
数据探索 首先我们需要对数据做一些探索,一是了解数据的缺失值情况、异常值情况,以便做对应的数据清洗。二是了解一下违约贷款和正常贷款用户画像的区别,加深对业务的理解,为我们后面的数据分析(特征工程)展开打基础缺失值检测:数据一共有122列,有67列存在缺失情况,最高缺失值的列缺失度为69.9%,对缺失值的处理在房价预测案例中已经提到过,对于缺失值的处理一是我们可以采用XGBoost这种能够自动处理缺失值的模型,这样我们就无需处理缺失值。二是可以进行填补,三是可以对缺失值较高的列直接删除。这里有一点大家注意,可以发现前面的几列特征缺失度的都是一样的,并且它们都是属于房屋信息,根据这个规律我们可以猜测用户缺失房屋信息可能是因为某种特定原因导致的,而不是随机缺失,这点我们会在后面的特征工程用上。异常值检测:对主训练集进行一些异常值的探索,这次异常值探索,我们采取最简单的描述统计的方法,即查看特征的均值、极大值、极小值等信息判断是否有异常值查看用户年龄的数据分布情况(因为数据中,年龄的数值是负数,反映的是申请贷款前,这个用户活了多少天,所以这里我除了负365做了下处理),发现数据的分布还是比较正常的,最大年龄69岁,最小年龄20岁,没有很异常的数字查看【用户的工作时间分布】情况发现(同样工作时间也是负数,所以我除了负365),最小值是-1000年,这里的-1000年明显是一个异常数据,没有人的工作时间是负数的,这可能是个异常值看一下【用户受雇工作时间】的数据分布情况,发现所有的异常值都是一个值,365243,对于这个异常值我的理解是它可能是代表缺失值,所以我的选择是将这个异常值用空值去替换,这样可以保留这个信息,又抹去了异常值,替换之后我们再看一下工作时间的分布情况,正常了很多
违约用户画像探索查看违约用户和非违约用户的特征分布情况,目标是对违约用户的画像建立一个基本的了解,为后续特征工程打下基础性别:男性比女性违约率更高(柱状图)年龄:年轻用户违约率更高(分布图,连续变量),进一步对年龄分桶,观察不同年龄段的违约率,发现确实是年龄约小越容易违约现金贷款和流动资金循环贷款:现金贷款违约率更高没有车和房违约率更高,但差别不是很大子女越多的违约率越大,发现有9、11个孩子的违约率达到100%,这也与样本量少有关。根据申请者的收入类型区分,可以发现休产假和没有工作的人违约率较高,在35%以上,对于这两类人群放款需较为谨慎从职业来看,越相对收入较低、不稳定的职业违约率越高,比如低廉劳动力、司机、理发师,而像会计、高科技员工等具有稳定高收入的职业违约率就较低学历越低越容易违约
特征工程贷款金额/客户收入,预期是这个比值越大,说明贷款金额大于用户的收入,用户违约的可能性就越大贷款的每年还款金额/客户收入,逻辑与上面一致对我们设计出来的连续性特征查看它们在违约用户和非违约用户中的分布情况,可以发现除CREDIT_TERM这个特征外,其他的特征区分度似乎都不是很明显,大家不需要灰心,这个是很正常的现象,虽然现在看起来区分度较小,但我们可以放到模型中再看一下效果下通过缺失值设计的这个特征,通过下图我们可以看到,缺失房屋信息的用户违约概率要明显高于未缺失用户,这在我们模型的预测中可以算是一个比较有效的特征了、
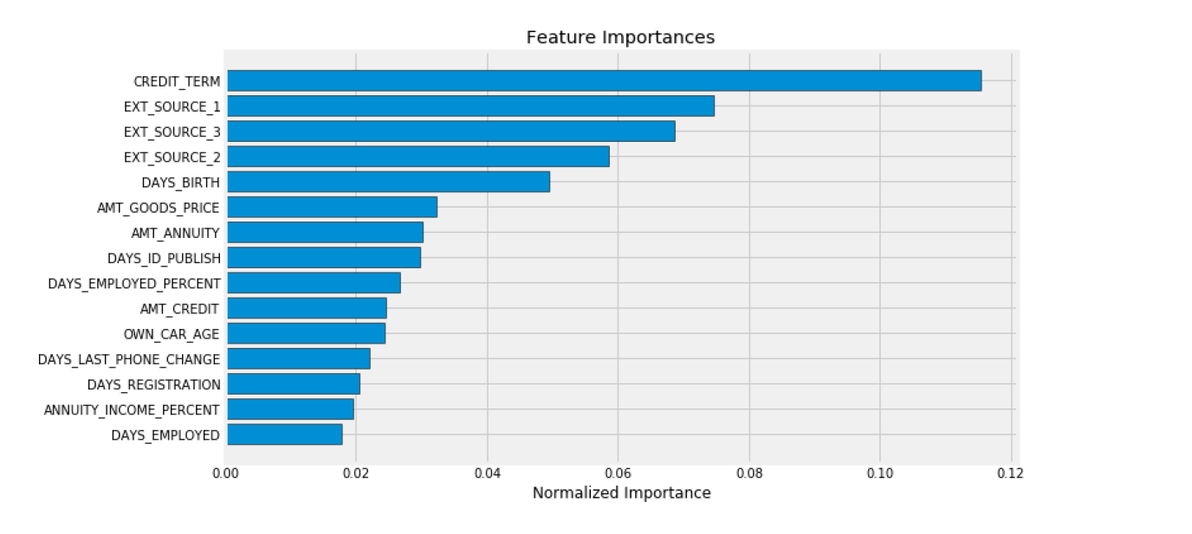
建模预测:xgboost通过lgb自带的函数查看特征的重要性
三、利用其他数据集信息
除了一个主要训练集和预测集之外,往往还会有一些辅助训练集,这些训练集和主训练集可以通过对应的键进行关联,我们一般需要从这些辅助训练集中提取出一些信息把它们作为新的特征加入到主训练集中
信用局信息
首先是信用局信息,数据集中的每一行代表的是主训练集中的申请人曾经在其他金融机构申请的贷款信息,可以看到数据集中同样有一列是“SK_ID_CURR',和主训练集中的列一致,我们可以通过这一列去把辅助训练集和主训练集做left join,但需要注意的一点是,一个SK_ID_CURR可能会对应多个SK_ID_BUREAU,即一个申请人如果在其他金融机构曾经有多条贷款信息的话,这里就会有多条记录,因为模型训练每个申请人在数据集中只能有一条记录,所以说我们不能直接把辅助训练集去和主训练集join,一般来说需要去计算一些统计特征(groupby操作)
针对每个贷款申请人计算他们在其他金融机构历史上的贷款数量(count)
过一个申请人如果在其他金融机构曾经有多条贷款信息的话,数据集里就会有多条记录,根据这点我们可能会想到,一个申请人在其他金融机构的历史贷款申请数越多,是不是可能说明这个人的信用可能越好?因为他的信用已经在其他金融机构那里被验证过
再把计算出来的统计特征和主训练集做left join,检测新特征对预测是否有区分度,发现虽然非违约用户平均贷款申请数量略多于违约用户,但差异很小,连续变量 特征提取 groupby agg利用特征和标签的相关性做一个简单的判断,结果并不显著(
