



我永远喜欢零.jpg
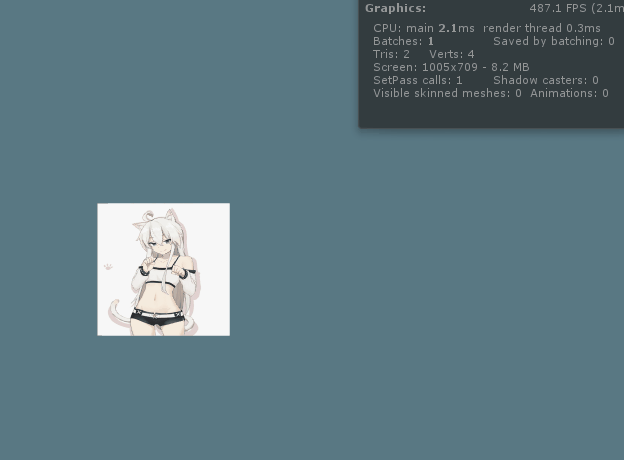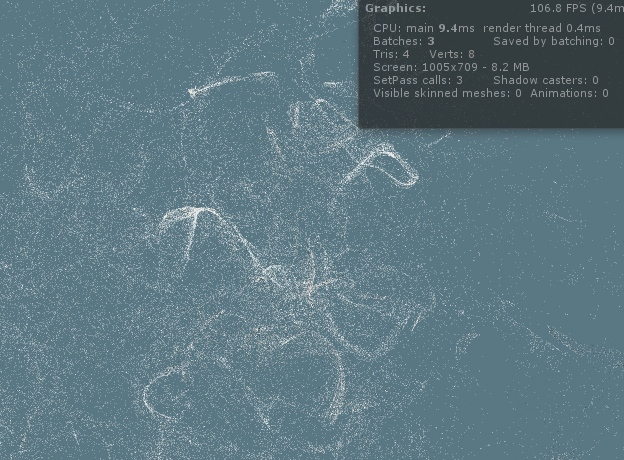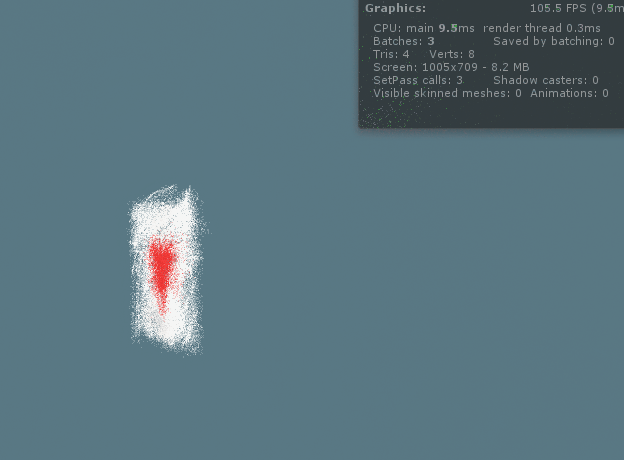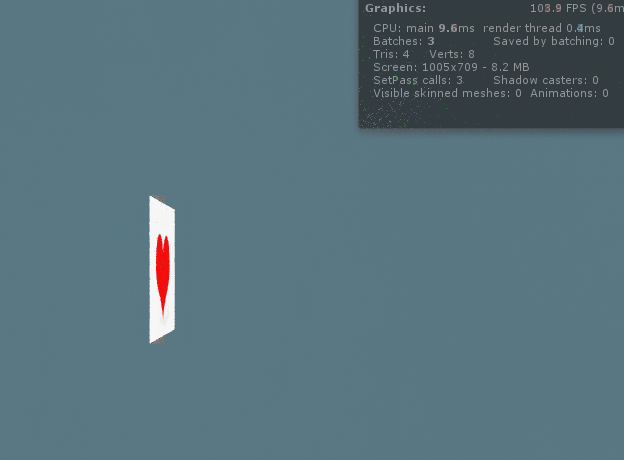
先放上效果图,512x512的图片大小和26万粒子(cube),帧数维持在110fps左右。我们暂且不说明制作思路,先用一个模糊的例子简单理解一下计算着色器(compute shader)一般简称为cs,DX10开始出现后续逐步完善。
针对有平行优势的操作(执行大量相同操作),我们可以利用cs来优化效率。cs可以用做通用计算,也就是gpu负责主要的计算过程,最后再将结果传递给cpu,这类非图形计算被称为GPGPU。cs虽然位于渲染流水线之外,但它支持读写GPU资源,我们可以将运行结果直接传递到渲染管线,从而来完成一些图形处理的效果,这样就没有了从显存到内存的时间开销(此类过程速度很慢)。cs的基本概念和使用操作其实很简单,简单的关键点理解在于线程和线程组以及主要的几个标识(线程组ID,单个线程组组内的线程ID,所有线程的全局标识ID),理解到了这个点以及资源的传递(纹理,StructedBuffer一般简称sbuffer)就可以马上开始编写一些效果啦,当然更核心的其实在于cs的优化部分(日常负优化),这个的关键点在于共享内存(LDS/TGSM/shared memory)、warp(Gpu调度基本单元)、bank conflict、warp divergence(避免一个warp中的线程出现分支)以及各种硬件架构的不同。
因为3d线程组很少用到,直接就从2d线程组介绍了。我们用一个dispatch来规定分派的线程组数量(图中大小为2x2)。线程组内的线程数量也是由用户自己分配的(最好为warp(32/64)的整数倍大小,要求小于1024,方便画所以图中大小为2x2),图中红色部分即代表线程组ID,绿色部分代码组内线程ID,蓝色部分代表线程全局ID.嘛为了后面的方便这里直接将这个几个称呼为unity内的语义,GroupID ,GroupThreadID,DispatchThreadID.
根据这个分配我们可以得到一个关系:
DispathThreadID=GroupID * numthreads + GroupThreadID
也可以得到2d转为1d的组内线程ID的线性索引
uint NewGroupThreadID=GroupThreadID.y*numthreads.x+GroupThreadID.x;

接下来我们直接看看unity的实现过程,我们通过创建RenderTexture,开启随机写入绑定uav到cs存取模糊后的结果。dispatch按图片大小(2048x2048)分配线程组,保证线程能操作到图片的每个纹素

模糊为了方便简单做了一个box blur,这里的DispatchThreadID可当作纹理的纹素索引

blur1

错误效果
执行完毕后模糊效果出来了,但我们发现在图片的边缘部分出现了明显的灰边。这是因为我们索引越界了,在cs中越界的读取数据默认返回0。所以我们需要进行clamp操作,让越界部分得到一个和边界纹素相同的数据。


我们用renderdoc抓帧简单分析下计算时间

可以看到上面的计算量是很大的,因为图片大小和我们的模糊核大小都很大,我们来做一下优化,box filter同高斯模糊核一样具有可拆分性,我们拆分一下Box filter来看一下结果。

blur2

这个优化量是巨大的毕竟单个纹素采样数从(2*BlurRadius+1)*(2*BlurRadius+1)变为了(2*BlurRadius+1)+(2*BlurRadius+1)。
接下来我们通过LDS继续优化这个计算。每个线程组都有一块内存空间,这个空间的读取速度很快,我们可以利用它加速一些重复读取运算和实现一些特定算法,但这个空间也有大小限制根据shader model不同。因为模糊半径的原因我们读取的单行/单列纹素数据大小需要为2*BlurRadius+numthreads,否则在读取LDS的时候会出现线程组越界情况,记得同时处理图像边界纹素采样越界的情况,还有确保组内线程同步。

Gpu pro6 Figure1.17

水平方向,竖直方向同理

LDS虽然好,但要注意bank conflict的问题(这里可看可不看,因为测试发现。。unity好像并没有这个问题,具体原因不明,可能编译器做了优化吧)这个问题有个很好的GPGPU的例子parallel reduction,通过LDS并行归约进行数据的求和。https://developer.download.nvidia.cn/assets/cuda/files/reduction.pdf的一种做法:将全局内存中的数据拷贝到LDS,然后根据step增加步长(stride)。在进行step2之前我们需要保证step1的线程同步,否则就会出现还未写入就读取的情况。逐步累加结果存储于LDS的第一个元素,最后将每个线程组LDS的第一个元素累加就是最终结果。注:bank conflict问题目前只存在同一warp中的线程,一些老文档可能说的是half-warp。

https://developer.download.nvidia.cn/assets/cuda/files/reduction.pdf

这个代码的实现理论存在bank conflict的问题。共享内存(LDS)其实是由多个存储块(bank)组成的(在Femi,maxwell架构上的显卡分为32个bank,G80架构上分为16个bank),当同一warp中出现多个线程访问一个bank的不同地址就会发生bank conflict。简单理解一下:当上述代码s=1时,index=2*tid.此时0-(0%32),1-(2%32),2-(4%32)...16-(32%32)=16-0.此时在同一warp中的0号线程和16号线程访问了bank0的不同地址于是发生了bank conflict.图中的每个小方格容纳4bytes的数据量代表gCache的地址偏移量(数组下标)。

改进算法,此时同一个warp中的线程访问不同的bank。


https://developer.download.nvidia.cn/assets/cuda/files/reduction.pdf

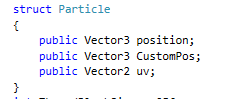
接下来说一下开始的粒子变化,我们在中心生成一个quad,这个quad由根据图片大小每纹素填充的相同cube组成,position代表cube的世界坐标位置,custompos存储用来变化的位置,同时每cube带有一个uv属性用来采样。
根据粒子数和线程组内线程数量分配合适的线程组数量,下面计算等同于ceil((double)N/ThreadBlockSize).根据struct字节大小和粒子数量创建computebuffer.

设置完cube粒子的初始属性后,我们每帧在cs中更新粒子的position,利用curlnoise给粒子最初一段时间的飘动,中途根据之前存有的变化位置重新改变粒子轨迹。

在Unity中sbuffer可以传向其他着色器,利用DrawMeshInstancedIndirect创建cube粒子,在shader中读取sbuffer开启gpu instance.这里传入挂载着脚本的物体(粒子生成器)的世界矩阵是为了方便整体更改粒子的位置缩放和旋转。

在shader中为每个cube构建世界矩阵。传入_lerp实现2张图片之间的切换

项目地址:https://github.com/mxrhyx233/Unity-Morph-Image-based-on-Gpu-particle
参考文档:
http://on-demand.gputechconf.com/gtc/2010/presentations/S12312-DirectCompute-Pre-Conference-Tutorial.pdf
https://yumayanagisawa.com/2017/11/21/unity-compute-shader-particle-system/
https://www.evl.uic.edu/sjames/cs525/final.html
<<Directx12 3D 游戏开发实战>>
https://segmentfault.com/a/1190000007533157
https://developer.download.nvidia.cn/assets/cuda/files/reduction.pdf
https://www.nvidia.com/content/nvision2008/tech_presentations/Game_Developer_Track/NVISION08-Image_Processing_and_Video_with_CUDA.pdf
https://qiita.com/nyamadandan/items/2a8bc7a3639e7b5ce9c9
http://www.xuanyusong.com/archives/4488
