目录

YOLOv5 输出解析:从模型输出到检测结果

收录于文集
共12篇
YOLOv5 输出解析:从模型输出到检测结果
YOLOv5 是目标检测领域的热门模型,但它的输出是一个复杂的张量结构,如何从中提取出我们需要的检测框、类别和置信度呢?今天我们就来详细聊聊 YOLOv5 输出的解析方法,手把手教你从模型输出到最终检测结果的全过程!
1. YOLOv5 的输出格式
YOLOv5 模型的输出是一个 PyTorch 张量,其形状为 ,其中:
batch_size:批处理大小。
num_anchors:每个网格单元的锚框数量。
grid_h 和 grid_w:特征图的高度和宽度。
num_classes + 5:每个锚框的输出维度,包括:
4 个值:检测框的坐标 (x, y, w, h)。
1 个值:置信度分数(表示框内是否有目标)。
num_classes 个值:每个类别的概率。
2. 解析 YOLOv5 输出的步骤
以下是解析 YOLOv5 输出的具体步骤:
Step 1:获取模型输出
YOLOv5 模型的输出是一个列表,包含多个尺度的特征图(用于处理不同大小的目标)。通常,我们只需要处理其中一个尺度的输出。

Step 2:提取检测框信息
从输出中提取检测框的坐标、置信度和类别概率。

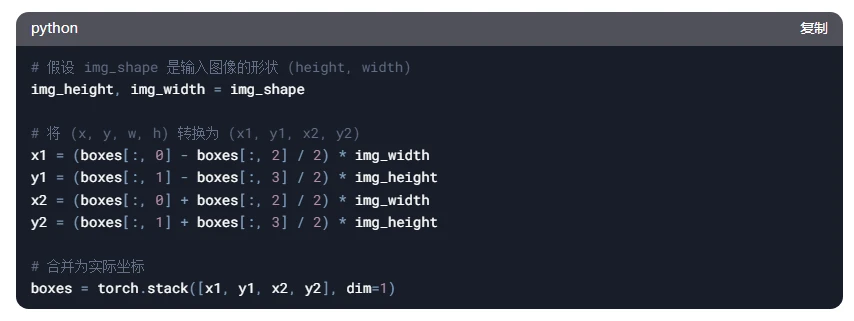
Step 3:将检测框坐标转换为实际坐标
YOLOv5 输出的检测框坐标是相对于特征图的归一化值,需要将其转换为实际图像坐标。
Step 4:过滤低置信度的检测框
通过置信度阈值过滤掉低置信度的检测框。

Step 5:获取类别标签
从类别概率中获取每个检测框的类别标签。

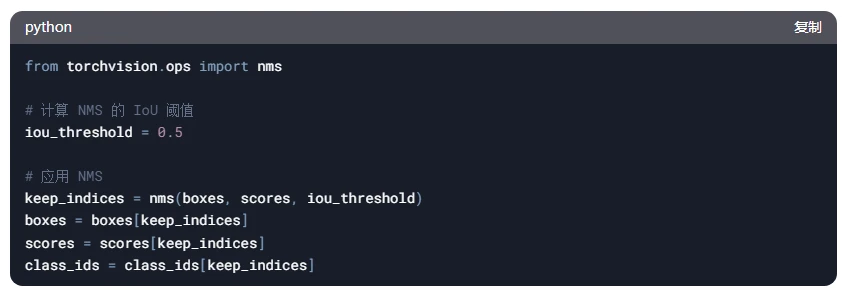
Step 6:应用 NMS(非极大值抑制)
使用 NMS 去除冗余的检测框。
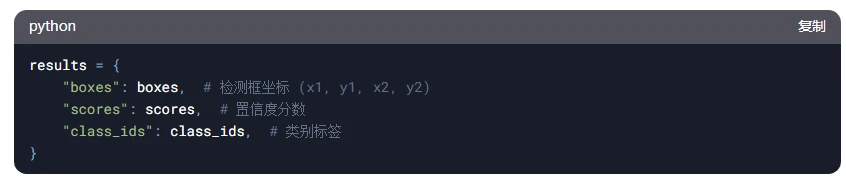
Step 7:输出最终结果
将解析后的检测框、置信度和类别标签输出。
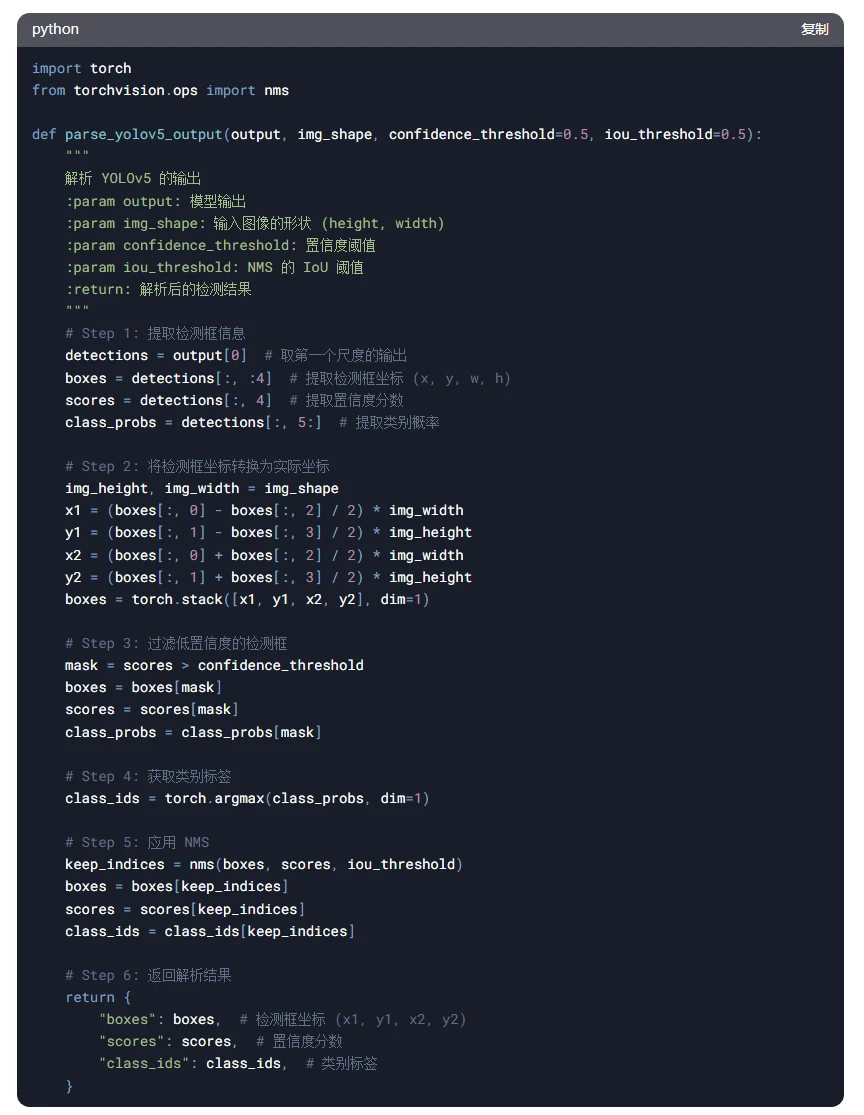
3. 完整代码示例
以下是解析 YOLOv5 输出的完整代码示例:
4. 总结
解析 YOLOv5 的输出主要包括以下步骤:
提取检测框坐标、置信度和类别概率。
将检测框坐标转换为实际图像坐标。
过滤低置信度的检测框。
应用 NMS 去除冗余框。
输出最终的检测结果。
通过以上步骤,你可以轻松解析 YOLOv5 的输出并用于实际应用!如果有其他问题,欢迎在评论区留言!别忘了点赞、收藏、关注哦!😊
希望这篇专栏对你有帮助!如果有其他问题,随时告诉我~
cv40756973
分享至
投诉或建议
