

逼逼扯扯
我不太爱读文章。更不爱读论文。一半的原因是我喜欢直接上手操作,以及我一看文章就容易走神,即便是我很喜欢的深度学习相关的内容。我也不喜欢看。甚至我连我自己的文章都懒得看。
另一半的原因是我被很多文章骗了好几次。有些作者不知道从哪里看来的稀奇古怪的模型推理技巧、妖门邪术的训练“巧思”,和莫名其妙的参数搭配。我一次次的模仿操作,结果一次又一次失败碰壁,要不就是没效果,要不就是模型反而更差了。十分让人无语。所以我也就更不喜欢看文章了。
当然,尝试的过程,有失败,当然也会有成功。如果要挑选一个帮助最大的,那么就是接下来DeepSeek R1技术论文中反复提到的模型蒸馏(Distil)了。
花了一晚上的时间,好好地读完了这篇论文。没有一刻的放松。读到精彩的部分感慨万分,十分认可。这里我就提取其中几个我认为有趣且值得尝试的内容。同时会对论文中作者写到的段落,大胆的揣测作者的想法、吐槽娱乐下。由于想要说的内容太多。一口气写完实在太累人了,所以我就分为了上、下两篇。这篇主要讲一讲我比较关注的一些内容。
整体概况
闲言少叙,接下来我会使用中文翻译后的技术论文进行讲解,方便我自己阅读,也方便你观看理解。这篇文章可能会出现很多的未证实内容。所以需要你自行分辨。
R1的整篇论文概况一下就是:此团队想让AI能更好地思考和推理。基于基础(base)模型。使用了独创的"grpo"纯强化学习(RL)方法,得到巨大性能提升的R1 zero。以及同样基于(base)模型多阶段训练出了R1模型,能力更进一步。不仅大幅降低了训练成本,同时还大大提升模型性能。训练后的模型在数学和编程等需要深度推理的任务上达到了与OpenAI顶级模型相当的水平。
研究中另一个发现是通过数据蒸馏技术。在R0.5模型(这个R0.5模型是什么之后就会知道)提取出60万条数据,以及训练deepseek v3的时候的数据等,共整合出80万条数据。
这80万的数据用来训练更小的模型,训练后的模型比同等规模的模型能力要强上许多,甚至出现了小参数模型比大参数模型更强的现象。证明了依靠高质量的模型蒸馏数据,用来微调小模型。可以得到出乎意料的好效果。
DeepSeek团队这次一共开源了两个“真”深度思考模型:
DeepSeek R1
DeepSeek-R1-Zero
以及基于 DeepSeek-R1 蒸馏出的六个模型:
DeepSeek-R1-Distill-Qwen-1.5B
DeepSeek-R1-Distill-Qwen-7B
DeepSeek-R1-Distill-Llama-8B
DeepSeek-R1-Distill-Qwen-14B
DeepSeek-R1-Distill-Qwen-32B
DeepSeek-R1-Distill-Llama-70B
用于蒸馏训练的模型是下述红框内模型:

模型训练
R1 zero训练流程
Deepseek一共训练了两个深度思考模型,一个是R1 另一个是R1 zero
训练的第一个深度思考模型:DeepSeek-R1-Zero
训练方法:
DeepSeek-V3-Base模型 →强化学习(GRPO )算法训练
说的再明白一些就是:
base(基础模型) →纯强化学习训练

这就是训练过程。看上去好像很简单,但是里面的细节有很多。
这边讲下传统强化学习普遍流程。首先,需要准备一个大语言模型,也就是LLM。同时,还得是经过SFT训练后的语言模型。例如:qwen2.5-7b-instruct、glm4-gb-chat这些,就是经过了SFT监督微调的模型,掌握了对话的能力,能输出自然有逻辑的语言。没有经过SFT后的模型,我们统称为基础(base)模型。
一般公司开源模型都会附带base模型和sft后的模型。例如:
qwen2.5-7B (base模型)
qwen2.5-7B-instruct (基于base模型SFT训练后的模型)
接着,还需要准备一个奖励模型(Reward Model)。此模型制作过程是:利用给定的输入数据,针对这些数据集给出我们人类评定的好、坏标注。例如:
输入:请用热情的语气向我问好。
A:哈喽,你好呀!今天过得怎么样?开不开心呀~
B:咋样啊你?
评价:A 好 B 坏
使用这些由我们人类标注好的数据用于训练奖励模型。使模型可判断哪些回复是好的,哪些回复是不好的。
奖励模型实际上也可以是大语言模型(LLM)也就是可以是我们熟悉的预训练模型。如之前说的qwen2.5-7B-instruct、glm4-gb-chat这些。
但是,也不完全一样。我们会在训练奖励模型的时候,利用模型参数冻结(freeze)不参与训练的部分。去专门训练模型的输出部分。因为我们不打算改变模型的全部参数,而是去改变模型的最为关键的参数。所以这种方式既高效又能降低成本。
具体来说就是在模型的隐藏状态上添加一个简单的评分头,训练时只更新这个新增的评分头。
为什么训练过程这么简单呢?因为我们的任务相对于而言很轻松,只是让模型来评判输出的内容好坏。举个例子,想象你在培养两种不同的人才。一种是要培养一个能写出高分作文的学生,而另一种是培养一个阅卷老师,这个老师只需要学会分辨作文的好坏。所以不需要很复杂的训练。
在经过上述的准备工作后,我们已经有了一个SFT预训练模型,和一个训练好了的奖励模型。
接下来,就可以开始正式的强化学习训练了。
一般来说,当前用得最普遍的是PPO算法。通过限制新策略与旧策略的差异,通过概率比的裁剪实现,来实现稳定且高效的策略优化
PPO算法要细说实在有些复杂,简单来说,就是算法内有:
策略模型(Policy Model)
参考模型(Reference Model)
奖励模型(Reward Model)
价值模型(Value Model)
其中里面的策略模型就是我们被用于训练的LLM。这个参考模型实际上就是计算KL散度的冻结参数副本,可以简单理解为初期的LLM复制体。也就是复制了一份模型克隆体。在整个PPO训练过程中保持不变。奖励模型就是我们之前说的在PPO算法前训练好的模型。最后的价值模型则和别的不同,是在训练中产生的。通过学习预测每个状态下的累积折扣奖励。
PPO算法,利用奖励模型给的分数,更新SFT模型的同时,为了防止模型一次里更新幅度太大。还会设置一个"区间",限制每次更新的幅度。也就是参考模型会干的事情,通过KL散度约束确保输出不会偏离太远。以防止模型过度采样学习。举个例子:
输入:你说的东西我根本听不懂!
A:对不起,这是我的失误,我应该详细向您解释。
B:是哪里没有听懂呢?我不理解。
C:无语。
奖励模型打分:
A:7分
B:2分
C:1分
这个时候算法发现A回答的分数很高。就直接给A回答给了很大的权重奖励用于更新模型。模型突然得到高分会判断,这次怎么给的奖励这么多?难道这种回答很好吗?学到了!多说对不起就能得高分
从而倾向于大量使用这样的回复风格,因为这样可以得到更明显的权重奖励。从而倾向于道歉
比如在同样的场景下,模型可能会突然从"是哪里没听懂呢..."变成只会"对不起对不起对不起..."
所以为了不出现这种情况,会设置一个区间,比如[0.8, 1.2]这个区间。更新的幅度不会高于或者低于这个区间。也有人叫它裁剪范围(clip range)
这样做可以防止一次更新的浮动太大。优点是不会出现特别激烈的学习,比较稳定。缺点是每次更新训练幅度太小。速度慢。
最后不断的循环这个更新训练的过程。这就是比较常见的PPO的强化学习流程。
下面,我们回到DeepSeek 的强化学习流程。
首先,他们这里尝试的是直接在基础(base)模型上直接进行纯强化学习训练,也是我认为的最大的创新点。使用的算法是基于传统的PPO算法改进的算法。此算法不是这篇论文提出来的,而是deepseek团队在24年4月提出来的。论文标题是:
《DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models》
感兴趣的可以去搜一下看看。
GRPO算法和PPO算法有什么不同呢?最大的不同就是GRPO直接放弃了:
价值模型(Value Model)
GRPO算法让模型生成多个回答,并对这些回答进行"相对比较",替代传统 PPO 中的"价值模型"的训练策略。具体而言,就是对同一问题采样多个输出,计算这些输出的奖励值,然后基于奖励的相对大小来更新模型参数。这样就不需要价值模型的介入,从而降低了计算开销。

此外,为了更好的训练r1zero 。团队内还设计了一个基于规则的奖励系统。主要由两种类型的奖励构成。一个是基于准确性的奖励。一个是基于格式的奖励。
准确性奖励很好理解,就是答案是否正确。例如有固定答案的数学类任务、编程类任务。
格式性奖励则是让模型把其思考过程置于“<think>”和“</think>”标签之间。下面的这个就是给模型用的数据格式。
所以,模型回复的格式遵循下面这种格式:
<think>思考过程....</think><answer>模型回复....</answer>

R1 训练流程
接下来目前流传的最广,也是当前开源模型效果最好的:
DeepSeek R1 模型
相较于R1 zero的训练流程,R1模型的训练流程则更为复杂,一共有四个阶段。说实话我自己看论文反反复复看了好几遍才看懂。
我做了一张简单的训练的流程图,大家可以看一下:
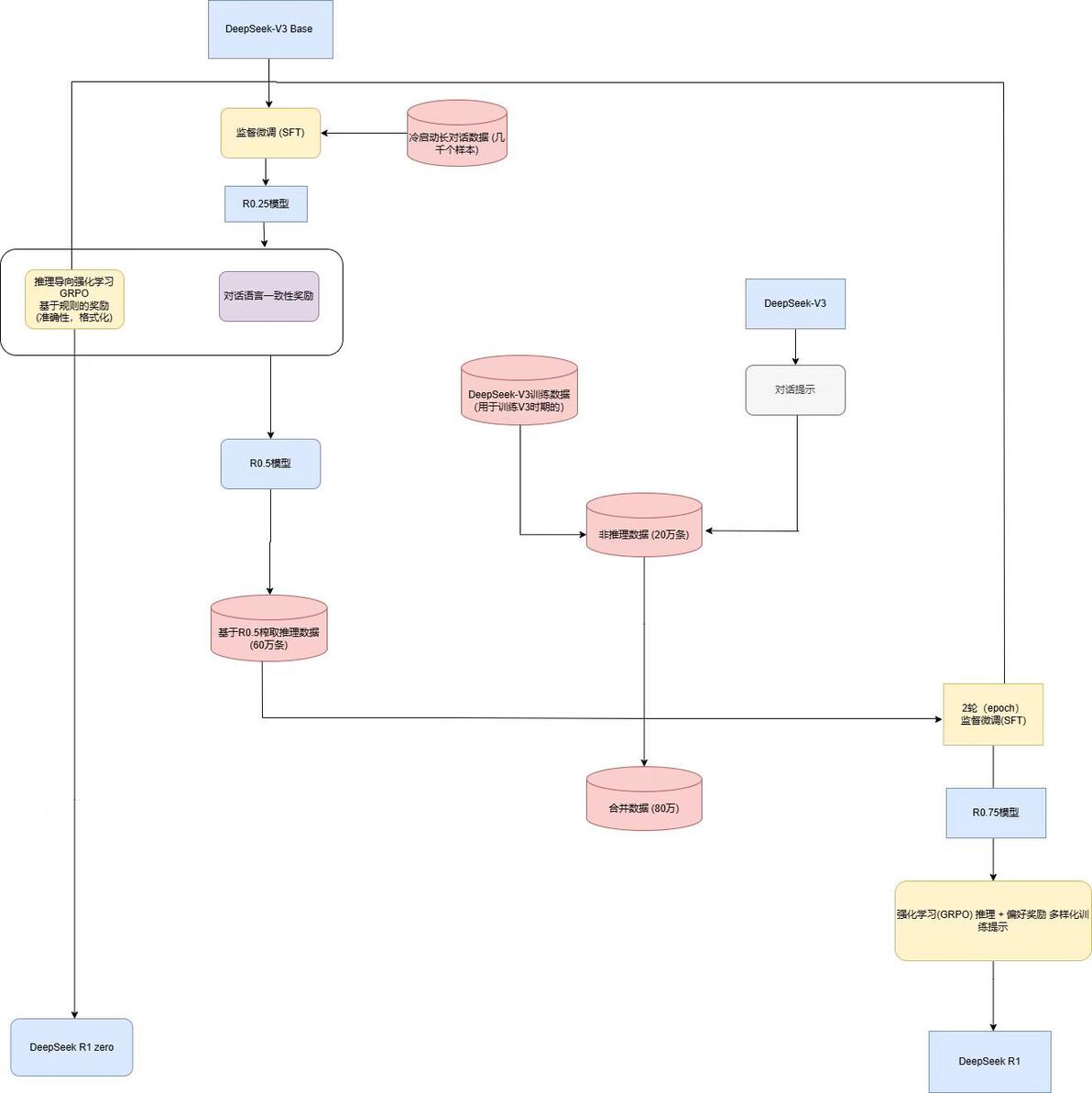
其中,R0.25~R0.75这些都是为了方便理解给不同阶段的模型取的名字。
第一阶段
这次一样是基于DeepSeek v3 base 模型上面做训练的。只不过不是和R1 zero 一样,一开始就直接强化学习训练。而是在开始前,先准备了数千条的高质量cot(思维链)数据。原因就是为了防止初期RL强化学习不稳定。以及因为R1 zero存在可读性差的问题,所以精心构建这些cot数据,给模型打一个基础。
这就是第一阶段,也叫做“冷启动训练”。训练的方式则是监督(SFT)微调

第二阶段
这一阶段是使用了和R1 zero刚开始同样的(GRPO)强化学习算法训练。但是发现训练中,模型出现了语言混合现象,也就是中、英等语言混合输出这种现象。所以,为了缓解消除这种情况。在这一次的强化学习中,引入了语言一致性奖励。使模型语言尽可能的统一。虽然这样做会损失一些性能,但是这更符合人类的阅读习惯。增加了可读性。
确定了之后,即将语言一致性和任务准确性直接相加,开启GRPO训练,直到模型收敛。

第三阶段
在第二阶段之后,模型已经训练到收敛了,但是这还不是真正的R1模型。我这里暂且称为R0.5模型。这个模型实际上已经有了基本的推理能力了。 但是还远远不够,这只不过是一个“工具人模型”。我们可怜的R0.5模型是用来被榨取cot(思维链)数据的。
具体来说,第三阶段做了两件事。
首先是第一件,就是对R0.5模型进行“拒绝采样”数据收集。收集了约60万条的cot(思维链)数据。
第二件,就是复用了用于训练DeepSeek-V3 的SFT数据集。以及其他等方式收集了约20万条非推理数据。
先说第一件事,通过对R0.5模型榨取了60万条的cot数据。这里用了“拒绝采样”这个词。这个的意思就是让模型生成多个候选回复,根据质量标准筛选出最佳答案,把不行的回答“拒绝”掉!保留合适的回答。
举个例子:
问:马云是谁?
回复1:马云就是那个说"996是福报"被全国打工人记恨的人。❌
回复1:马云就是那个长得像外星人的富豪。❌
回复3:马云是从杭州走出来的互联网大佬。❌
回复4:马云是中国著名的企业家,阿里巴巴集团的联合创始人。他于1964年出生在杭州..... ✔
上述的只有回复4是最合适的。其余的三个则被“拒绝”
这里只是举例,上述的例子只是单纯的问答对。
但是逻辑是一样的,第一件事就是利用提示词,让R0.5输出了非常多的数据,再通过拒绝采样等方法挑选出合适的数据。同时将语言混杂、长段落以及代码块形式的 CoT 过滤掉,最终挑选出了60万条的cot数据。
第二件是就是收集那些非cot数据的数据。也就是无需依赖思维链的场景。例如简单的“你好”。以及写作、事实问答、自我认知和翻译,这种场景下,不需要模型参与什么推理。
同时,把以前训练DeepSeek v3的数据拿来了一些。以及利用一些别的方式收集整合,最后搞了大约20万条的非推理数据。
60万加上20万,也就是80万的数据。直接对Deepseek v3 base 进行了2轮(epoch)的SFT微调。
对,你没有看错,我写的是“Deepseek v3 base” 。是重新拿了一个新的Deepseek v3 base模型,然后用从R0.5身上榨出的60万条数据和另外的20万条训练训练一个新的Deepseek v3 base
这里要搞清楚!我看见很多文章和一些视频作者都没有分清楚,或者说搞糊涂了,以为所有的训练都在一个模型上面。实际上经过1、2两个阶段的训练得到了R0.5模型。而这个模型只是用来获取数据用的。第三阶段和第四阶段的训练不会再它身上进行!
第四阶段
到了最后的一个阶段了,在上一个阶段里。通过榨取R0.5模型得到了60万的cot数据,以及另外从V3模型那里拿了当初用来训练它的数据,和杂七杂八别的数据,凑出来20万条。一共80万条。接着重新拿了一个崭新的Deepseek v3 base 模型,用这收集来的80万条数据对它进行监督(SFT)微调。
这就是上一阶段的做的事情。是的我又讲了一遍。总之。在这一阶段。我们得到了一个经过80万条数据SFT后的模型。然后接下来需要对它进行最后的强化学习。用的还是GRPO这个算法。
这一步的强化学习主要是为了对齐模型。同时让模型有更好的综合能力,以及符合人类偏好。
具体来说,这一次的GRPO还是保留了Deepseek r1 zero的规则性奖励。然后对于一般数据,可能指的就是普通的SFT数据。用了一个奖励模型来捕捉“微妙场景”的偏好。
以及最后说的各种的奖励模型和评估控制,在这最后的一次训练中控制模型的最终形态,最终得到了R1模型。

闲聊:
在第四阶段里,文章用了好几个“性”。之前虽然也用过,但是这里尤为的频繁。以及虽然开头写了具体来说。这四个字。但是并没有特别的具体,所以这一阶段确实没有很好的理解。相对于前几个阶段,个人感觉有些比较难理解,有些匆匆结尾的感觉。
我大胆猜测一下,deepseek R1的安全对齐实际上没有做好,或者说故意不去做好。因为很早就有实验证明过了,道德或者安全对齐,强迫让模型拒绝回答知道的内容。会使模型的能力下降。损失质量。
平时我在实验中也会发现,模型道德、安全等对齐后明显感觉到能力有所下降。所以我也不喜欢对模型做这些方面的对齐。我看到这里的第一想法是想故意减轻这个阶段的侧重描写。
实际上也能看出来deepseek r1在安全对齐方面没有过度的控制。只需要在各大视频网站,就能搜到很多的R1视频,加上关键词“贴吧”、“骂人”都可以搜到大量的“AI嘴臭” 视频。别的LLM模型,如豆包、KIMI、千问等模型都做了挺严格的安全对齐。至少很难让他们骂人。这其实不是它们不会,而是故意限制了。
不过,我个人认为只需要对齐一些敏感内容、暴力等你懂的内容。剩下的反而不需要关心。
因为这样模型至少不是无趣的输出:“对不起,我不能随意评价谁谁谁......”这种内容。而是真正类似真人的感觉。只是不知道后续会不会要求内容审核。
这里我就小小的吐槽调侃一下。当一个过渡的小插曲~
结尾
这就是全部的R1模型训练过程了。后续的就是讲关于蒸馏的一些内容了。这一块也是我很感兴趣的一块。在阅读的时候产生了很多想法和共鸣。以及文章中有一些值得非常值得一试的实验。同时我也通过官方放出来的蒸馏后的模型得分表看见了几个有趣的对比。我不知道有没有人看出来了一个奇怪的地方,但是确实是一个新的切入点。
这些留给之后的Deepseek R1(下) 吧。这一次的文章真的花了我好几天。修修改改。不断地检查哪里有没有说错。所以消耗了很多的精力。但是不分享出来又不舒服。可恶的完美主义。这篇文章用到的各种术语有些多了,对于新手而言可能会看的比较吃力。我自己回头看也感觉很复杂。
总之,感谢你看到了结尾。对于这篇论文我真的推荐自己去看看,如果你有模型训练的基础。是能够看懂这里面大部分内容的。写的十分有趣。值得反复阅读。
