
🌟 教程导读
本期专栏作为Olares本地AIGC教程系列的第三讲,将正式进入文生图(Text-to-Image)的核心内容,从界面功能,到模型选择、提示词写法、采样与种子设置,讲解每一个关键参数的作用与使用逻辑,帮助你掌握稳定扩散图像生成的基本功,让你精准控图。
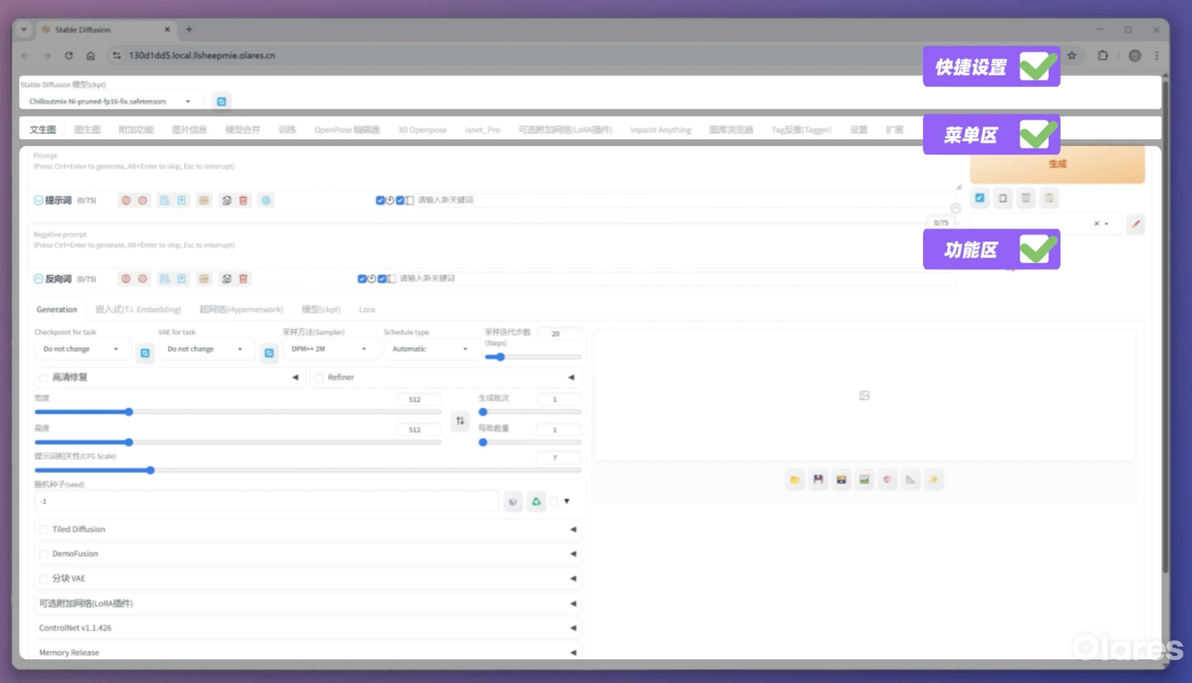
熟悉 SD WebUI 界面布局
SD WebUI 的主界面可分为三部分:
顶部快捷设置区域:用于快速调整关键参数,默认只显示“模型选择”下拉框。
中部菜单栏:选择要执行的功能模块,默认是“txt2img(文生图)”。
底部功能区:根据所选功能显示相应操作控件。
小贴士:某些插件在重启 SD WebUI 后可能失效,可通过“扩展”面板重新启用。
文生图工作流程概览
我们将按生成流程,依次介绍每一项参数设置的作用与推荐用法。
模型下载、管理及使用
Olares 中内置了常见的 Stable Diffusion 模型:
ChilloutMix:擅长写实人像,适合生成高质量人像图。
DreamShaper:通用型模型,兼容写实与插画风格,推荐新手使用。
JuggernautXL Lightning:支持仅用 4 步出图,适合追求高效的用户。

尽管内置模型能满足多数需求,但AIGC社区模型迭代迅速,你可能需要尝试最新的流行模型或针对特定领域特化训练的模型。
Civitai(俗称C站,civitai.com)是目前最流行和资源最丰富的模型分享社区之一(访问可能需要网络“魔法”)。C站资源除了Checkpoint大模型,还包含 LoRA、Embedding (Textual Inversion)、图片作品、教程、工作流(Workflows)等。
你可能会在 C 站上不同模型的封面看到这些关键词:
Checkpoint:指的就是我们这里讨论的Stable Diffusion大模型文件,它们是AI绘画的基础。在C站模型的封面上,通常左上角会标明其类型,如“CHECKPOINT”。
Pony:特指基于 Stability AI 发布的 Pony Diffusion XL 模型进行微调或衍生的模型,通常在动漫风格、画面细腻度上有出色表现。
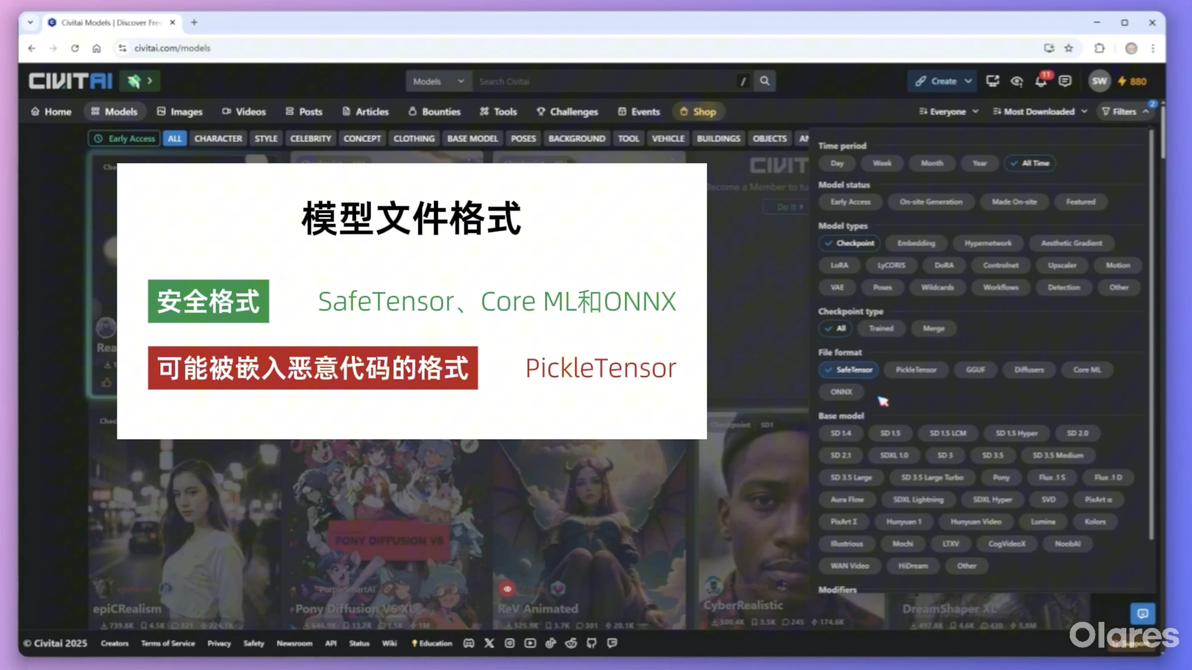
F1:指基于 Black-Cookie 开发的 FLUX.1 系列模型。FLUX是一种新的扩散模型架构,旨在提高效率和生成质量。 注意下载模型时,应选择安全的文件格式。例如 SafeTensor、Core ML 和 ONNX。“PickleTensor”可能会被嵌入恶意代码。
下载其他模型
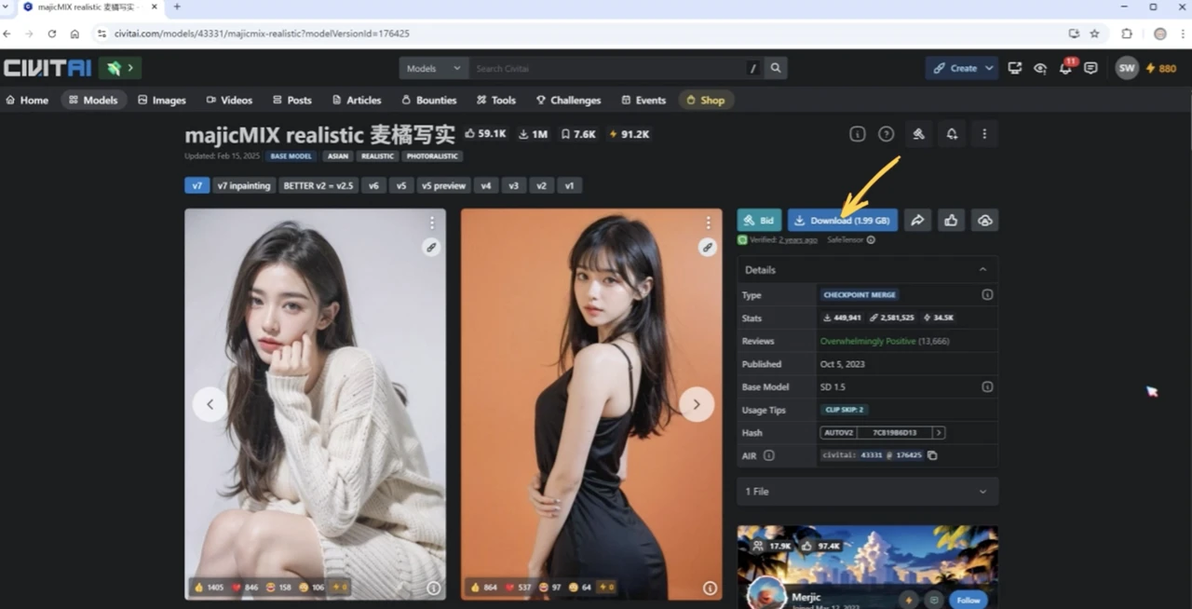
以“麦橘写实”为例:
1. C 站筛选并找到目标模型,点击模型封面进入详情页。通常模型有多个版本(如 V7 代表最新版)。
2. 点击右侧的“Download”按钮下载。
提示
留意作者在模型描述中提供的推荐使用参数(如采样器、步数、CFG等),这通常是基于模型训练特性给出的优化建议。
3. 下载后将模型放入 Olares 文件管理对应目录:
外部设备 > ai > model > main提示
建议在此目录下创建子文件夹进行分类管理(例如,新建一个“人像 (Portraits)”目录),然后将下载好的模型文件(如 .safetensors 文件)放入相应目录。
4. 打开 SD WebUI ,点击模型选择下拉菜单旁的“刷新 (Refresh)”按钮。新下载的模型便会出现在下拉列表中,选择它即可加载。
种子
种子决定初始噪声图,从而影响最终结果。配合使用不同的种子,即使是同样的参数也能生成不一样的结果。这就是俗称的“抽卡”。
随机种子:设置为“-1”表示每次生成随机种子,会影响扩散过程中的第一张图,也就是初始噪声的生成
固定种子:可复现图像结果,便于对比与调试
变异种子:在保留原图基础上略作变化,适合“抽卡出好图后微调”
变异强度越低,生成图越接近原图。可以通过 X/Y/Z 脚本批量测试不同强度的效果差异。
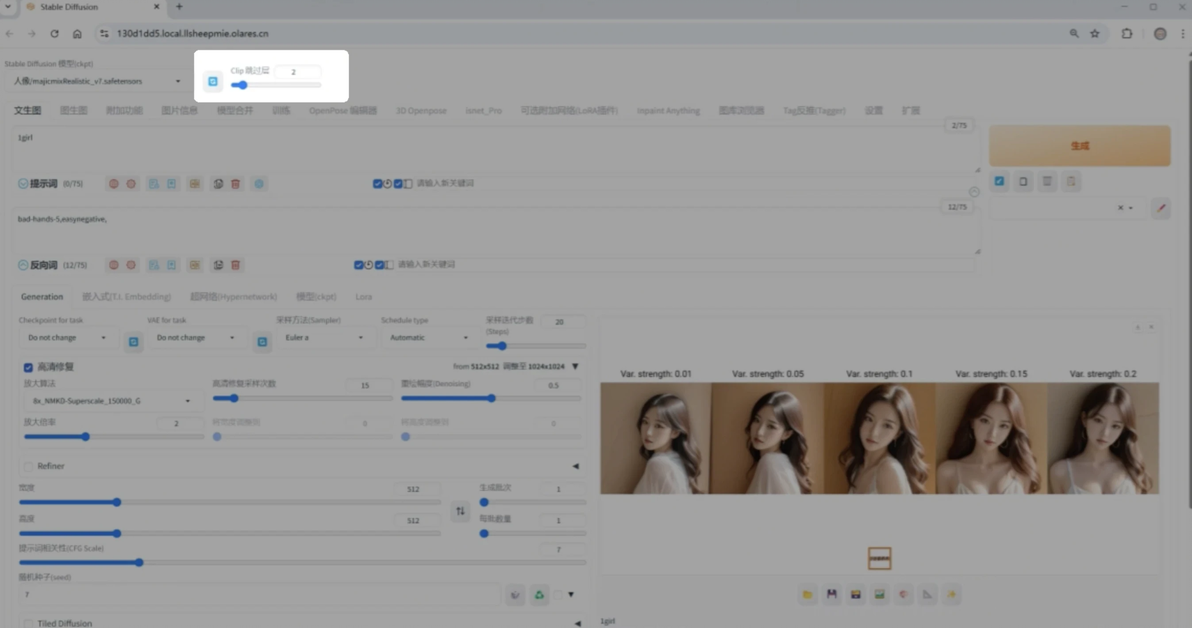
Clip 跳过层数
CLIP (Contrastive Language-Image Pre-Training) 是一个理解文本提示词并将之转换为图像特征的模型。它由多个层组成。控制 CLIP 模型的推理深度,此参数允许在CLIP模型进行推理时,跳过最后若干层。
参数越大 ,跳过的层数越多,虽然速度快了 ,但会导致提示词理解能力下降,引入了不确定性。
默认值为 1(全层运行)
设置为 2 或以上可加速推理,但可能影响提示词解析效果
除非模型明确要求修改,否则建议保留默认值
提示词
提示词是引导AI生成期望图像内容的核心指令。
1. 不同模型支持的提示词格式
提示词是控制生成内容的核心,不同的模型使用了不同的文本编码器(Text Encoder),因此支持的提示词格式也有所不同。
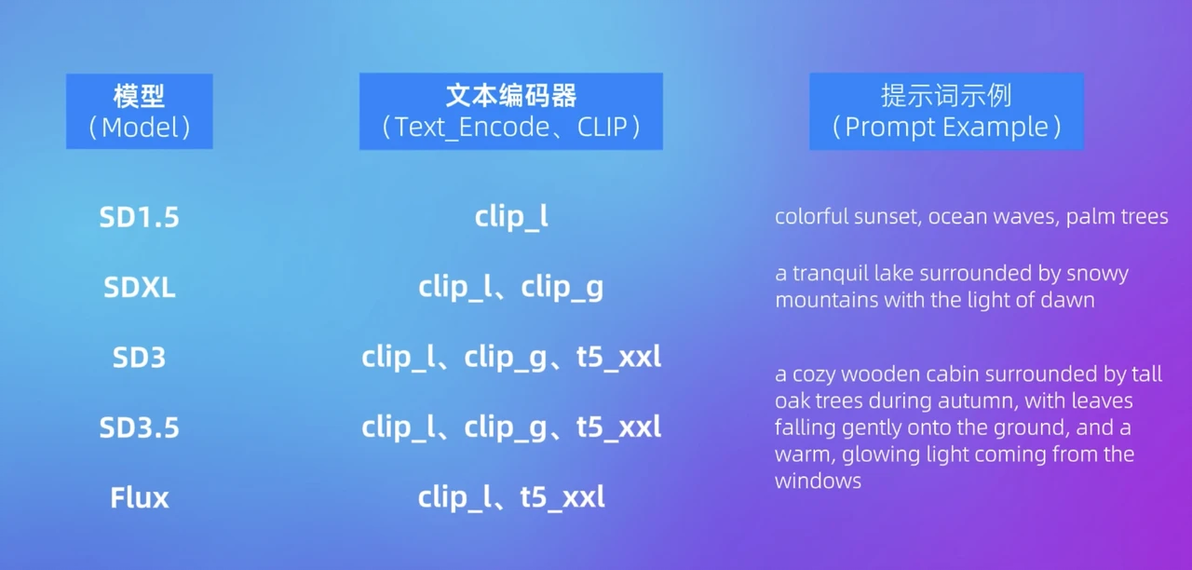
SD1.5模型:通常搭配单独的 CLIP ViT-L/14。偏向“标签样式提示 (tags)”,适合使用简单、分段的关键词。
SDXL模型:同时使用 CLIP ViT-L/14 和 OpenCLIP ViT-G/14 (或 CLIP ViT-bigG/14)。支持更复杂的提示词结构,能解析短语中的语义关系和描述层次。
SD3 / Flux系列模型:引入更强大的文本编码器如 T5XXL,具备更强的自然语言处理能力,能充分理解句子中的描述关系、修饰语细节及逻辑联系。
请根据模型类型选择合适的提示词风格,避免提示词格式不匹配影响结果。
2. 正面提示词与负面提示词
正向提示词:描述希望生成的画面内容。
负面提示词:用于排除不希望出现的特征。
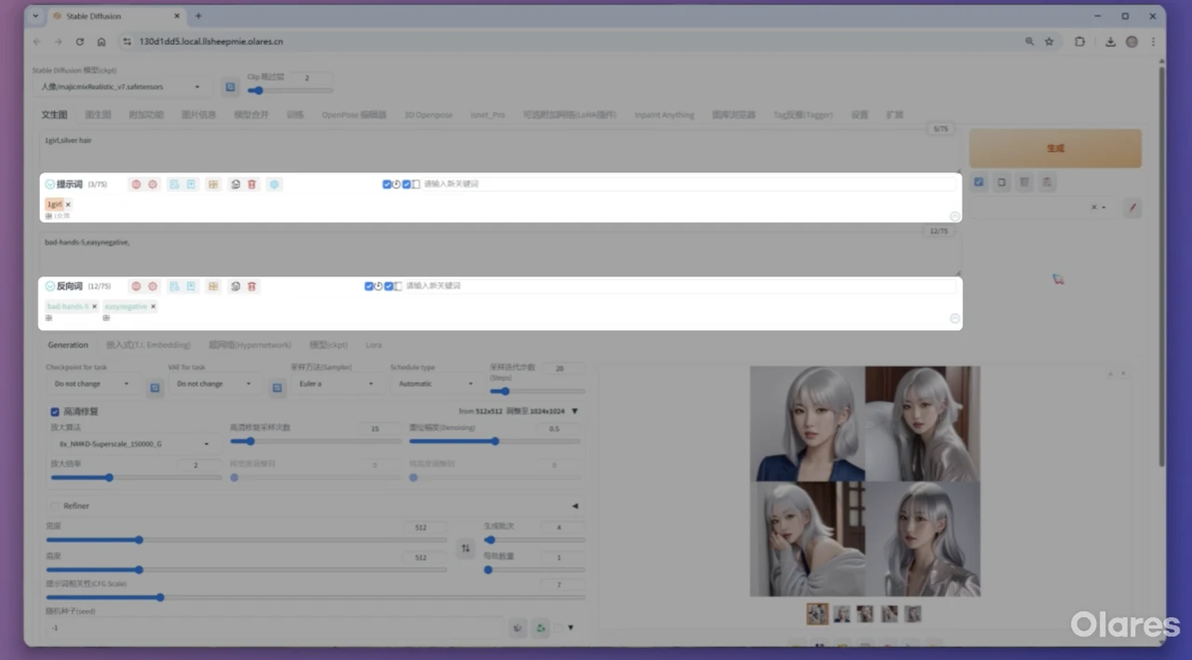
即使没有特别想排除的具体事物,也建议在负面提示词中加入一些通用的、提升画面质量的词条,如 low quality, worst quality, normal quality, jpeg artifacts, blurry, watermark, signature, text, error, bad anatomy, bad hands, deformed, mutated, extra limbs 等。
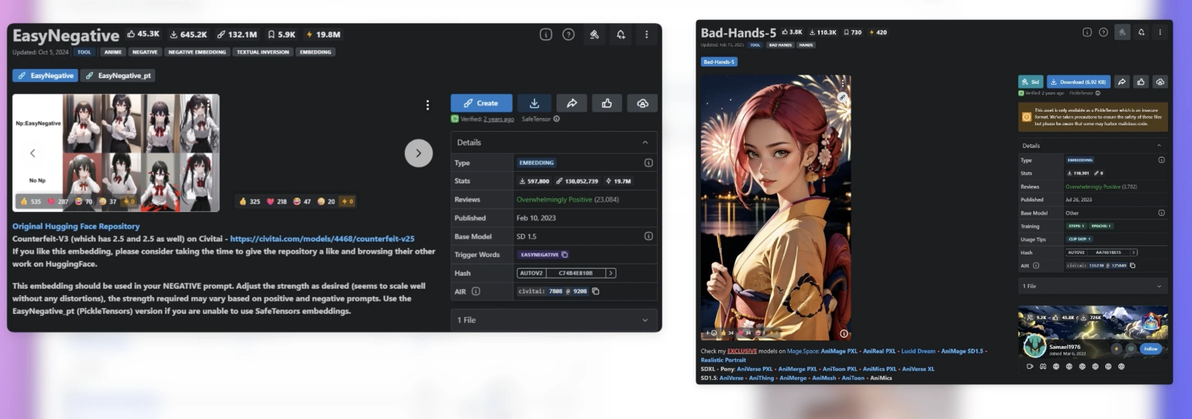
嵌入式(T.I. Emdedding)模型,你可以理解为它们是预训练好的特定的负面提示词的集合。比如下面这两个模型:
Easy Negative:偏向于整体画面质量优化,能减少画面瑕疵和不协调的细节问题。
bad-hands-5:专门针对人体肢体生成的问题如解决手指数量错误、手势畸形、肢体变形等。
3. 提示词语法
✅ 如何调整权重(提示词优先级)
使用英文半角括号“()”可以增加权重,每层提升 10%。
(word):将 word 的权重乘以1.1。
((word)):权重乘以 1.1 * 1.1 = 1.21。
(word:factor):直接指定权重因子,如 (red flower:1.5) 将红花的权重设为1.5。使用中括号“[]”可以降低权重,但降权效果通常不如加权明显。
[word]:将 word 的权重除以1.1(约等于乘以0.909)。使用下列提示词生成图片时,红花更多,白花相对减少。
garden, (red flower:1.21), [white flower] ✅ 如何调整提示词影响链
提示词顺序会影响生成优先级,默认情况下,越靠前越重要。但是我们可以用关键词手动调整。
red apple, shiny BREAK blue sky, clouds效果:生成一部分是“红色的光亮苹果”,另一部分是“蓝天白云”,两者互不影响。
AND 关键字可以将两个或多个概念融合到同一个主体或场景中,而不是简单并列。
cat AND flower效果:生成一只“和花融合在一起的猫”,而不是单独生成猫和花。
✅交替提示词(Alternating Prompt)
交替提示词可以通过调整提示词的作用时间,在采样过程中生成融合特征的图像。适用于混合两个或多个概念的图像生成。
基本格式为:
[word1|word2]如果要精确控制两个提示词的影响时间比例:
[word1:word2:step_fraction]其中,step_fraction 是一个 0 到 1 之间的小数,表示第一个提示词作用的时间占比。
例如,下列提示词汇生成一副猫和猫头鹰混合特征均衡的图像。
[cat:owl:0.5] 而下列提示词生成的图像,会更倾向于“猫”的特征:
[cat:owl:0.7]
4. 提示词相关性CFG
CFG Scale控制生成图像在多大程度上与您的提示词保持一致(相关性)。
值越高,模型将更严格地遵循提示词中描述的内容和风格,减少自由发挥和“想象”的部分。图像更“贴题”。值越低,模型有更大的创作自由度,可能会在提示词未明确指定的方面进行更多探索,图像可能更多样化,但也可能与提示词的关联度降低。
大部分情况下,CFG Scale的值在 6 到 11 之间能获得比较理想且平衡的效果。一个常用的默认值是 7。如果生成的图像与提示词的匹配程度不佳,可以尝试调整此值。
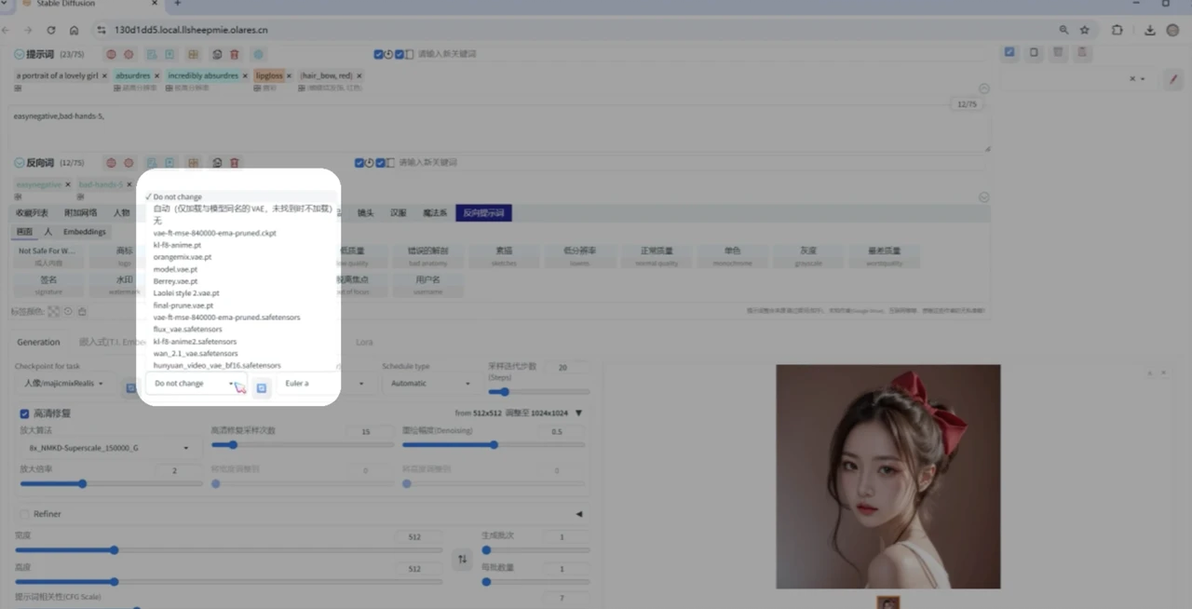
VAE
VAE 负责将潜空间(Latent Space)中的数据解码为我们最终看到的像素图像,也负责将输入图像编码到潜空间(如图生图)。大部分 SD1.5 和 SDXL 模型都内置了 VAE。
如果生成的图像颜色发灰、饱和度低或出现奇怪的色块,很可能是当前模型的内置 VAE 存在问题或不适合当前任务。此时,可以在“设置 (Settings)” > “Stable Diffusion” > “SD VAE”下拉菜单中手动选择一个外挂 VAE。
常见VAE推荐
vae-ft-mse-840000-ema-pruned.safetensors:一个高性能、针对真实感和高分辨率解码强化的通用 VAE,适用于多数写实场景。
kl-f8-anime2.ckpt(或类似名称的anime专用VAE):在动漫风格图像生成中效果出色。
注意
VAE 选择问题在 SD1.5 衍生模型中相对常见。SDXL 模型通常配套有专用 VAE,或其内置 VAE 已足够优秀。
采样方法、调度器与步数
在扩散模型的图像生成过程中,采样方法、调度器(Scheduler) 和 步数(Steps) 是影响画面质量、风格多样性和生成速度的重要因素:
采样方法(Sampler):是用来执行“每一步计算”的数学算法,它决定了生成过程的具体路线图。不同方法对应不同的数学逻辑,有的更快,有的更精细。
调度器(Scheduler):负责管理每一步去噪时使用的“步长权重”和“噪声量”,可以理解为控制每一步力度与节奏的节拍器。
步数(Steps):则定义了生成图像时所进行的“总迭代次数”。步数越高,图像理论上越清晰,但时间也更长,过高反而容易过拟合或无明显提升。
三者组合之后,直接影响图像的清晰度、风格、细节,甚至是生成时间。
如果你使用的模型给出了推荐搭配(比如推荐某个采样器或固定步数范围),那就按模型的推荐。这是因为很多模型在训练时,默认使用了某一套采样流程,这样能获得更理想的输出效果。
如果你是新手,可以直接使用下面这套“省心组合”:
采样方法:Euler 或 Euler a。
Euler 是基础欧拉采样,速度快、表现稳定;
Euler a 中的 a 是 Ancestral(祖先采样)的意思,它在每个采样步骤中加入随机噪声,使图像更具多样性。
调度器:Automatic
让 SD WebUI 自动选择最适合你所选采样器的调度方式,适用于大多数情况。
步数:15~25 步
这是当前主流模型的推荐范围,生成速度与质量之间取得不错的平衡。
高清修复
在生成低分辨率图像的基础上,通过放大并进行二次精炼,得到细节更丰富的高清大图。关闭Hires. fix生成的图像(如512x512)可能显得模糊,启用后(如放大到1024x1024)则细节显著提升。
放大算法
放大算法(Upscaler)是执行放大操作的核心。主要分为两大流派:潜空间放大和像素空间图像放大。
潜空间放大 :如 Latent, Latent (nearest), Latent (bicubic antialiased),以及文中的 Lanzos。它们在潜空间对特征图进行放大,理论上速度较快(因省去VAE编解码过程),但质量可能略逊于像素空间放大算法。
像素空间图像放大:如 R-ESRGAN 4x+, SwinIR_4x, ESRGAN_4x, 4x-UltraSharp, 以及文中提到的 8x_NMKD-Superscale_150000_G。这些算法直接对像素图像进行放大和增强,通常效果更好,细节更丰富。
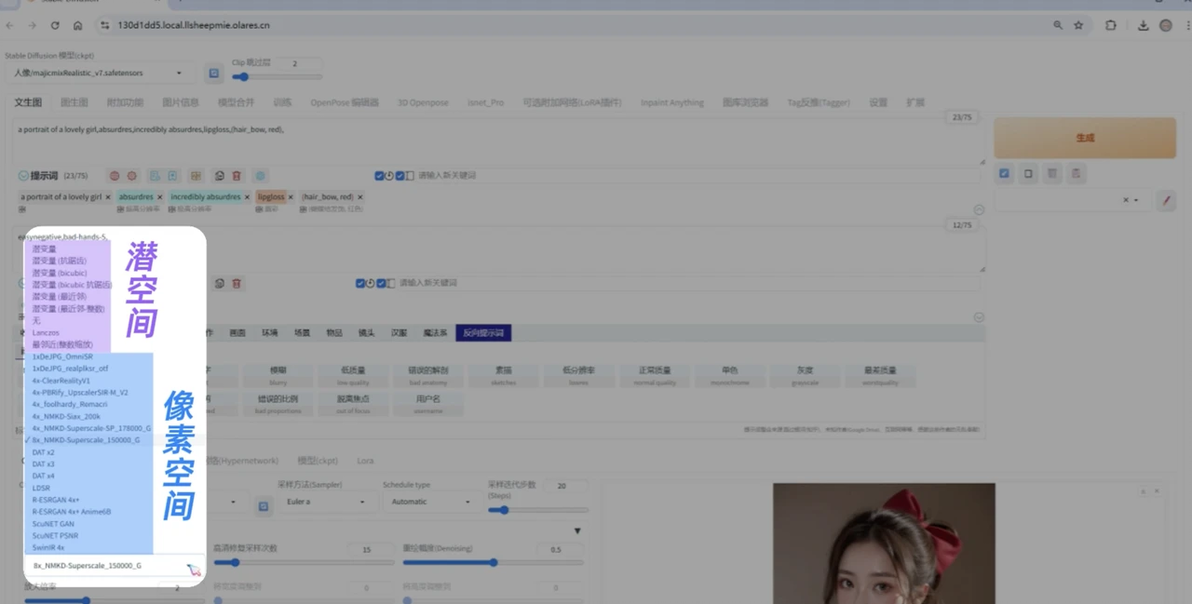
个人偏好和具体图像内容会影响最佳选择,可以多尝试几种。
1. 高清修复采样次数
指在放大后的潜空间数据上进行二次采样的步数。一般设置为0则使用与主采样步数一致,也可以设为10-20步。
2. 重绘幅度
非常关键的参数,范围0到1。它控制了在高清修复阶段,模型在多大程度上参考原始低分辨率图像的内容。对比0.2, 0.5, 0.8的效果,可以观察到0.8时图像内容(如头饰)可能发生显著变化。
较低值(如 0.1 - 0.4):更倾向于保留原始图像的构图和主体内容,主要在细节上进行优化和丰富。
中等值(如 0.4 - 0.6):在保留原图结构的同时,允许模型进行一定程度的再创作和细节添加。0.5是文中示例值。
较高值(如 0.7 - 1.0): 模型会更大胆地修改原始图像,可能生成与原图构图有较大差异的新内容,但细节可能更丰富或更符合高分辨率下的表现。
3. 放大倍率
直接指定放大倍数。如原图512x512,放大倍率2,则输出1024x1024。也手动设置高清修复后图像的最终宽度和高度。
建议保持与原图一致的宽高比,否则可能导致图像被不成比例地拉伸或裁剪。例如,原图512x512 (1:1),若高清修复目标设为1024x1536 (2:3),则最终图像可能是原图中央部分按2:3比例裁剪放大后的结果。
注意
一旦手动调整了宽高数值,想重新使用“放大倍率”,需要将这两个滑动条的值手动恢复为0。
Refiner
Refiner(精炼器)是一个可选的第二阶段模型,主要与 SDXL 基础模型配合使用。它允许在主(Base)模型完成了大部分采样步骤后,将潜空间数据传递给一个专门用于提升图像细节、质感和最终视觉效果的 Refiner 模型进行后续的少量采样。
主要是在使用SDXL官方基础模型(SDXL Base)时使用,可以配合官方发布的 SDXL Refiner模型。在 SD WebUI 中,通常会有选项让你选择 Refiner 模型,并设置一个“切换时机 (Switch at)”参数(如0.8,表示Base模型完成80%的采样步数后切换到Refiner)。
注意
如果使用的是社区基于 SDXL Base 或其他基础模型进行了精细微调的 Checkpoint(例如,很多在 C 站上下载的针对特定风格优化的模型),这些模型往往已经能够直接输出高质量的作品,通常不太需要额外再启用 Refiner 功能。强行使用不匹配的 Refiner 反而可能破坏效果。
尺寸(宽度和高度)
设定初始生成图像的尺寸(在Hires. fix之前的尺寸)。一般不会调整,但是注意不同模型支持的尺寸会有差异:
SD1.5衍生模型:通常在 512x512、512x768、768x512 等尺寸范围内表现最佳。直接生成过大尺寸(如1024x1024)效果通常不佳,可能出现重复、崩坏或“力不从心”的感觉(如文中用麦橘人像模型直接生 成1024x1024 的演示)。
SDXL模型:训练数据分辨率更高,原生支持 1024x1024 及附近的尺寸,如 1024x768、768x1024、1152x896、896x1152 等。
【3】获取更大尺寸
主要依赖“高清修复 (Hires. fix)”功能,它通过分块(Tiled)生成或潜空间放大技术,可以将图像有效扩展到2K甚至更高分辨率。
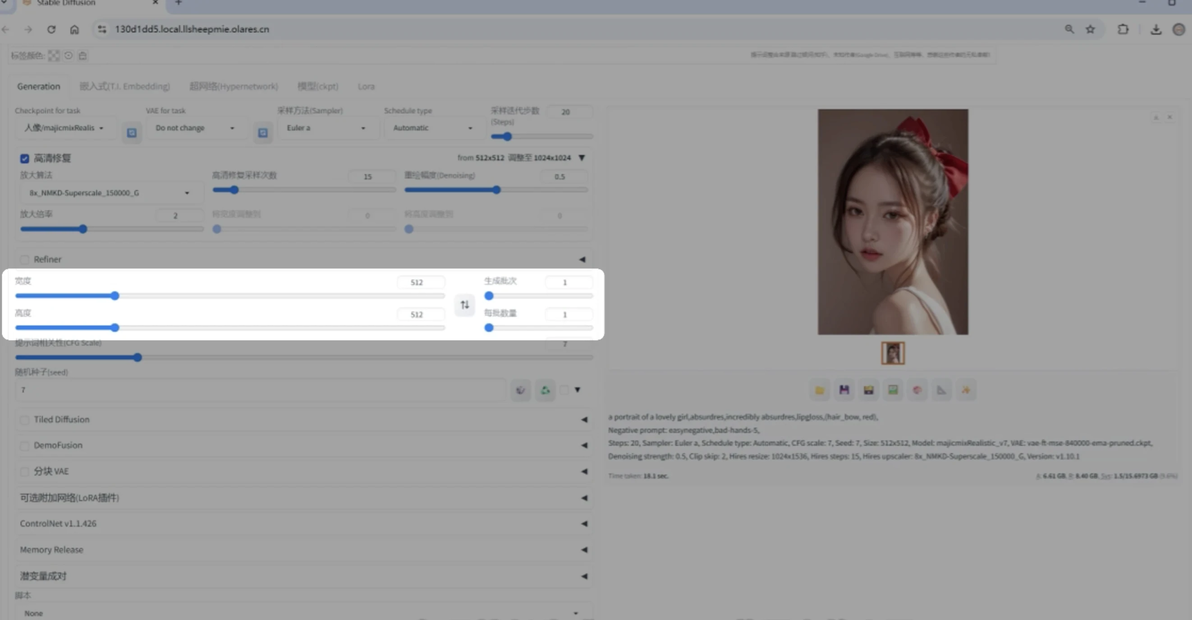
生成批次(Batch count)和每批数量(Batch size)
在生成图像时,生成批次(Batch count)和每批数量(Batch size)是两个重要参数,它们决定了图片生成的数量、显存消耗以及生成效率。
生成批次是指模型完整运行生成流程的次数。例如,设置 Batch count 为 2,表示生成两次,每次使用不同的种子。每批数量指的是每次生成时同时生成的图片数量。例如,Batch size 为 3,表示每次生成 3 张图片。
两者的关系可以通过以下公式表示:
总图片数 = 生成批次(Batch count) * 每批数量(Batch size)显存消耗
每批数量越大,单次运行时占用的显存越高。生成批次的增加不会改变单次运行时的显存需求,但会增加运行次数,因此总时间会变长。
生成效率 在硬件显存允许的情况下,提高每批数量能够更好地利用 GPU 并行处理的能力,从而提升生成效率。相比之下,增加生成批次虽然也能生成更多图片,但总耗时会线性增加。
种子的分布
生成批次和每批数量的设置会影响生成图片的种子分布规律。
当生成批次为 N,每批数量为 1 时,初始种子为 S,生成的图片种子依次为 S, S+1, ..., S+N-1,每次生成独立运行。
当生成批次为 1,每批数量为 N 时,初始种子同样为 S,生成的种子也是 S, S+1, ..., S+N-1,但所有图片是在同一次生成中完成的。
在显存不紧张且需要快速生成多张略微不同的图片时,可以适当增加 Batch size。如果只是想多尝试几个种子,或者显存有限,增加 Batch count 是更稳妥的选择。通常保持默认的 Batch count=1, Batch size=1,除非有特定需求。
在 Olares 系统中使用 SD Web UI
模型上传与管理
在使用 Olares 系统运行 SD WebUI 时,需要注意将模型上传到文件管理器的对应位置。
外部设备
└── ai
└── model
├── main # 存放 .safetensors 或 .ckpt 大模型文件 (Checkpoint 大模型)
│ └── [建议在此创建子文件夹进行分类]
├── vae # 存放 VAE 模型文件
├── esrgan # 存放放大算法模型 (Upscalers)
│ └── [如 ESRGAN 类的 .pth 文件]
├── upscale_models # 可能的放大算法模型目录 (根据配置不同)
├── embeddings # 存放 Embeddings (.pt, .safetensors)
└── Lora # 存放 LoRA/LyCORIS (.safetensors)Olares 内置插件
Olares 平台内置的 Prompt All-in-One 插件可以大幅降低学习成本,通过中文选项自动生成英文提示词,支持翻译、提示词分类、ChatGPT 一键生成等功能。
其他使用技巧
如何挑选和下载模型?
如果是 Checkpoint 大模型、LoRA 等,首推 Civitai (C站),资源丰富,更新快。
如果是放大算法模型 (Upscalers),可以从 OpenModelDB、Upscale Wiki 等社区资源站寻找和下载。例如,在脚本中演示了从网上搜索并下载 4x-UltraSharp.pth,然后将其放入 Olares 对应的 upscale_models 目录,重启 WebUI 后即可在放大算法列表中选择使用。
如何在 SD Web UI 中快速恢复上次跑图配置?
在 SD WebUI 的“生成”按钮下方,通常会有一个蓝色的小图标(工具提示可能是“将上一次任务的参数复制到用户界面”)。点击它可以将最后一次成功生成图像时的所有参数设置(包括提示词、采样器、步数、种子、尺寸、Hires.fix 设置等)一键恢复到当前界面,非常方便在调整后不满意或重启 WebUI 后快速回到之前的状态。
如何自定义 SD WebUI 的顶部快捷选项?
在 SD WebUI 中选择 “设置 (Settings)” > 搜索“quicksettings” > 修改 Quicksettings list,可以把自己常用的参数(如 Clip Skip、VAE 选择、SD Hypernetwork等)添加到顶部快捷设置区域,提升操作效率。
📌 本期小结
本期我们系统梳理了 SD WebUI 文生图功能的核心参数与使用方法,包括:
主界面布局与功能模块划分
Checkpoint 模型的选择逻辑与下载建议
正负向提示词的写法、权重语法与顺序影响
采样器选择与步数调整的实用建议
种子与变异种子的作用与使用技巧
Clip Skip、高清修复等高级选项的使用场景
掌握这些内容后,你已经可以开始有目的地“指挥” Stable Diffusion 生成你想要的图像了。
下一期将讲解图生图功能,敬请期待!
关注我们的账号的系列文集「Olares 本地 AIGC 教程」,不要错过更新呦~
欢迎在评论区留言交流👇
你可以观看这个视频,详细了解 Olares。
https://www.bilibili.com/video/BV1VDCAYUEEm
📝 Olares 论坛已上线,欢迎在这里分享和讨论:
https://forum.olares.cn/
