
何恺明大佬这几天又整了个大的,和LeCun联手提出了一种没有归一化层的Transformer,性能比传统Transformer更强!而且他们甚至只用了9行代码...大家感兴趣可以复现了试试。
这波属实是Transformer的大突破!目前也已拿下CVPR 2025。加上前不久清华微软的爆火成果Diff Transformer,近期关于Transformer的改进又迎来了新热潮!大家没idea的快冲!
改进Transformer方法思路很多的,关键在于结合具体问题提出创新。比如针对计算复杂度问题,研究线性注意力或混合架构;针对视觉任务,研究分块策略优化或位置编码...而根据现状,跨模态融合、轻量化设计、动态机制等是未来热点,相关成果在顶会中接受度也比较高,推荐关注。
我这回整理了12种Transformer最新改进思路,基本都有代码,需要参考的同学可无偿获取~
扫码添加小享,回复“T创新”
免费获取全部论文+开源代码

Transformers without Normalization
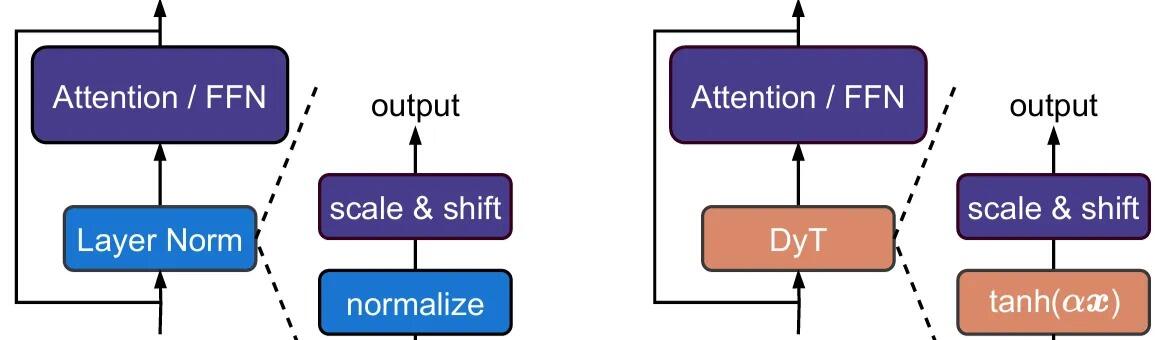
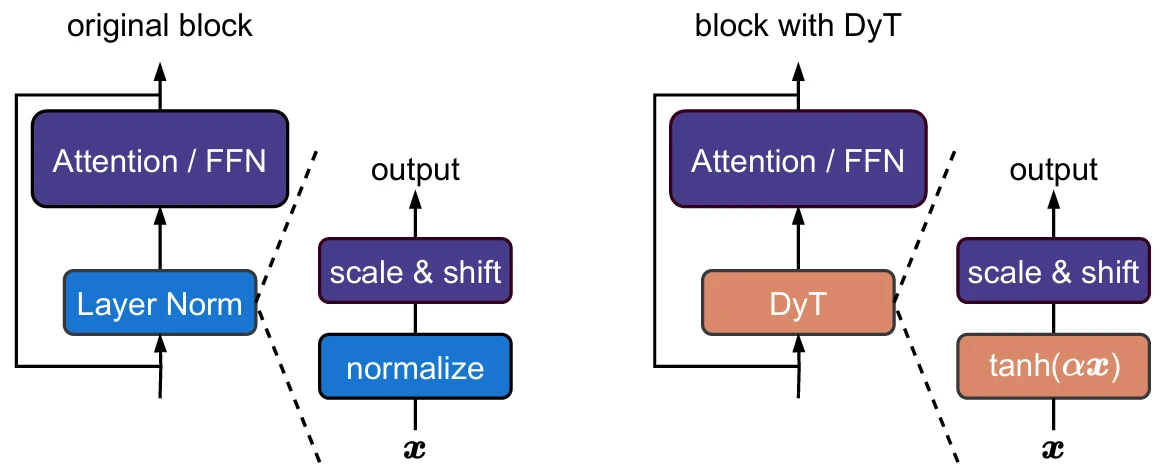
方法:论文提出了一种名为Dynamic Tanh(DyT)的方法,通过用简单的tanh函数替换Transformer中的归一化层,显著提升了Transformer的性能和效率,同时证明了在现代神经网络中无需归一化层也能实现稳定训练。
创新点:
DyT(Dynamic Tanh)模型通过一个可学习的缩放因子α和一个S形tanh函数来替代传统的归一化层。
初始化α的值对模型性能有显著影响。在注意力模块中使用较高的α初始值,而在其他位置(如FFN模块或最终线性投影之前)使用较低的α初始值,可以提高模型性能。
Differential transformer
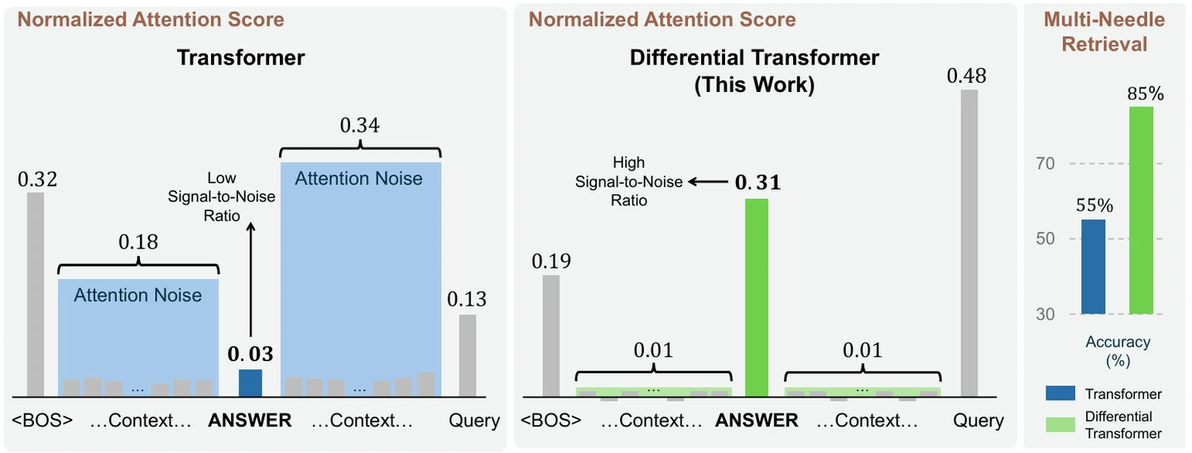
方法:论文提出了一种改进的Transformer架构——DIFF Transformer,通过计算两个softmax注意力图的差值来消除注意力噪声,增强对关键信息的关注,从而提升模型在语言建模、长文本处理和幻觉缓解等任务中的性能。
创新点:
差分Transformer引入了一种新的差分注意力机制,通过计算两个独立的softmax注意力图之间的差异来消除注意力噪声。
DIFF Transformer在处理长上下文时表现出色,并且在上下文长度增加时能够维持稳定的性能。
DIFF Transformer在注意力logits的量化中表现优异,即使在减少比特宽度的情况下也能保持高性能。

扫码添加小享,回复“T创新”
免费获取全部论文+开源代码

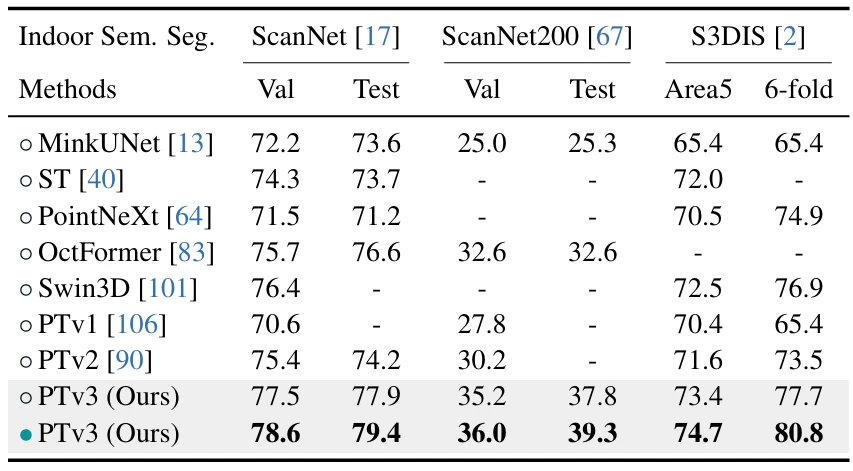
Point transformer v3: Simpler faster stronger
方法:论文提出Point Transformer V3,通过改进Transformer架构,采用点云序列化和高效的Patch Attention机制,避免了KNN查询和复杂的位置编码,显著提升了模型的效率和可扩展性,同时在多种3D任务中实现了更高的性能和更低的内存消耗。

创新点:
引入了新机制(补丁注意力),通过将点分组为不重叠的补丁并在每个补丁内执行注意力操作,提高3D空间中注意力机制的感受野。
提出了增强型条件位置编码(xCPE),替代传统的相对位置编码(RPE),通过八叉树卷积和稀疏卷积层实现,提高计算效率。
通过将无序的点云数据序列化为结构化格式,突破了排列不变性的限制,利用了结构化数据的效率优势。
Kolmogorov-arnold transformer
方法:论文提出了一种改进Transformer的方法,用KAN替换传统的MLP模块。通过有理函数、分组参数共享和方差保持初始化等改进,KAT在计算效率和性能上显著优于传统Transformer,适用于多种视觉任务。
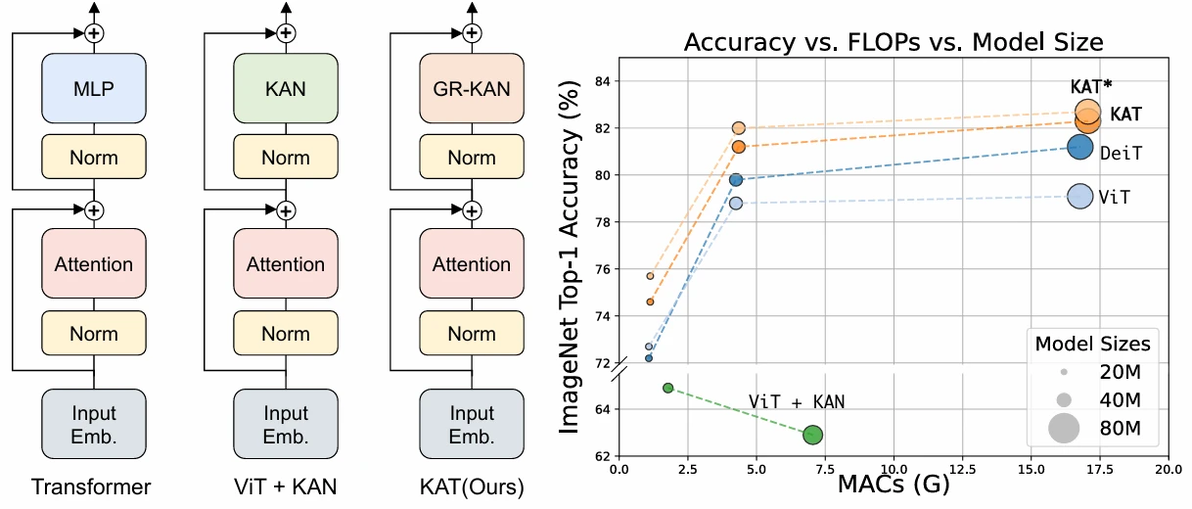
创新点:
提出GR-KAN,用有理函数替代B-spline函数并结合CUDA实现,提升计算效率和并行性。
引入分组共享机制,减少参数数量和计算负担,同时保持性能,解决KAN扩展性问题。
提出方差保持初始化方法,确保训练稳定性,解决KAN收敛难题。
扫码添加小享,回复“T创新”
免费获取全部论文+开源代码

