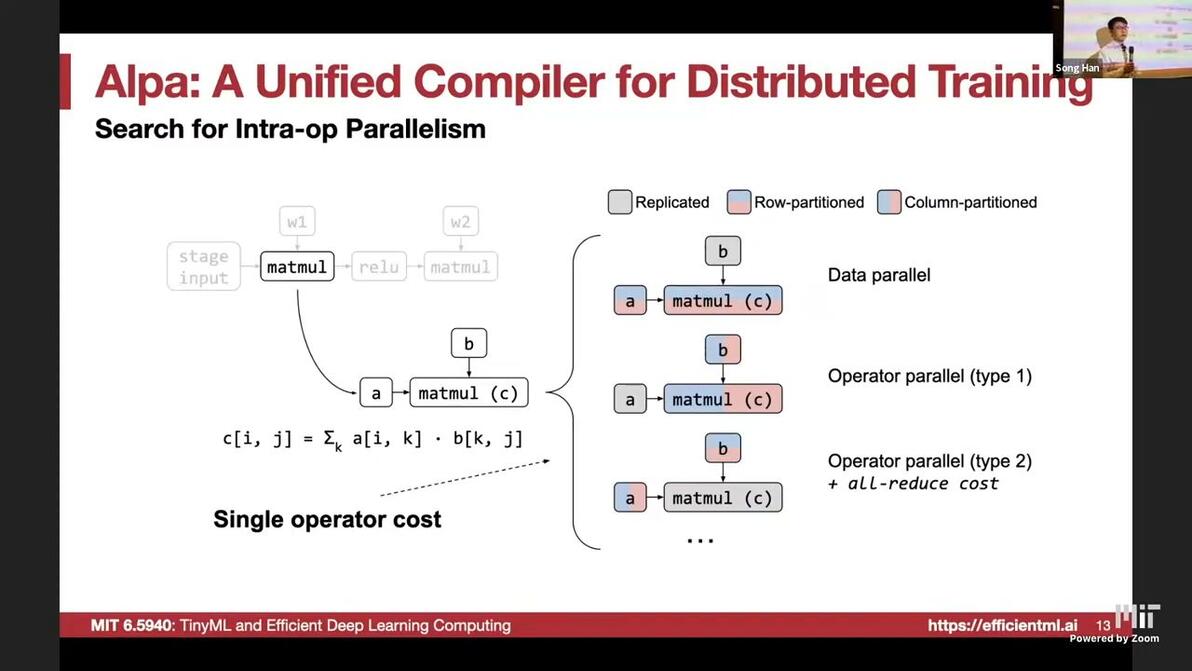
search for intra-op
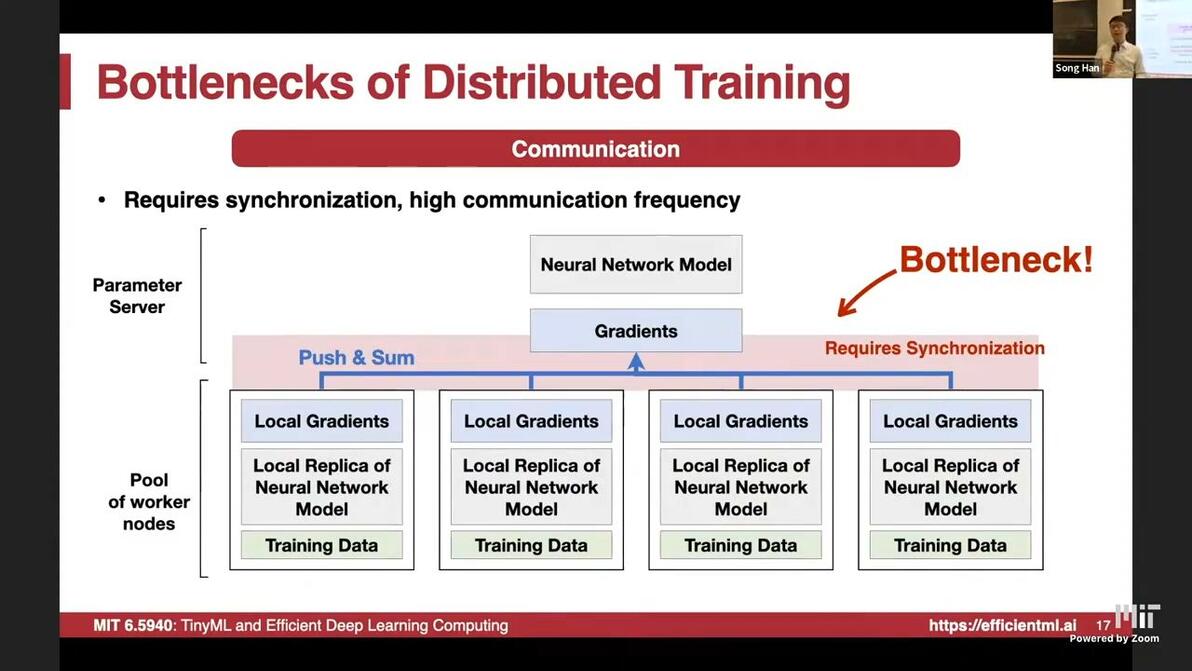
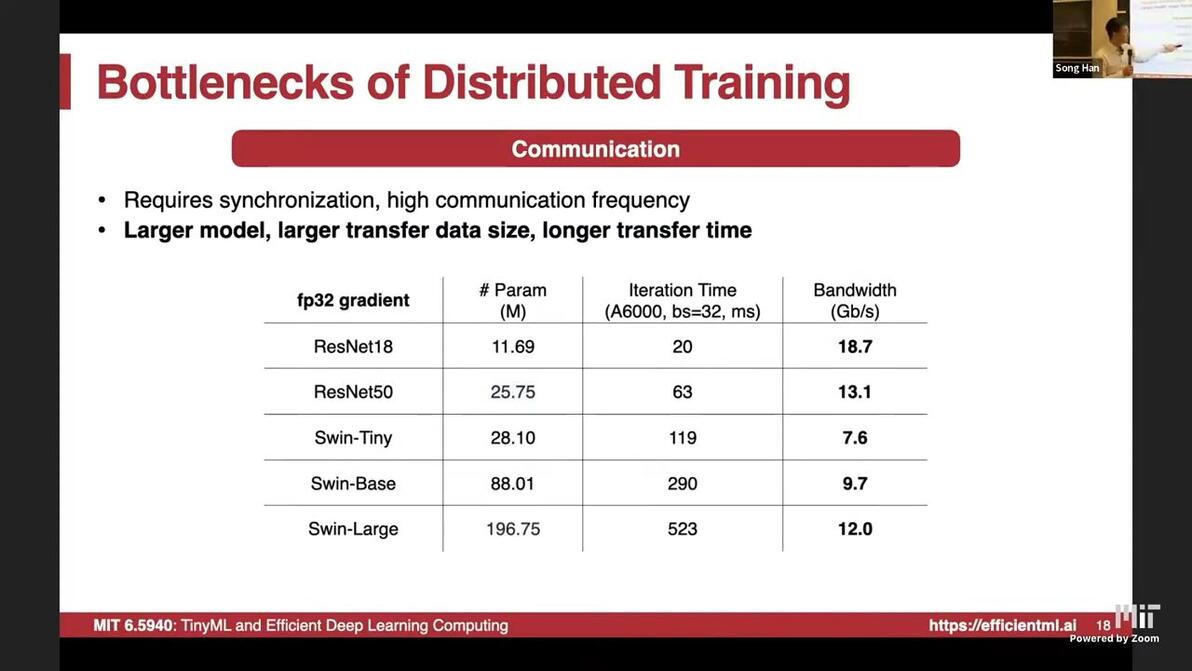
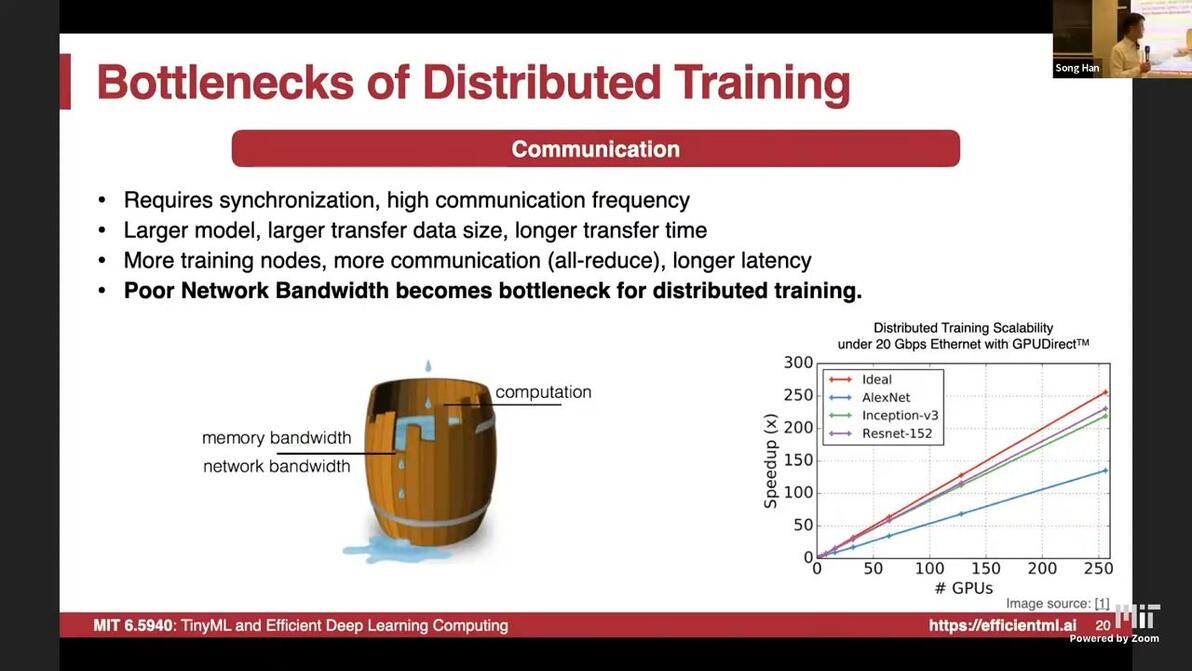
10:06bandwith and latency bottleneckCommunication is essential
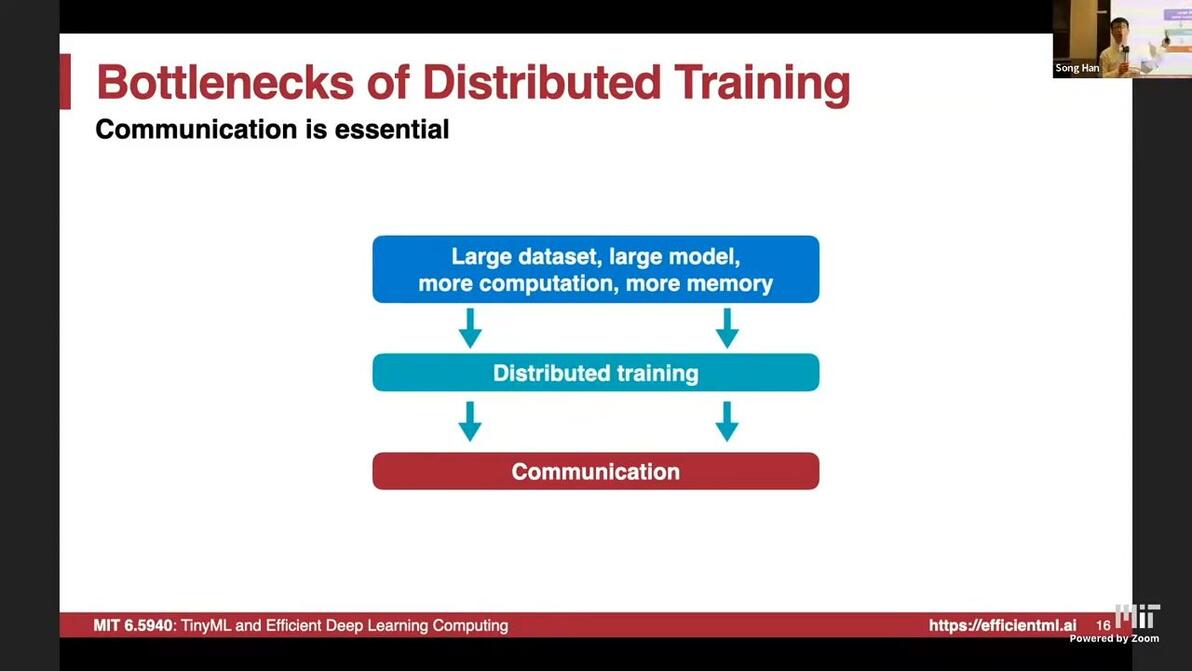
Parameter server: requires sync
Bandwidth requirement calculation
pay communication overhead, speedup not linearly on #GPUs
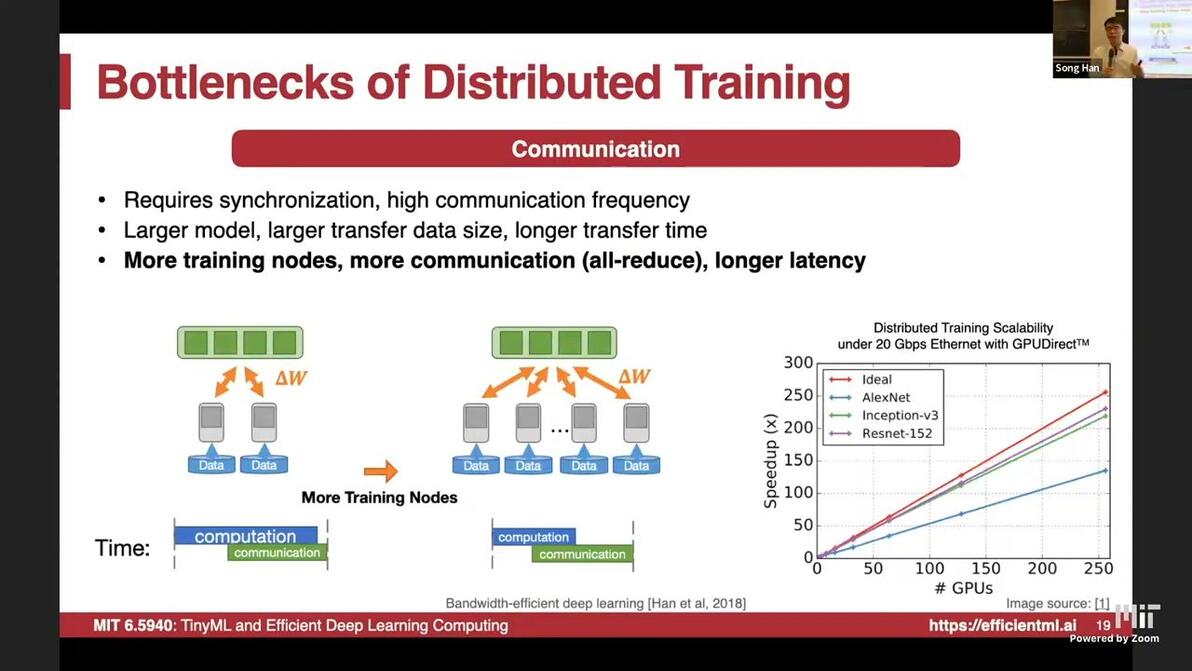
water bucket principle
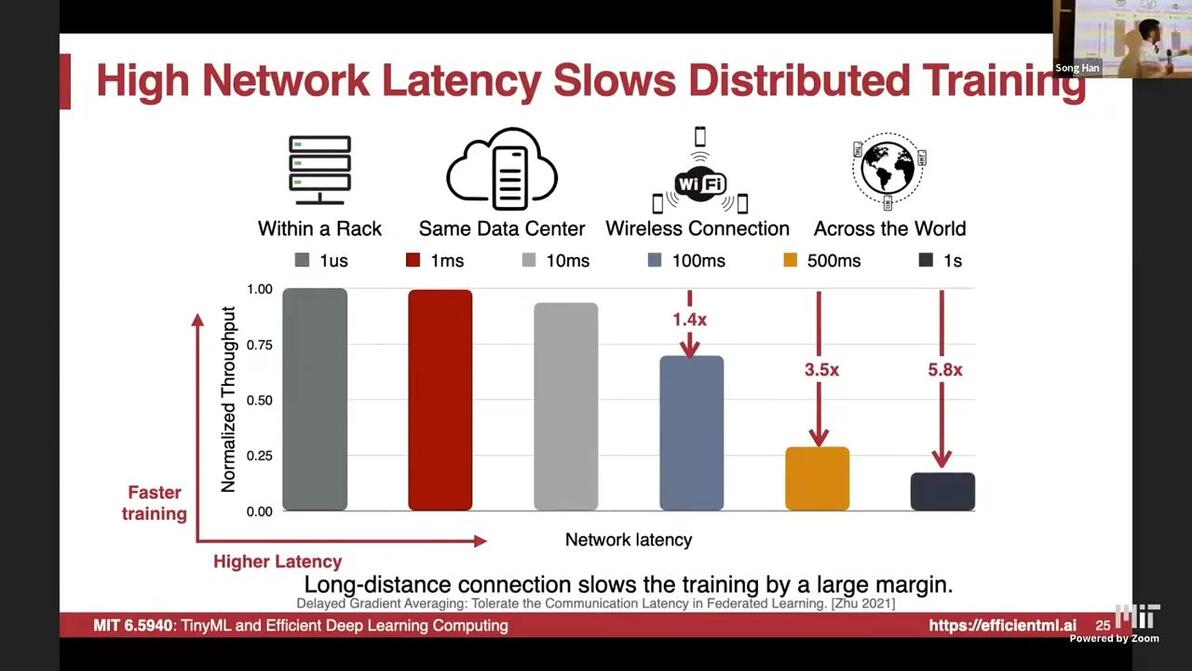
Latency analysis on networks
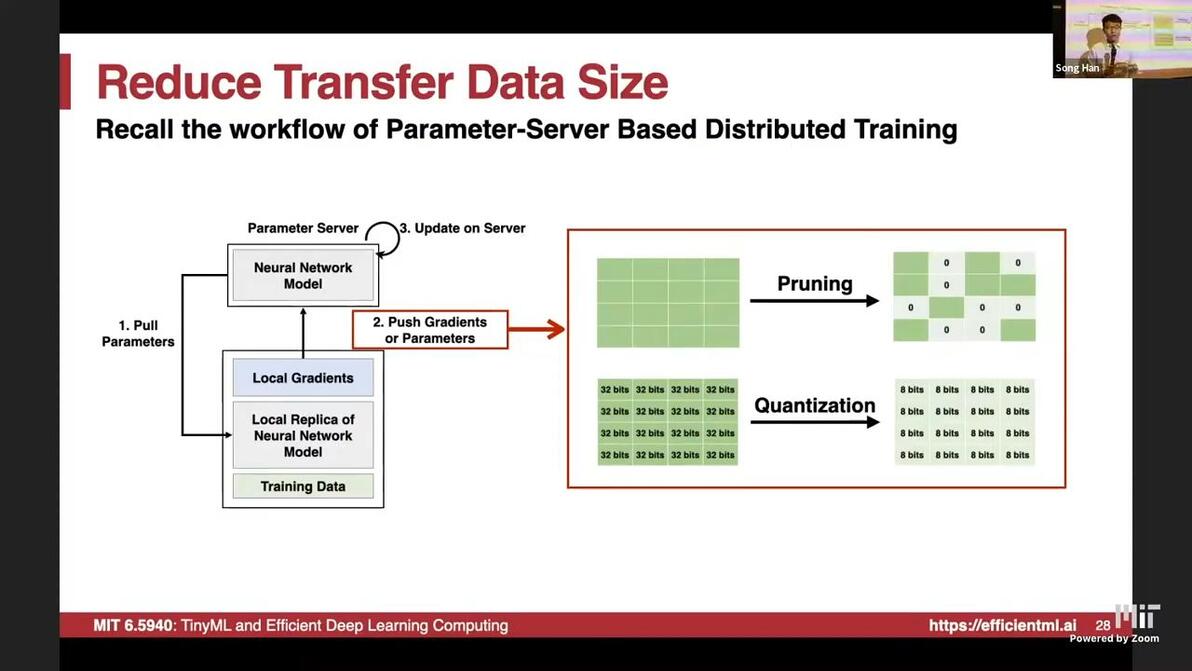
17:07Gradient compressionPaper: Deep Gradient Compression: Reducing the Communication Bandwith for Distributed Training [Lin et al., 2017]
when send gradients, no need to send it in fp32
sparse communication: send top-k gradients by magnitude, keep the error (residual) locally
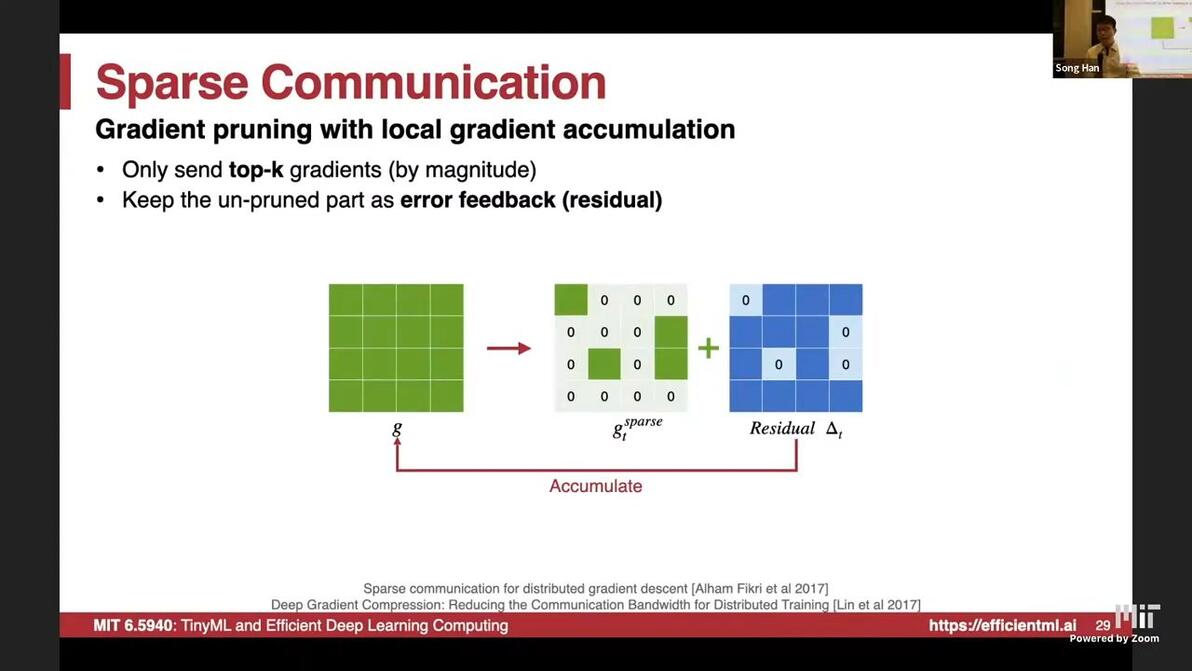
-1% accuracy on resnet

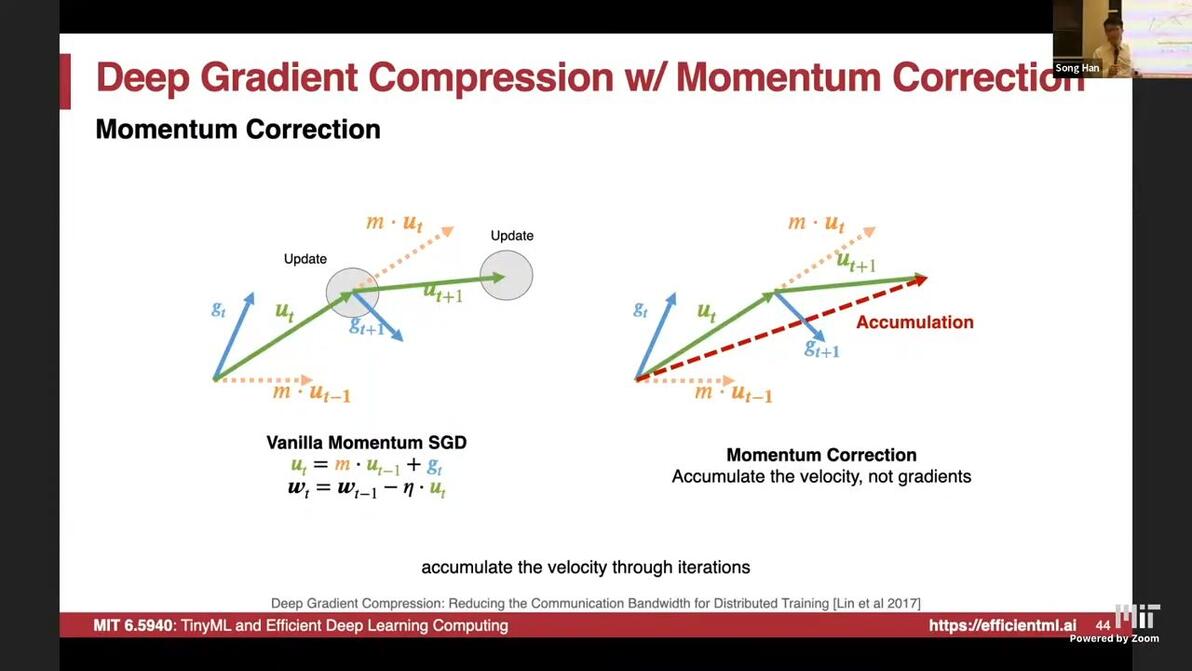
Reason: momentum

accumulated gradient problem
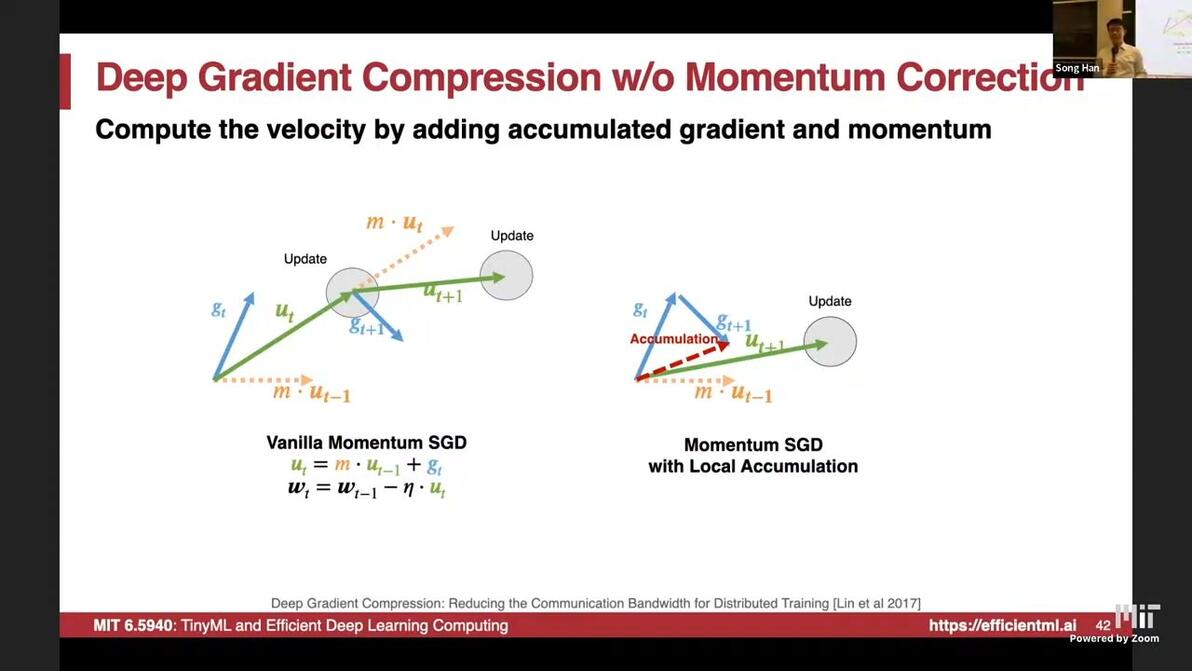
should accumulate the velocity, i.e. Momentum Correction
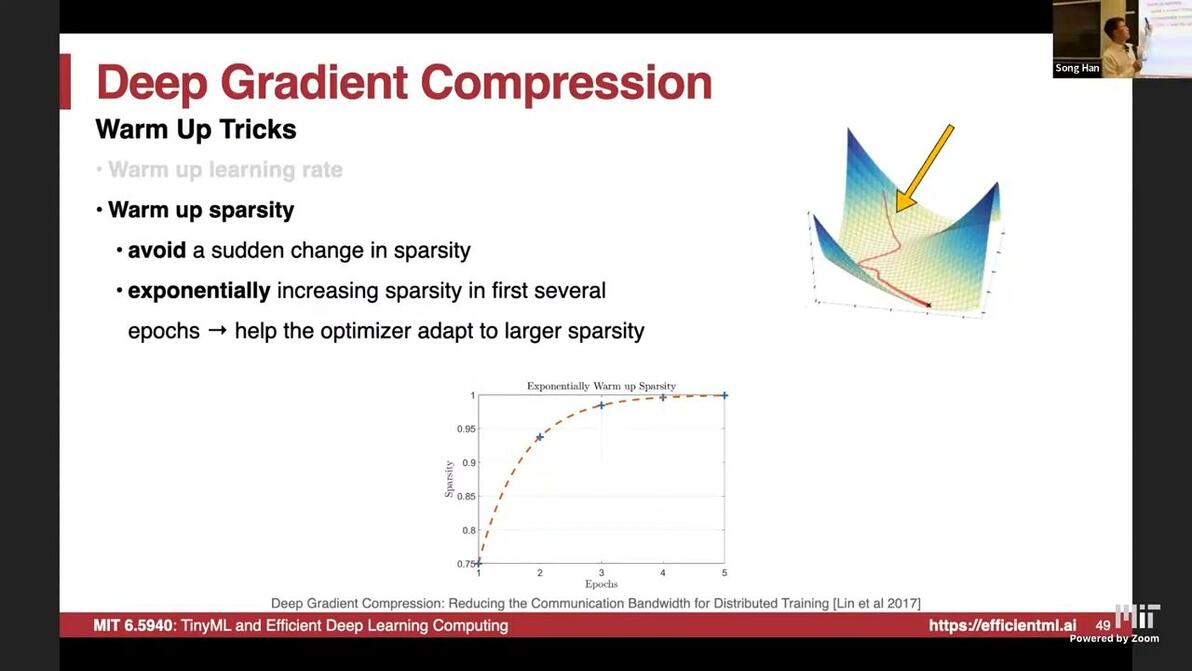
Warmup training
warm up sparsity
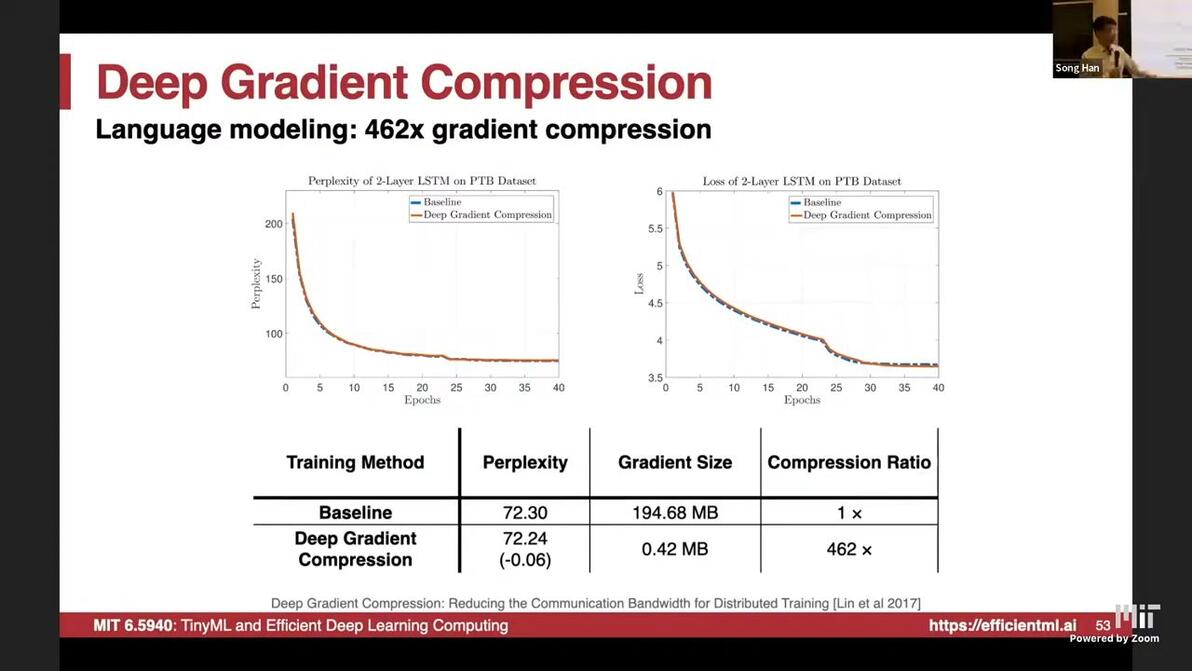
Performance
match accuracy with 99.9% sparsity

LM Compression Ratio 462x
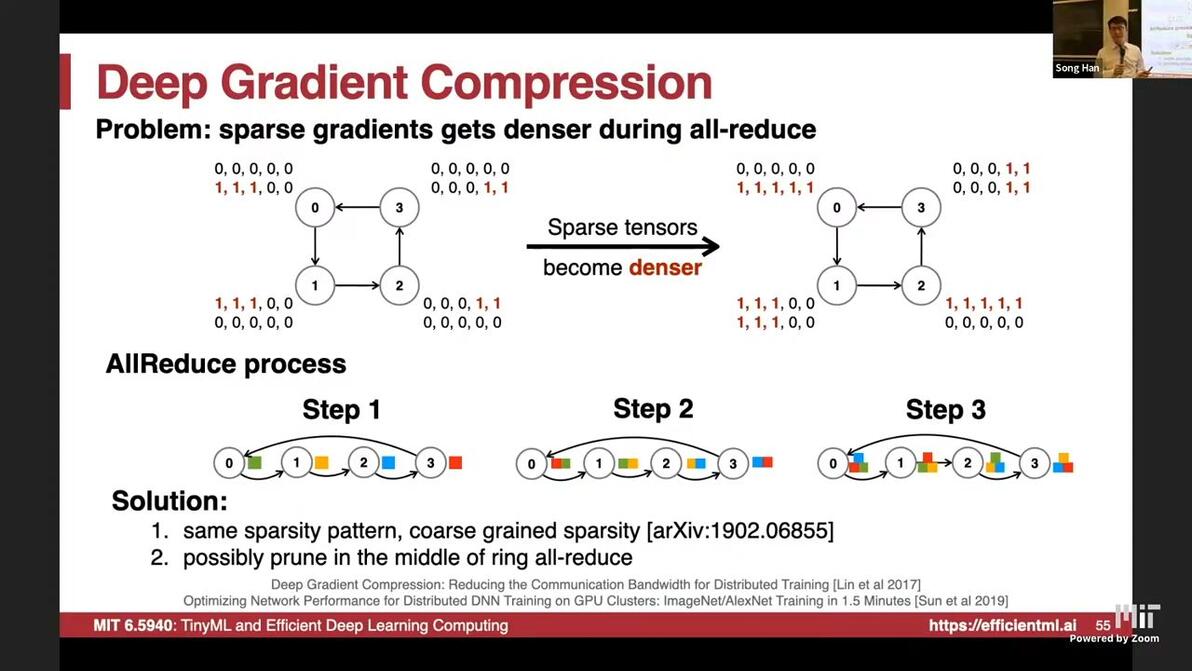
all-reduce for sparse gradients: sparse tensors become denser
solution: 1) coarse grained sparsity
2) prune in the middle of ring all-reduce
PowerSGD: Low-Rank Gradient Compression for Distributed Optimization [Vogels et al., 2019]

37:02Gradient Quantization1 bit SGD

compare with zero to get a 1 bit matrix + scaling factor

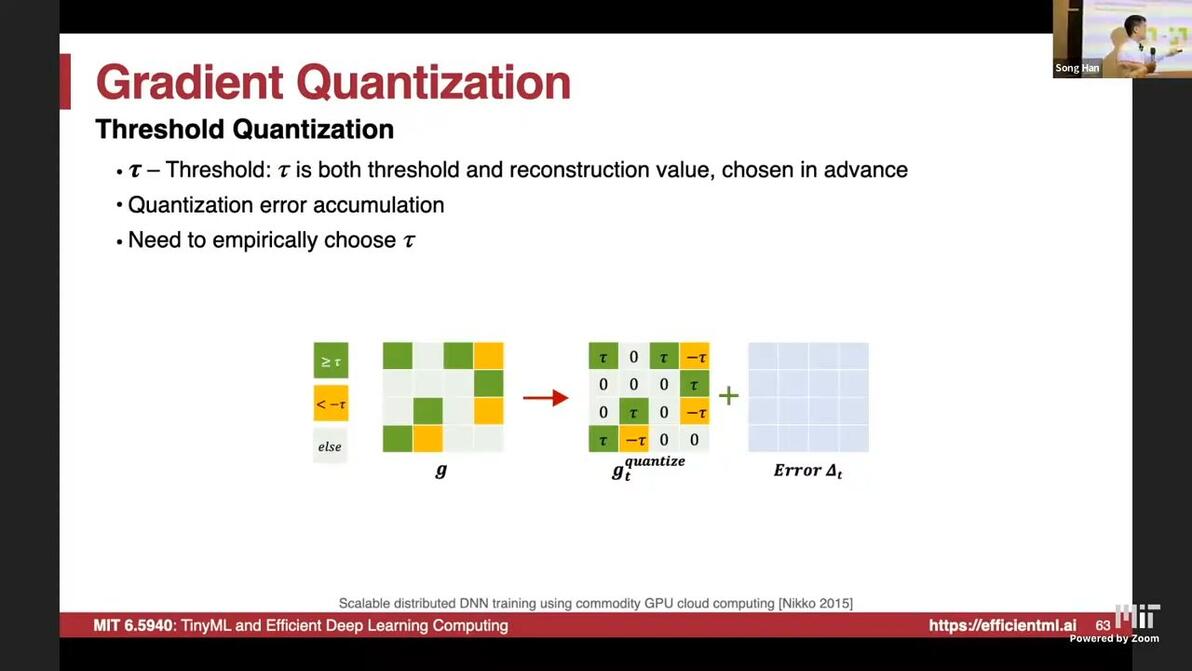
threshold quantization
TernGrad
normalize by max(g) to 0,1,-1

40:46Delayed gradient updateBandwidth vs Latency
Bandwidth can be upgraded by gradient compression and quantization techniques/ hardware
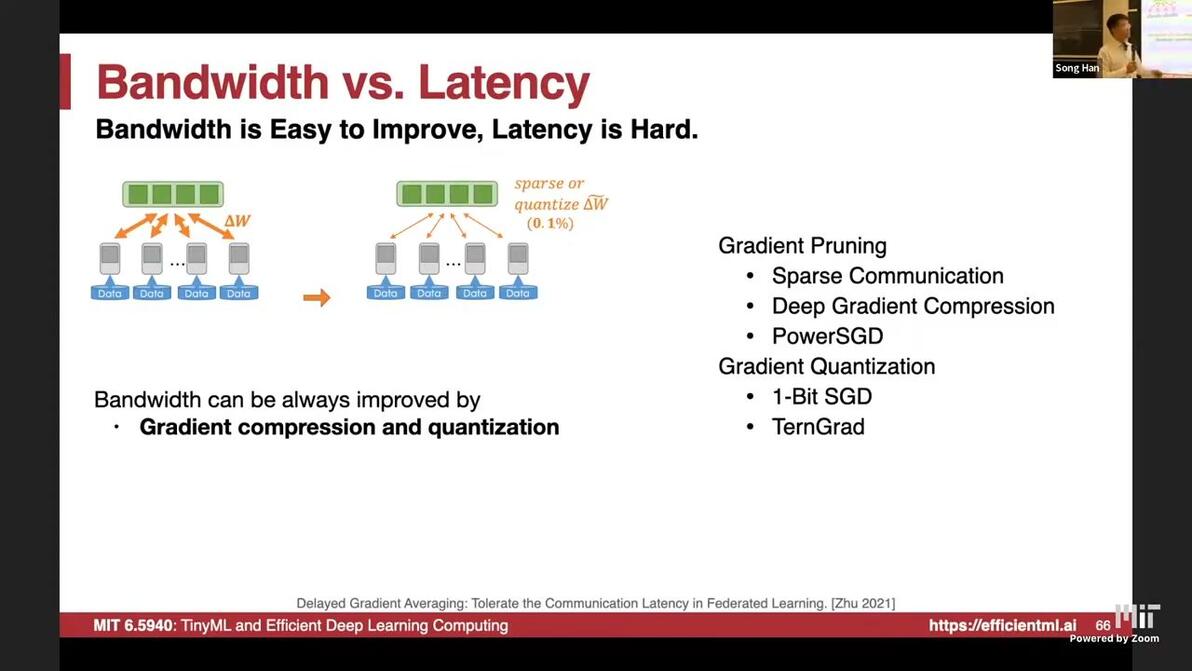
worker has to wait the transmission finish

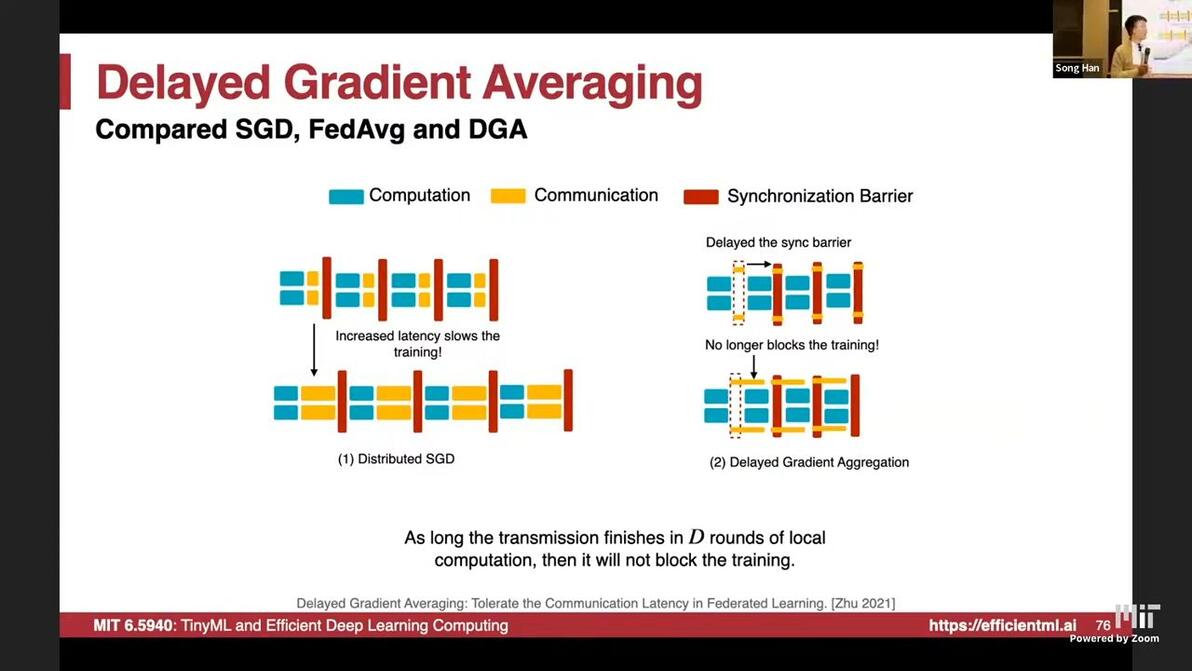
Delayed Gradient Averaging: Tolerate the Communication Latency in Federated Learning [Zhu 2021]
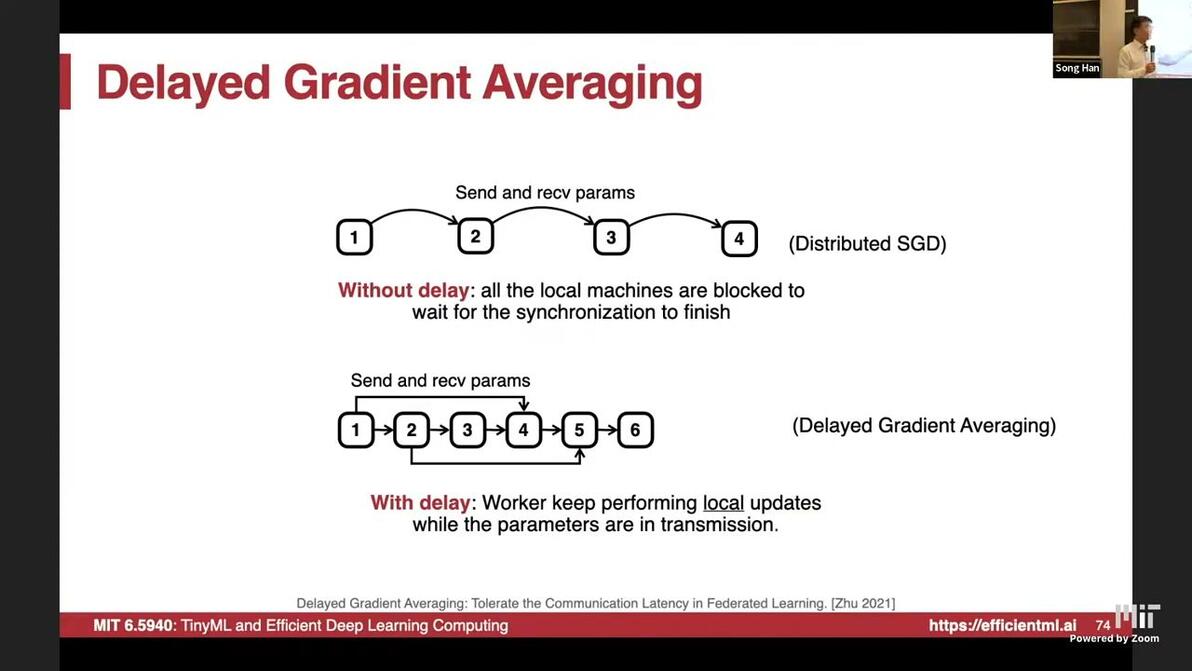
update with gradients at D steps before
communication is covered by computation
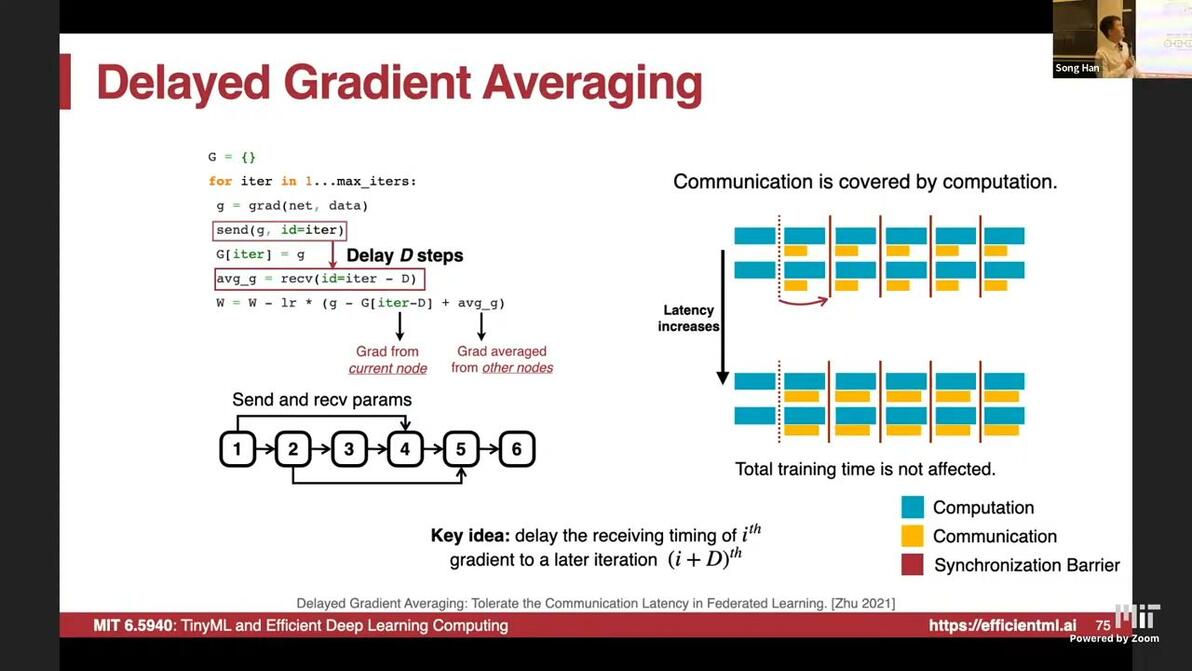
Methods Compare
Real-world benchmark 7.5x on Language Task