
非翻译区(UTR, Untranslated Regions)位于mRNA编码区域(CDS)的两端。CDS上游为5' UTR,从mRNA起点的帽结构至AUG起始密码子;CDS下游为3'UTR,从CDS终止密码子至poly(A)。
特定基因来源的天然UTR序列,在当前最为热门的mRNA疫苗/药物研究领域应用广泛。不同来源的UTR影响mRNA的翻译效率,因此,我们需收集多种来源的UTR序列,以匹配个性化的mRNA CDS序列。
NCBI GenBank是一个公开的核酸序列数据库,提供多种基因的编码和非编码区序列。本期文章,菌菌将分享:如何使用NCBI GenBank数据库查询基因的5’UTR和3’ UTR序列,以直接应用于mRNA序列的设计和优化。
1 基因查找
首先是基因查找:以人源的α-珠蛋白(α-globin)为例,首先进入NCBI官网(www.ncbi.nlm.nih.gov),选择Gene查询,输入α-globin,点击对应的人源(Homo sapiens (human))基因序列,进入基因页面。
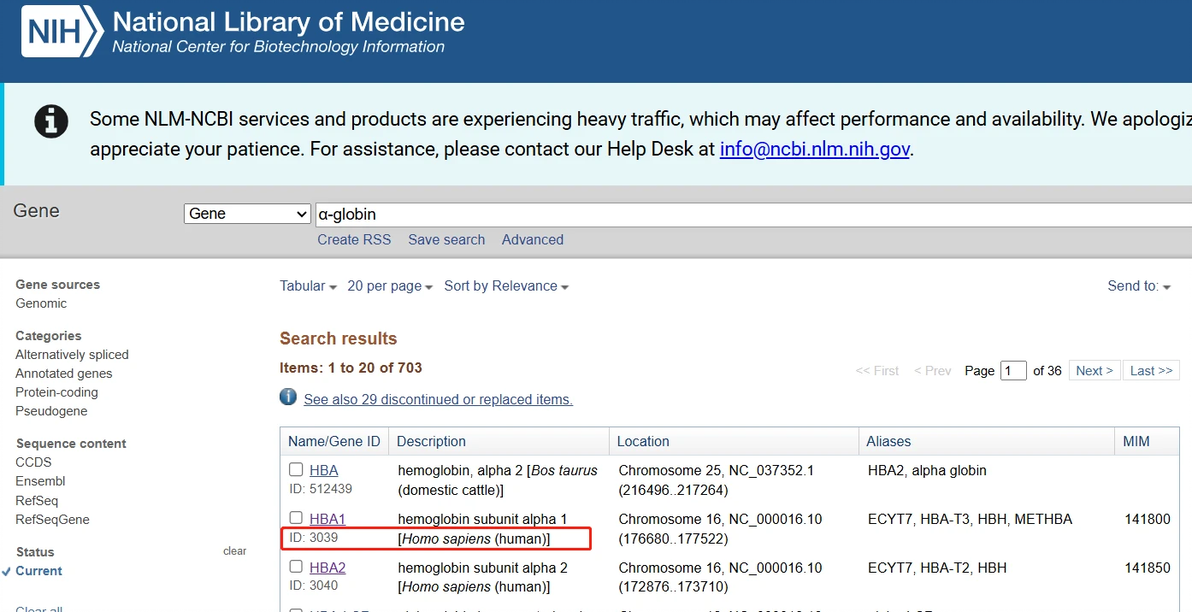
2 基因组分析工具
在基因页面,下拉至“Genomic regions, transcripts, and products”部分,点击“工具(Tools)”下的“查看序列(Sequence Text View)”,即可弹出“序列预览”窗口。
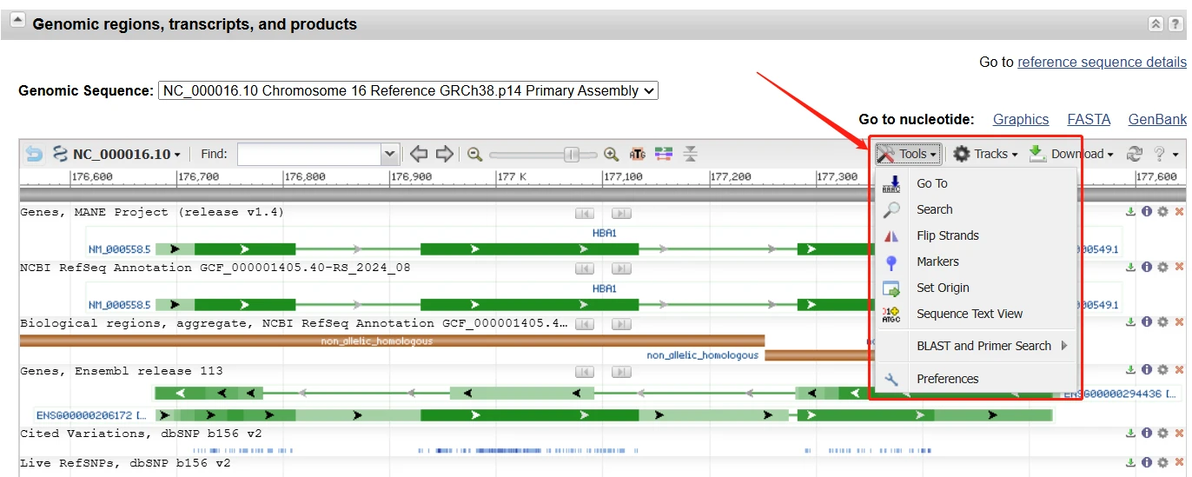
3 序列预览
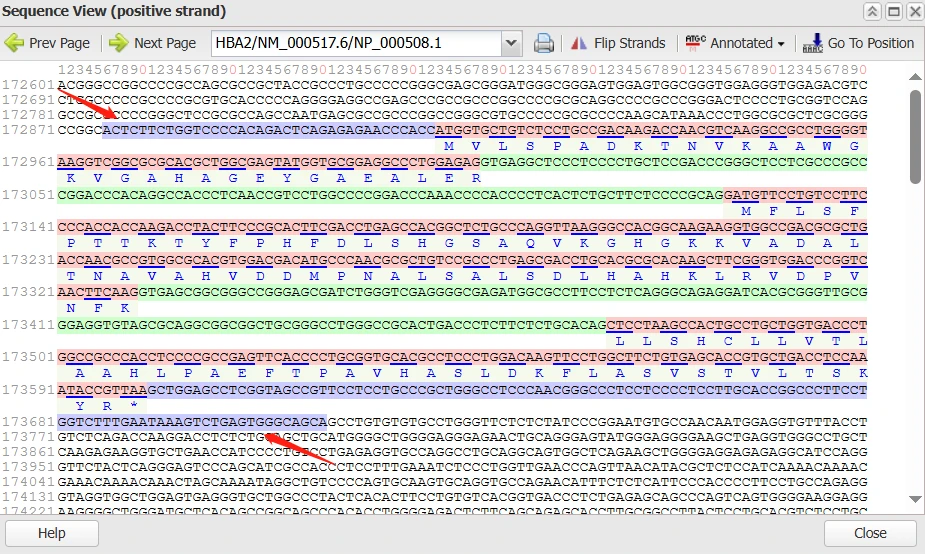
在“序列预览窗口”中可看到,不同的序列元件被标识了不同的颜色,其中UTR序列背景为浅紫色(或蓝紫色,如图片中红色箭头指示。编码区域的上游为5’UTR序列,下游为3’ UTR序列)。
mRNA UTR序列的设计至关重要,直接影响mRNA的稳定性和翻译效率等成药相关特性。根据青鸟核酸(RNASci)丰富的项目经验,UTR对不同编码序列的翻译效率具有明显影响。我们收集并形成了常用于mRNA序列设计的UTR文库,如感兴趣可联系菌菌获取:199 2658 2926。
