
欢迎加入和体验 张敬信『tidy-R语言』知识库,可以说是全网最新、最优秀、最丰富的 tidyverse R 语言学习资料和案例库,支持 DeepSeek R1知识库问答+免费下载文档。

用最 tidy 的方式学习 R语言编程,掌握整洁优雅的数据编程思维:
知识库文档目录:
1. R书完整课件:1393页-R语言编程:基于tidyverse(带书签).pdf
2. R书第二版:整洁计算_新.pdf
3. R书第二版:purrr泛函式循环迭代.pdf
4. R书第二版:Quarto.pdf
5. R书第二版:数据库&大数据.pdf
6. R实验一:数据结构之向量矩阵列表.pdf
7. R实验二:数据结构之数据框因子.pdf
8. R实验三:分支循环自定义函数.pdf
9. R实验四:泛函式循环迭代.pdf
10. R实验五:数据读写.pdf
11. R实验六:数据操作I.pdf
12. R实验七:数据操作II.pdf
13. 初级-玩转数据120 题:tidyverse 版(2024).pdf
14. 中级-SQL 经典50 题:tidyverse 版(2024).pdf
15. 高级-Tidyverse 进阶修炼:金融数据操作70 题(更正版).pdf
16. 【狗熊会】Tidyverse 优雅编程:从向量化、泛函式到数据思维(加量版).pdf
17. 【狗熊会】R 语言编程:基于tidyverse—教学探讨.pdf
18. 【和鲸网】:快速掌握数据编程思维.pdf
19. Tidyverse优雅编程系列:数据编程思维.pdf
20. Tidyverse优雅编程系列:数据处理.pdf
21. Tidyverse优雅编程系列:概率统计.pdf
22. Tidyverse优雅编程系列:算法模型.pdf
23. Tidyverse优雅编程系列:批量建模.pdf
24. Tidyverse优雅编程系列:爬虫.pdf
25. Tidyverse优雅编程系列:数据可视化.pdf
26. 张敬信-R语言问题知乎回答(2022-2024).pdf
27. 张敬信-Python问题知乎回答(2022-2024).pdf
28. 张敬信-Excel问题知乎回答(2022-2024).pdf
29. Hadley:R for Data Science (2e).pdf
30. Hadley:Advanced R (2e).pdf
以下是 DeepSeek R1 对本知识库的内容和特色总结。
一、知识库核心内容总结
1. R语言与Tidyverse的核心地位
数据处理与分析:知识库重点围绕R语言的tidyverse生态系统,涵盖数据清洗、重塑、连接、分组计算等经典操作。工具包:dplyr(数据操作)、tidyr(数据整理)、ggplot2(可视化)、purrr(泛函式循环迭代)等。特色功能:管道操作(%>%)、向量化计算、数据思维编程模式。统计分析:覆盖概率统计模拟(如卡方分布、中心极限定理)、模型构建(回归树、机器学习)、参数评估(BIC值分析、嵌套重抽样)等。高级应用:跨领域实战案例,如金融数据操作(滚动回归、Bootstrap残差法)、网页爬虫(提取天气数据)、自动化处理(批量Excel文件操作)等。
2. 多领域多场景实战
数据处理:包括Excel复杂任务(数据透视、拆分宽表)、Python+R混合编程(数据整合)、数据库与大数据(DuckDB、SQL查询)等。科研与工程:校准曲线绘制、泰尔指数分解、蒙特卡洛模拟(计算Pi、股票价格预测)、医疗数据分析(物种丰度统计、年龄标准化率)等。可视化:基于ggplot2的人口金字塔图、批量图表导出、堆积柱状图设计等。
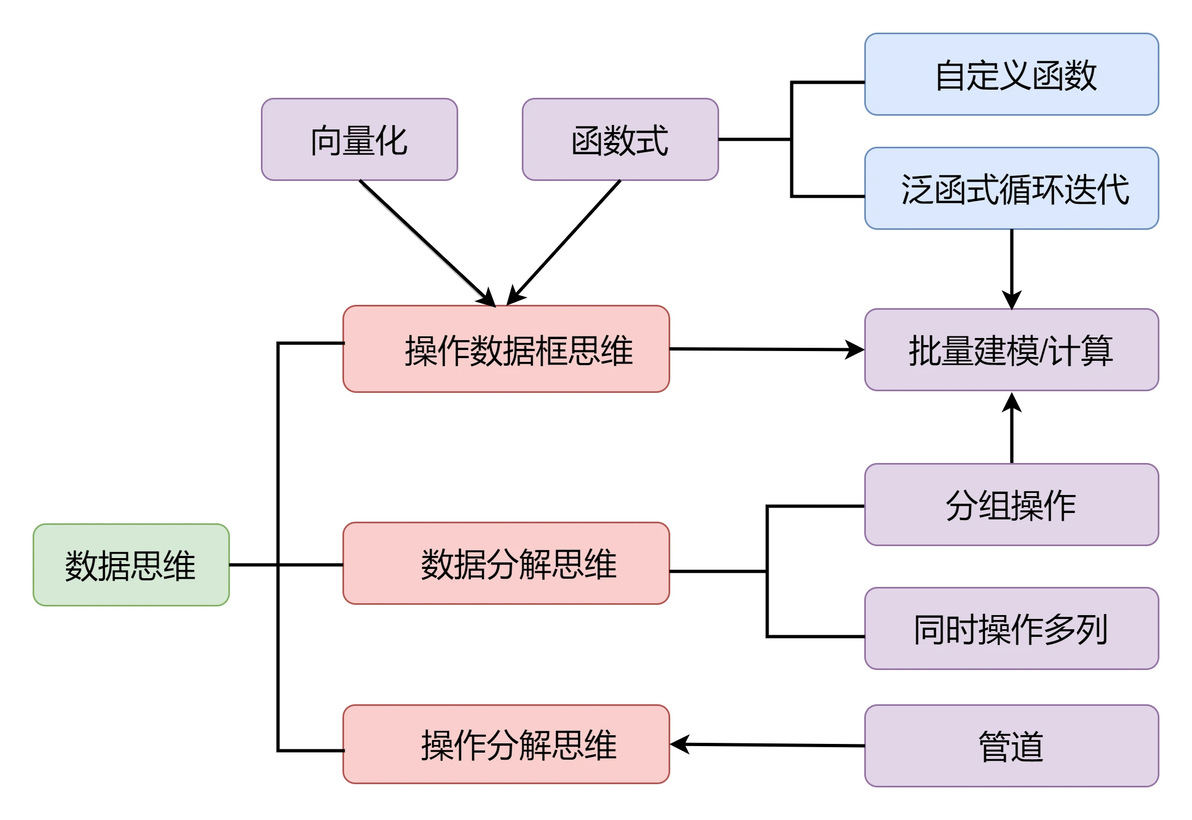
3. 编程思维与方法论
优雅编程:强调通过管道操作、泛函式编程(map系列函数)、向量化计算简化逻辑,提升代码可读性。批量操作:数据分组建模(分组t检验、滚动回归)、复杂抽样(随机重复抽样、残差Bootstrap)等。数据驱动思维:分解问题迭代解决(如绘制复杂图表前分步处理数据)。
4. 学习路径与资源整合
系统性教程:从基础(向量、数据框)到高阶(元编程、数据库操作)的实验设计,涵盖《R实验一》到《R实验七》。经典书籍支持:参考Hadley Wickham的《R for Data Science》《Advanced R》,并结合《R书第二版》系统学习整洁计算、Quarto文档生成等。实战题库:120题入门训练、50题SQL转换练习、70题金融数据操作挑战,覆盖各阶段技能需求。
二、特色亮点总结
1. Tidyverse生态为核心
优雅高效:通过管道(%>%)串联函数,避免中间变量,提升代码简洁性(如df %>% filter() %>% group_by() %>% summarise())。泛函式编程:purrr包的map函数替代传统循环,实现类型安全、一致性操作。数据思维:强调从数据框(tibble)角度设计逻辑,简化复杂问题(如批量建模、分位数计算)。
2. 全栈技能覆盖
跨工具整合:R语言与Python、Excel、SQL的混合使用(如用R处理Excel复杂逻辑,用pandas对比学习)。全流程实战:从数据读写(处理中文乱码、读写Excel/SAS文件)到建模、可视化(Quarto生成可重复报告)的完整流程。
3. 强实践导向
案例驱动:提供金融、医疗、天气数据等领域的真实案例,如:
批量建模分析股票波动率。从网页爬取天气数据并导出Excel。使用插补法处理医疗数据缺失值。交互式学习:120题入门练习、70题高级训练,提供代码示例与解题思路,适合自学与教学。
4. 理论与应用深度结合
底层原理:深入解析R语言数据结构(向量、因子、列表)、函数闭包、元编程(tidy eval)。统计学实践:基尼系数计算、秩和比法综合评价等,直接衔接实际科研需求。
5. 教学与社区资源整合
教学课件:1393页的《R书完整课件》系统化展示R语言编程全貌。社区推荐:知乎回答、狗熊会文章提供行业洞见与资源指引,助力持续学习。
总结
本知识库以R语言+tidyverse为核心,系统覆盖数据科学全流程(清洗→分析→可视化→沟通),强调优雅编程、高效实践,适合从入门到高阶的开发者。其独特价值在于将复杂统计理论转化为可操作的代码案例,并结合多领域真实场景,帮助用户掌握“从问题到代码”的完整闭环能力。
