
CosyVoice: A scalable Multilingual Zero-shot Text-to-speech Synthesizer based on Supervised Semantic Tokens
一种可扩展的基于监督语义令牌的Zero-shot多语言文本-语音合成器
Cosyvoice2: Scalable Streaming Speech Synthesis with Large Language Models
大型语言模型的可扩展流语音合成
Cosyvoice3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
通过放大和后训练实现野外语音生成
一句话总结
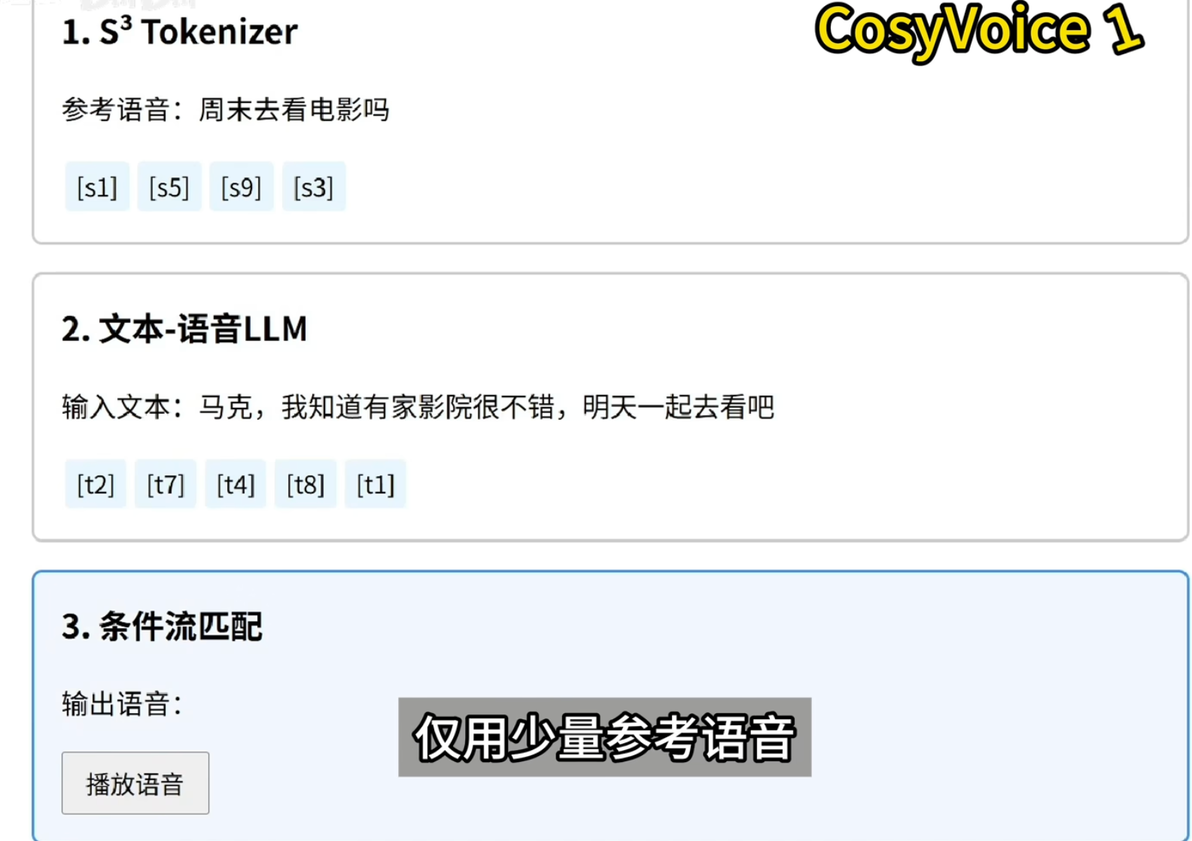
Cosyvoice的核心流程:零样本语音克隆。上侧模块从参考语音中提取带语义的S3 token。就像给语音内容贴标签。
中间的LLM模块根据输入文本生成对应的tokens序列。同时参考说话人的音色特征。
下侧流匹配模型将tokens转换为可听语音。
整个过程无需提前训练,仅用少量参考语音,就能模仿说话人音色。这是cosyvoice最关键的创新。

Cosyvoice2的核心改进:流式合成。
与Cosyvoice必须等待完整文本不同,cosyvoice2能边输入文本边生成语音。用户输入马克两个字之后,第一个语音立即生成,无需等待完整句子。
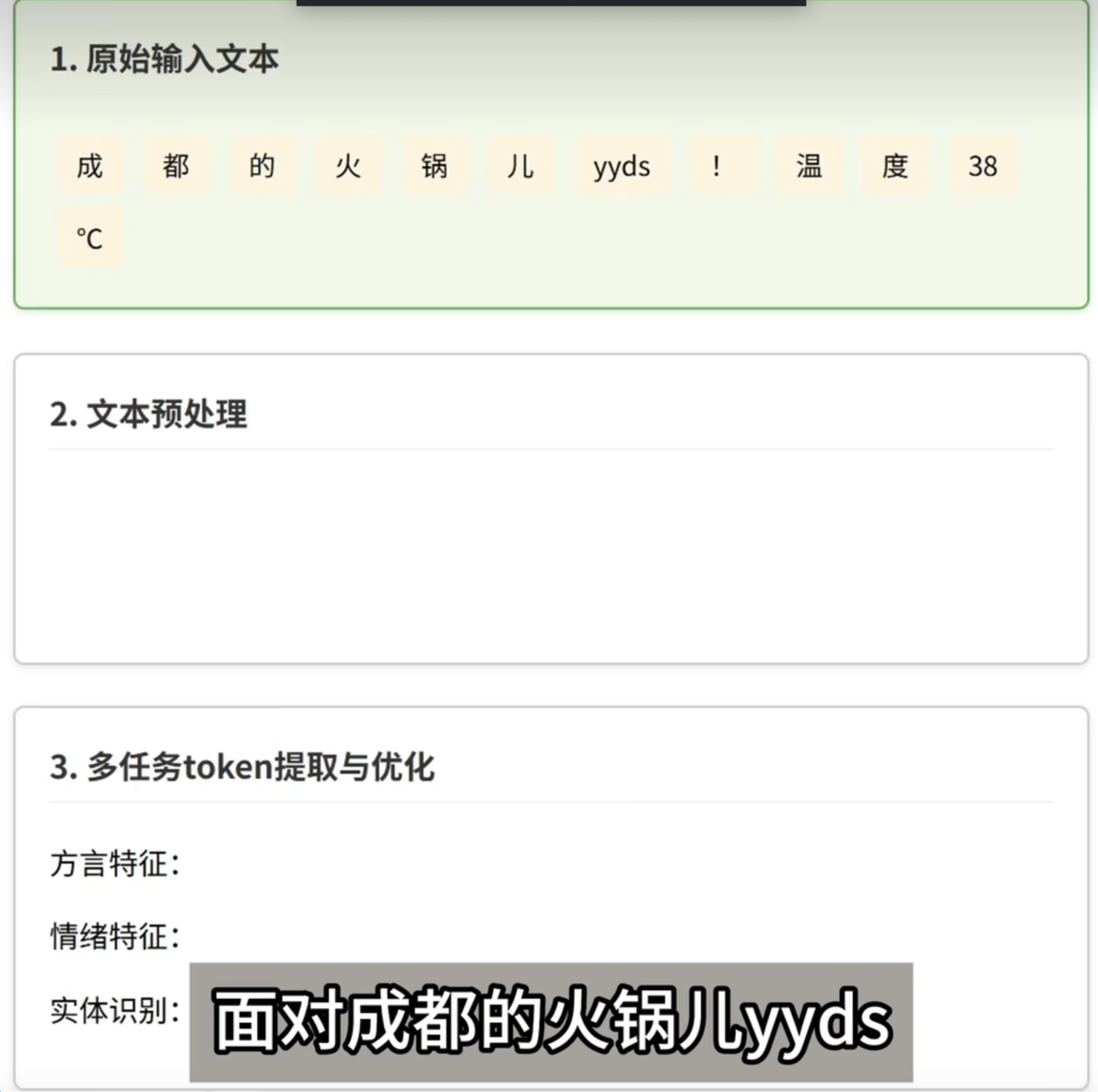
cosyvoice3的核心能力:处理真实场景的复杂文本。
面对上述原始输入文本,这种含有方言,网络热词和特殊符合的文本。他能通过发音修复,将yyds转化为永远的神。通过文本归一化将数字38C转化为中文文本三十八摄氏度。还能提取四川话儿化音和兴奋等风格特征。最后通过DiffRO优化确保语音清晰。
这种接地气的能力是前两代模型不具备的。
Cosyvoice核心创新
提出监督语义tokens (S3 tokens),强化语义对齐
采用LLM+条件流匹配的双阶段架构
支持零样本语音克隆,仅需少量参考语音
无需音素时长预测,简化传统TTS流程
通过x-vector分离语义与音色
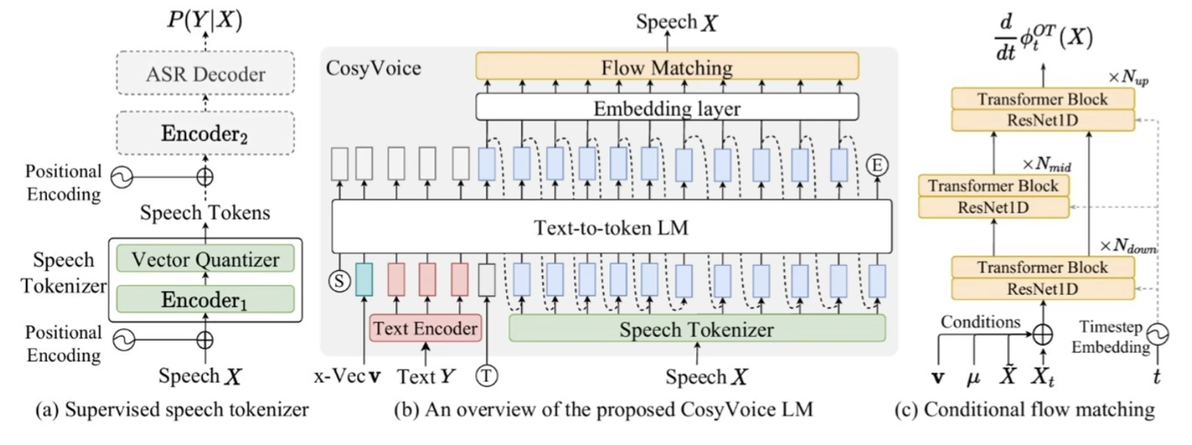
传统LLM-based TTS使用无监督语音tokens,存在语义模糊和文本对齐差的问题。Cosyvoice的核心idea是从语音识别模型中提取监督语音tokens:S3 tokens。
如图1(a)所示,通过在ASR模型编码器中插入向量量化层,让tokens直接关联文本语义。这种tokens就像带字幕的语音片段,每个token都对应明确的文字含义。解决了语义模糊问题。
接下来,作者介绍LLM如何以文本为条件生成tokens序列,如图1(b)。再通过条件流匹配模型将tokens转换为语音,如图1(c)。
这种双阶段架构,无需传统TTS的音素时长预测模块,就像先写好带节奏的剧本,再按剧本演戏,流程更简洁。
零样本克隆能力尤为实用,只需3s参考语音,就能提取x-vector音色特征,让模型模仿任何人的声音。
表7的结果显示,相比Vall-e,UniAudio等基线模型,Cosyvoice在内容一致性WER降低50%以上,和说话人相似度SS提升15%。这得益于5个模块协同工作:
S3 tokenizer确保语义准确
文本编码器实现跨模态对齐
LLM负责序列生成
flow match转化为语音
x-vector保证音色一致
Cosyvoice2核心创新
支持流式/非流式统一合成,适配实时场景
用FSQ替代VQ,codebook利用率达100%
复用预训练文本LLM(如Qwen 2.5),简化架构
设计块感知flow match模型,平衡延迟与质量
强化指令控制,支持情绪,方言等调节
Cosyvoice1只能等完整文本输入后再合成语音, 不适合实时交互。Cosyvoice2的核心idea是实现流式合成,即边输入文本边合成语音。
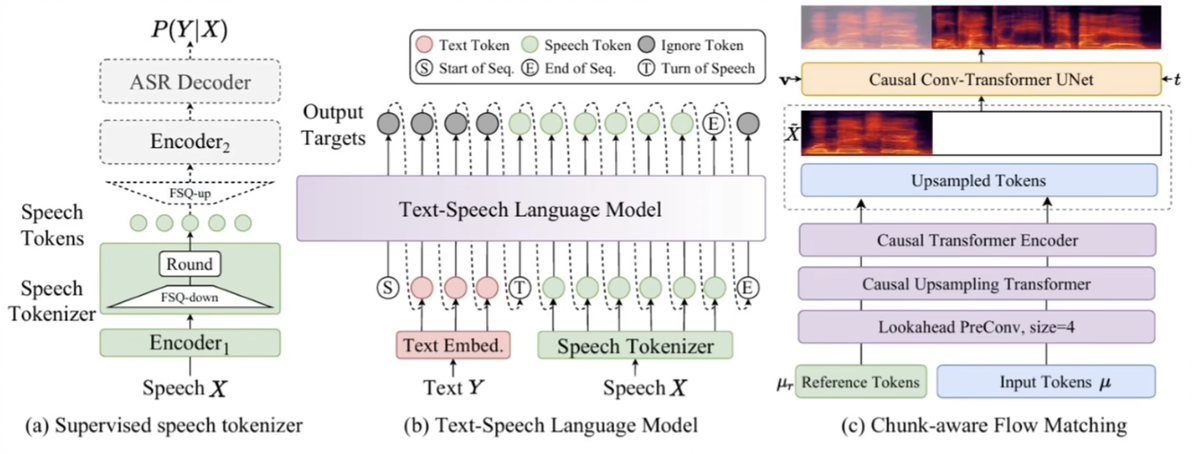
如上述b和c所示,通过交替排列文本和语音tokens,每5个文本token对应15个语音token,让模型无需等待完整文本就能开始合成。
另一个关键改进是在speech tokenizer中用finite scalar quantization (FSQ)替代vector quantization (VQ) 。FSQ能让codebook全量利用,就像从只用到23%的字典到每个字都用上,语音细节更丰富。
复用Qwen2.5等预训练LLM,移除冗余模块,让模型更轻量高效。
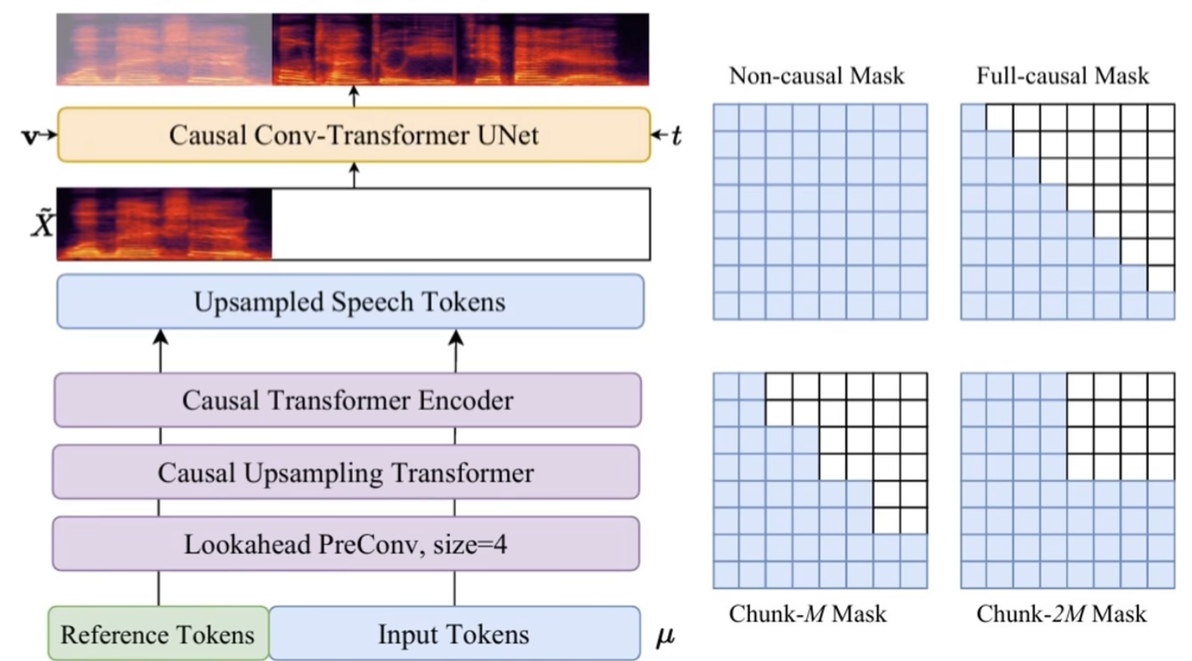
块感知flow match模型设计了4种mask策略,可根据需求选择。实时对话用低延迟mask,小说朗读用高质量mask。
块感知flow match的4种mask策略是平衡延迟与质量的关键,全因果mask适合实时对话,最低延迟。非因果mask适合离线合成最高质量,块mask则是中间选择。
Cosyvoice3核心创新
提出多任务监督语音tokenizer,融合多模态信息
引入可微分奖励优化DiffRO,提升生成鲁棒性
数据规模扩展至100万小时,覆盖9种语言和18种方言
模型参数增至1.5B,增强复杂文本理解能力
支持发音修复和文本归一化,适配真实场景
前两个模型难以处理方言混杂,网络热词和噪声环境。
cosyvoice3的核心idea是通过大规模数据和多任务学习,让TTS模型适应野外场景,
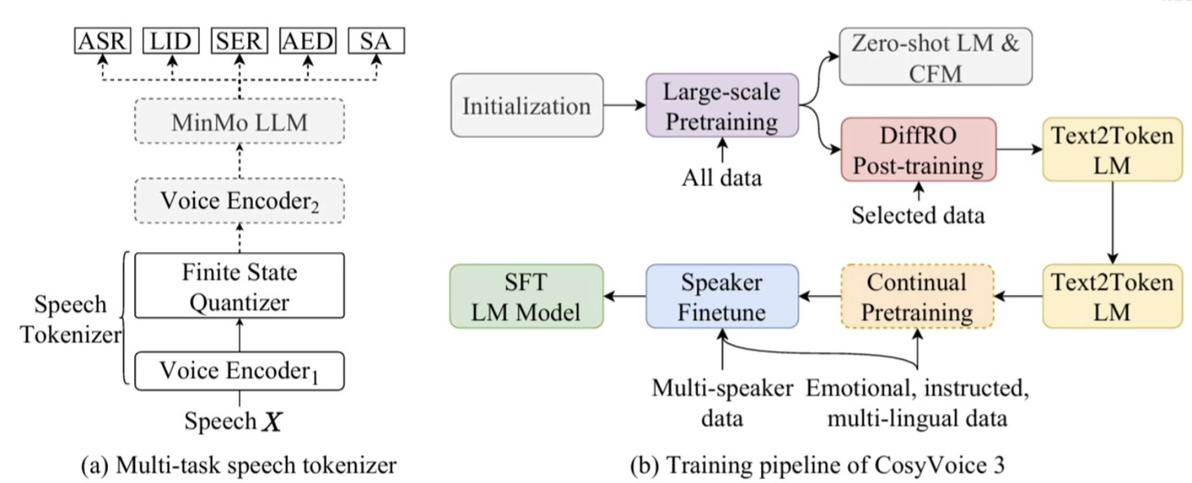
如上图所示,多任务监督tokenizer在原有语义基础上,融合里情绪识别SER,语言识别LID等任务信息,让tokens不仅携带文字含义,还包括开心,四川方言等风格特征。
数据规模从10万小时扩展至100万小时,相当于让模型读遍全球书籍,见过更多罕见表达。
1.5B参数的LLM增强了语义理解能力,可处理多音词。
可微分奖励DiffRO是另一突破。通过ASR模型的识别结果作为反馈,自动修正发音错误。就像让模型自己听自己说的话并纠错,在噪声环境中也能保持清晰。
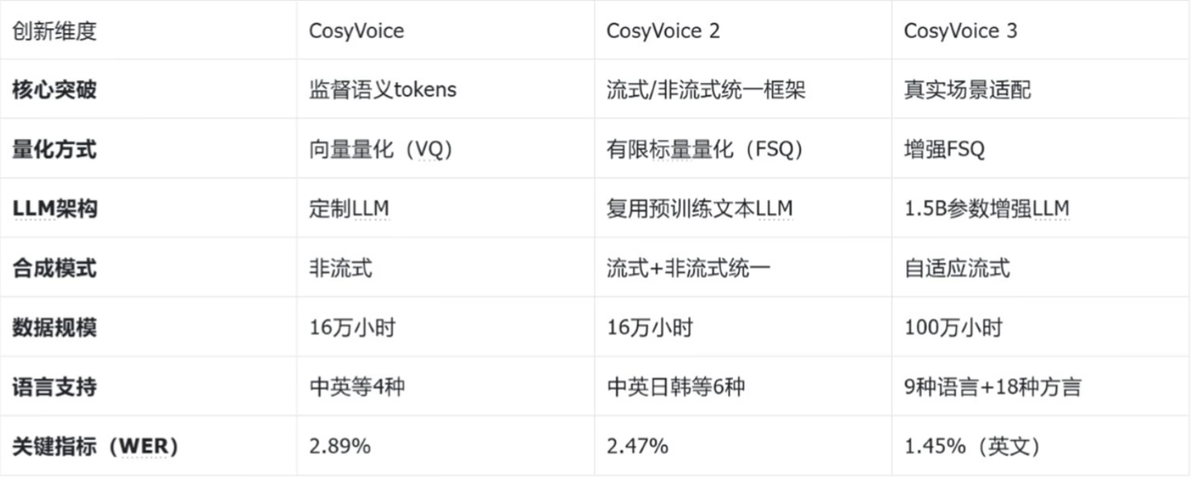
Cosyvoice的演进呈现3个清晰方向:
WER性能提升
内容一致性提升,这得益于从监督tokens到多任务tokens的技术升级,让语音和文本的对齐越来越精准
场景扩展:从仅支持非流式合成适合新闻播报,到cosyvoice2的流式,非流式统一支持实时对话,再到cosyvoice3的真实场景适配,支持方言,噪声环境。模型参数从0.5B到1.5B。VQ到FSQ再到增强FSQ,逐步释放语音细节的表达能力,这是音质提升的关键。
结论:
核心贡献总结:
cosyvoice监督token解决语义对齐
cosyvoice2流式结构适配交互
cosyvoice3大规模学习提升鲁棒性
技术演进规律:从实验室理想场景走向真实世界复杂场景到持续优化
未来研究方向:
更低延迟的流式合成(<100ms)
跨模态指令控制(文本+图像控制语音)
小样本方言适应(少量数据适配稀有方言)
歌唱合成(扩展至唱歌场景)
Cosyvoice通过监督语义tokens突破传统TTS的语义对齐瓶颈,证明语义明确的tokens是高质量合成的基础。
Cosyvoice2通过流式架构与模型简化,解决实时交互痛点,让技术走向使用。
Cosyvoice3通过大规模数据和多任务学习,提升模型在真实场景的鲁棒性,实现从能合成到合成好的跨越。
