
使用 lm studio + SillyTavern, 网盘链接在文章结尾
一、基础知识(可先跳过 ,安装完环境再看)
1 模型量化
大模型原版是无压缩量化的, 对显存要求极高, 因此有了量化, 主要是通过对模型参数进行压缩和量化,从而降低模型的存储和计算复杂度.
2 量化格式(重要)
不同量化效果不同, 运行环境也不同
1 gguf格式:
个人电脑最常用的格式, 使用cpu, 内存, 显卡, 显存联合推理大模型, 彻底榨干电脑
简单来说, 是手动选择一个值(载入显卡层数), 比如说20, 就意味着模型有20层放到显卡里运行, 这20层是显卡+显存推理 速度很快.
而其余层则是cpu+内存推理, 由于内存速度远低于显存, 因此内存会造成速度瓶颈,
这也导致了gguf格式在显存太少时, 速度很慢, 但只要内存足够, 终究是可以运行的
2 awq, exl2, gptq...
这些都是纯用显存推理的, 如果你有大显存显卡, 比如几万到几十万的专业卡且显存超过40g, 或者只想高速跑很小的模型(多用于翻译任务), 可以考虑这几种. 总之, 不推荐!
3 模型参数(重要)
简单粗暴的来说, 参数可以看作模型的知识量, 但存在边际效应
常见参数量(b表示十亿)
12b, 14b, 32b, 70b, 120b...
参数越大, 模型的文件就越大, 显存需求就越高.
对应到角色扮演上
低于32b的模型, 往往是文笔不错, 但逻辑能力差, 相当于小学生背作文模型, 题目对的上就写的好, 超出知识量就写的差. 不适合推演, 分析类的, 只能单纯写作.
32b-40b这个区间就有一定质的变化
知识量足够庞大, 推理能力还可以, 足以凭借之前的剧情, 人物设定, 用户的简单输入, 来自动推进剧情.
其中一些出色的模型, 逻辑上能堪比70b模型.
不过参数终究是有限的, 体验上并不能做到完美
70b级别的可以说, 有质的变化了
逻辑能力接近在线大模型, 文笔不差
是较为完美的角色扮演(sese)大模型了, 缺点是对显存需求有亿点点高
至于120b及以上, 那不是一般人可以窥探的.
一般在线模型是120-300b, 甚至是405b, 不过有边际效应, 在角色扮演这一领域, 很多在线模型反而不如70b的本地模型.
4 gguf的量化级别(非常重要)
原理不用管了, 反正我也不会.
简单来说, gguf有q1, q2...q4, ..q8, 还有iq1, iq4之类的级别
区别是质量和性能
q开头的, 性价比高的是 q4, q5
iq则是 iq3, iq4
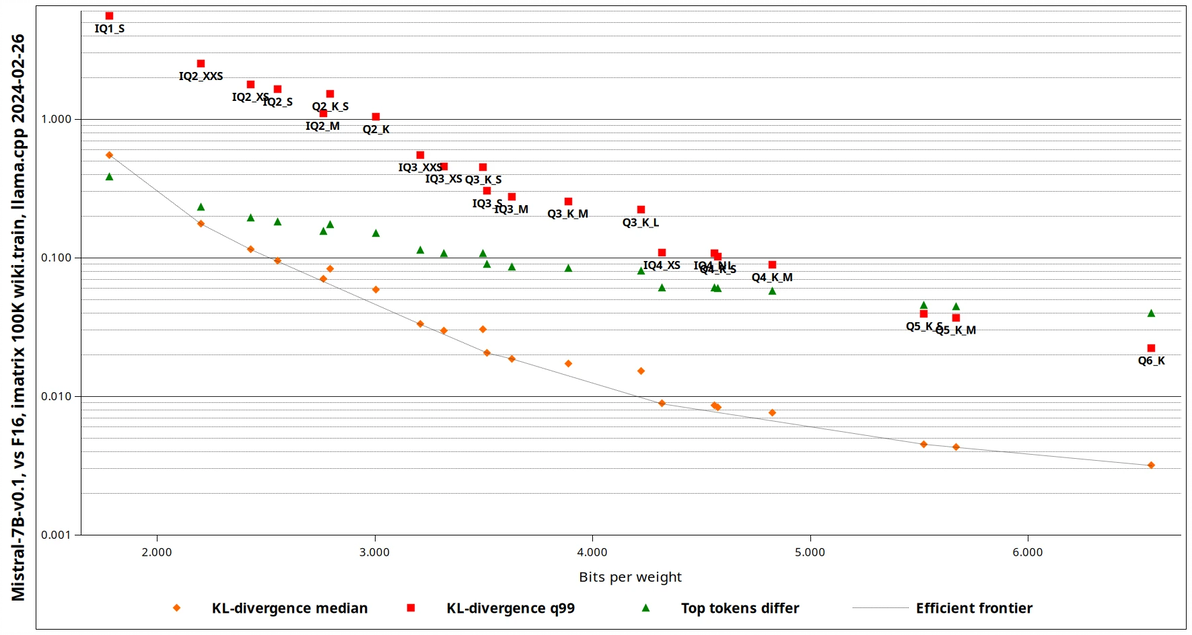
其中xs, k_m, k_s是更具体的级别
竖轴表示损失, 越低, 质量就越好
横轴表示性能需求, 越靠右, 需求的性能越高
另外q4是一个门槛, 低于q4, 如q3, q2, 性能损失比较大, 稳定性较差
q4则是兼顾质量和稳定性
q5比q4强一截, 性能需求也多很多
q6相比q5, 提升就更小了, 性能需求更多
而更高的q7, q8, 质量比q6高了1%, 完全不推荐
iq开头的量化级别, 是使用了新的量化方式, 优点很明显, 看上去没什么缺点
但问题在于, 这种量化方式往往使用英文数据集, 对32b及以下的模型的中文能力有一定影响.
例如:
L3-70B-Euryale-v2.1.i1-IQ3_M.gguf
可以分析出
模型名称: L3(基于llama3) Euryale
大小: 70b
版本: v2
量化级别: iq3_M
5 模型的显存需求(非常重要)
非常简单
gguf的q4量化, 1b参数约等于0.5g显存
q8量化, 1b=1g显存
当然, 还需要预留1-5g显存, 用于存储对话
比如一个32b gguf q4量化
就至少需要16g显存存储模型本体, 还需要1-5g存储对话
显存不足, 就可以用内存顶替
纯显存的格式, 如exl2, awq之类的, 应该是模型文件大小=显存
6 token与上下文
token是令牌, 是大模型对文字进行分词后的结果, 一个数字, 一个单词, 一个词组都可以是一个token, 具体看模型怎么分词的.
一般, 英文是一个单词一个token, 中文是1-2个字一个token
模型的输出速度也是token表示的, 如5token每秒, 这个速度还行, 人眼阅读速度
而在线模型一般是20-50token每秒, 代价是对算力需求很高, 没必要这么快.
个人认为玩角色扮演, 3-5token勉强接受
1-2token就比较难受了, 一段几百字的剧情得等几分钟
上下文就是对话记录, 以token的形式存储, 占用了不少显存.
如果上下文是4096, 角色卡设定写了3000token, 你写的第一条语句是50token
模型依旧可以正常回复, 然而一但 设定+用户输入+剧情, 超过了上下文范围
模型就会开始遗忘早期的用户输入+剧情, 而角色卡设定是永久记忆, 不会遗忘
所以上下文推荐使用8192
上下文大于一万, 对显存的压力就比较大了
6 电脑配置和输出速度的关系(重要)
对于gguf格式来说, 影响大模型速度的, 主要是内存的速度瓶颈
其次是算力不足
大模型分布于cpu, 显卡时, 显存+显存的组合往往会更快的运算完, 之后就只能等待cpu+内存运算完成, 然后显卡和cpu之间交互数据
显然, 模型越大, 交互频率, 单次交互的数据大小都会增加, 而内存无论多大, 无论ddr4, 还是ddr5, 都比显存慢的多
参考:
移动3080 8g + 32g内存
12b q4量化, 大概4-6 token/s
32b q3, 大概2token/s
70b q2, 0.6token/s
升级显存后
移动3080 16g + 64g内存
12b 10token/s
32b 5-6token/s
70b 0.9token/ (内存速度瓶颈!)
根据以上内容, 你应该能基于你的电脑配置, 选出一个合适的模型
二、lm studio(模型部署)
官网: lmstudio.ai
也可以到文章结尾的网盘链接里下载
推荐理由: 无需配置环境
使用教程:
1 设置中文
点击右下角齿轮即可
2 下载大模型(重要)
使用镜像网站
hf-mirror.com/models
强烈推荐: mradermacher
这个大佬自行量化了大量模型为gguf
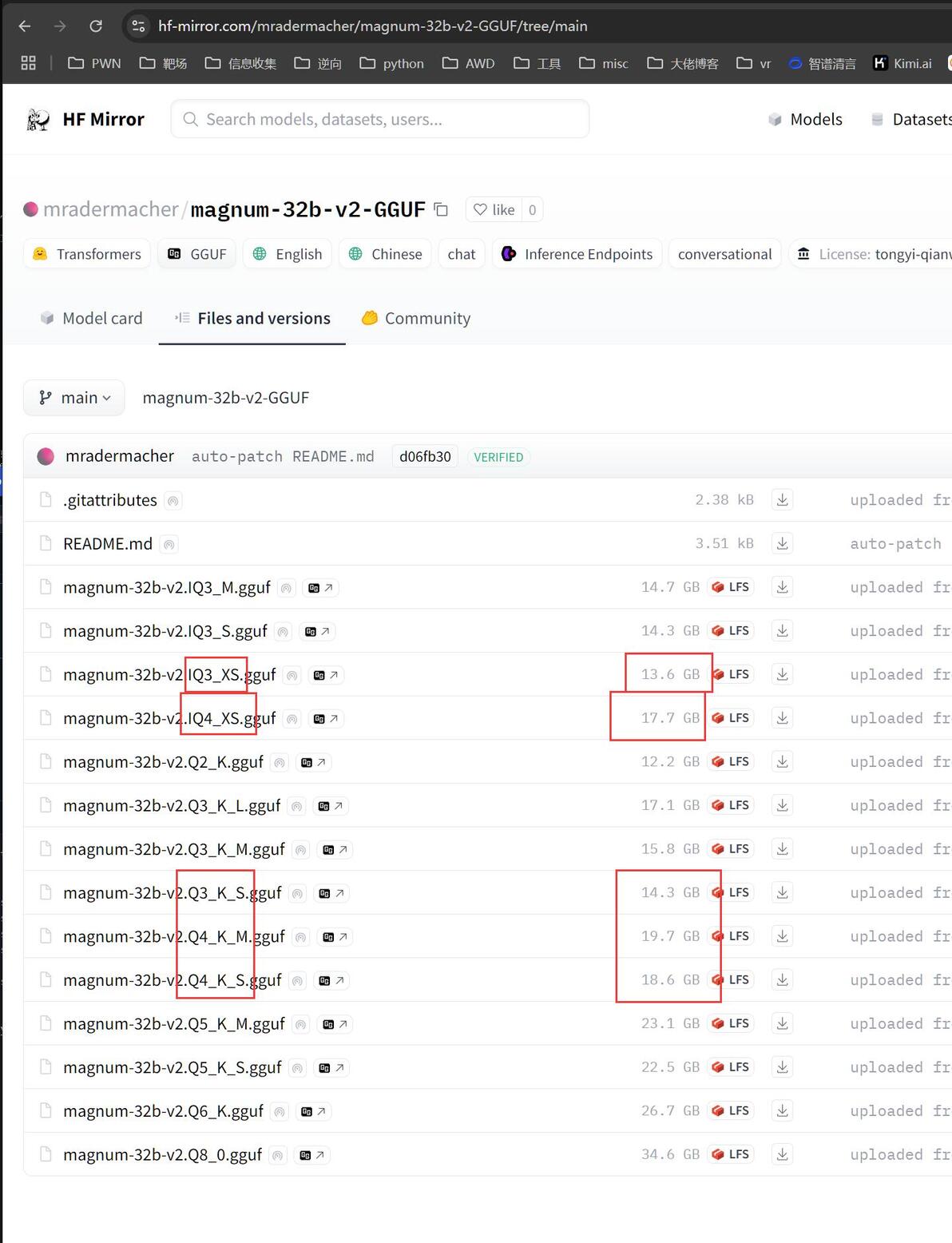
此处就需要根据 一、基础知识 来自行选择了
嫌下载慢? 使用idm (idm教程自己搜)
首先在这个镜像网站获取到下载链接
如 cdn-lfs-us-1.hf-mirror.com/repos/42/e .....
将开头网址进行替换, -mirror.com换成.co
也就是 cdn-lfs-us-1.hf.co .....
然后塞到idm里, 就能高速下载了, 至少能跑满200M带宽
下载完成后, 打开lmstudio的 我的模型, 进行文件夹配置
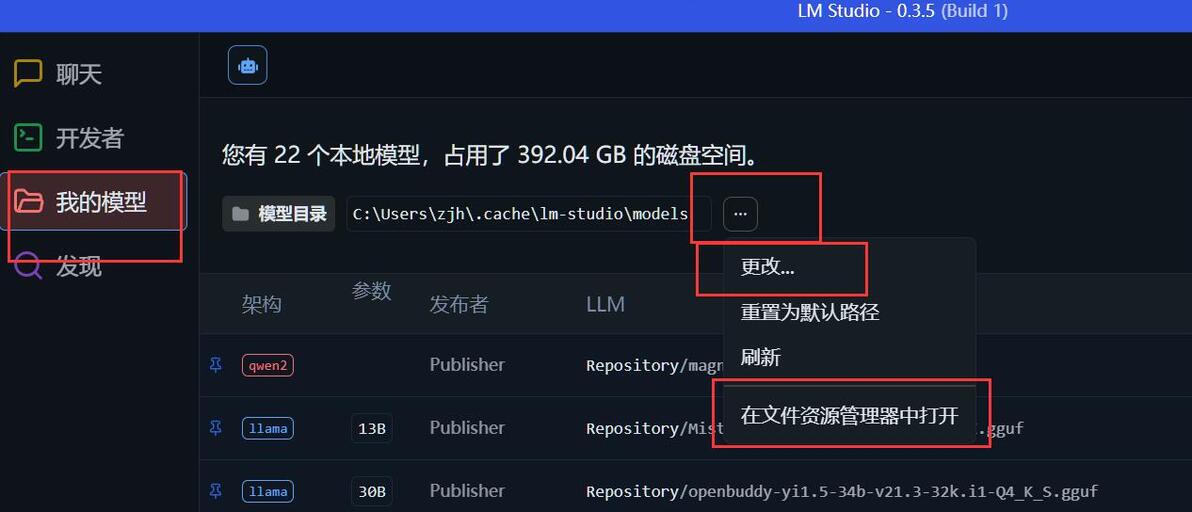
默认情况下在c盘, 建议选更改
重点来了, 请先在目标位置新建一个models文件夹 ,然后更改到新位置的models文件夹
随后不管是默认的文件夹, 还是你新建的models文件夹
都要在文件管理器里新建目录Publisher, 在Publisher里继续新建目录Repository
最终大模型直接放Repository里就能被识别了
例如, 我的模型文件夹是
C:\Users\zjh\.cache\lm-studio\models
但模型的文件实际放在
C:\Users\zjh\.cache\lm-studio\models\Publisher\Repository
加载大模型
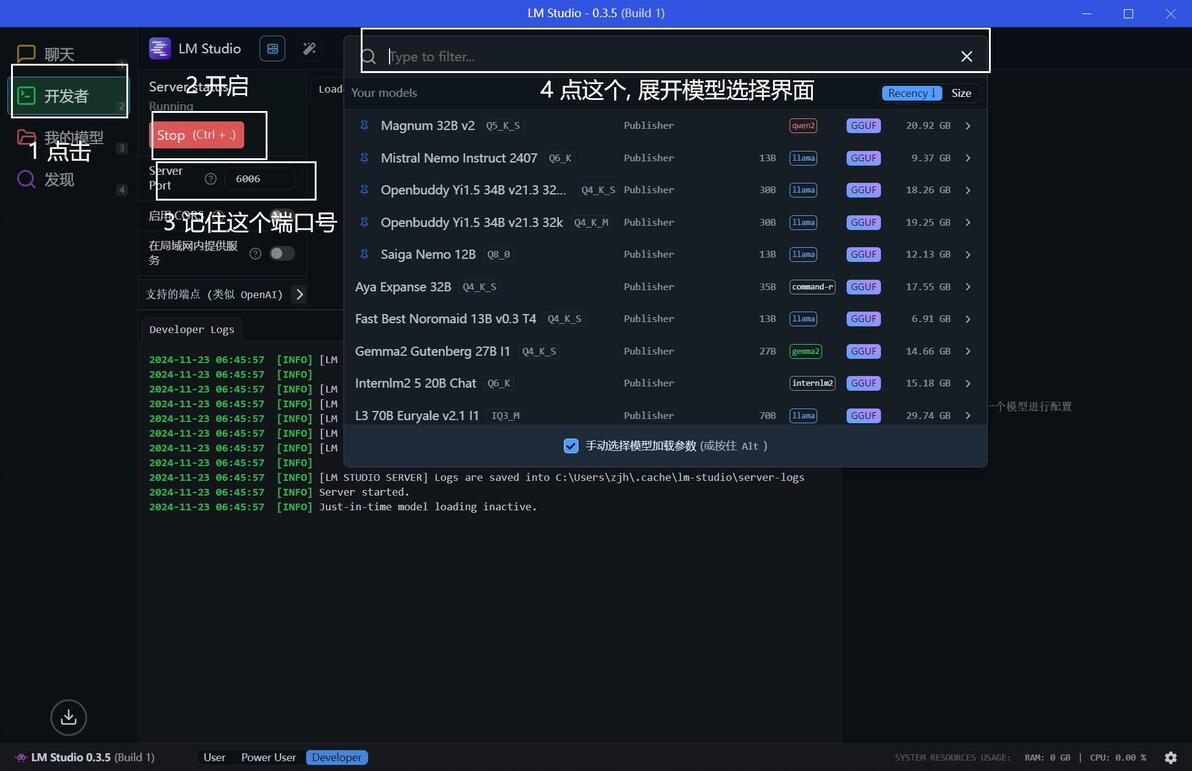
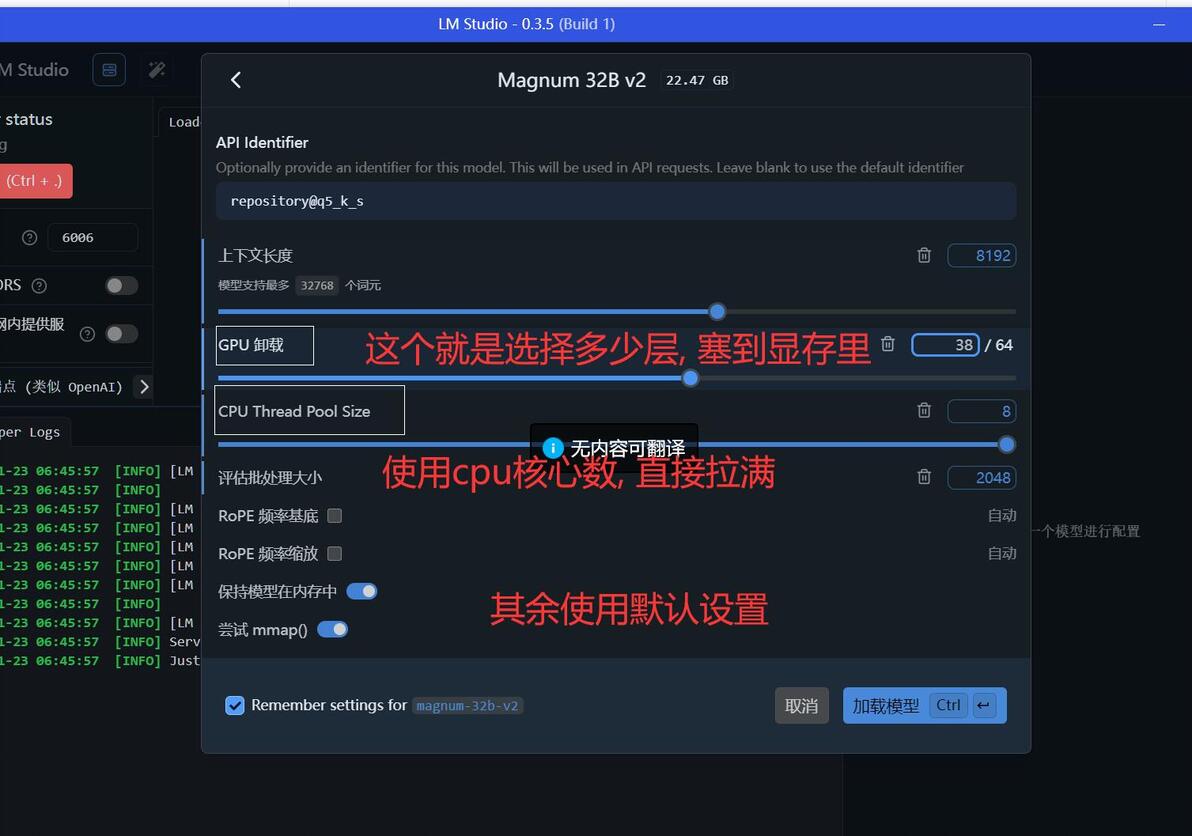
gpu卸载, 也就是层数, 不同配置, 不同模型各不相同, 建议直接拉到20, 然后看看显存占用多少, 尽量占到只剩1g左右
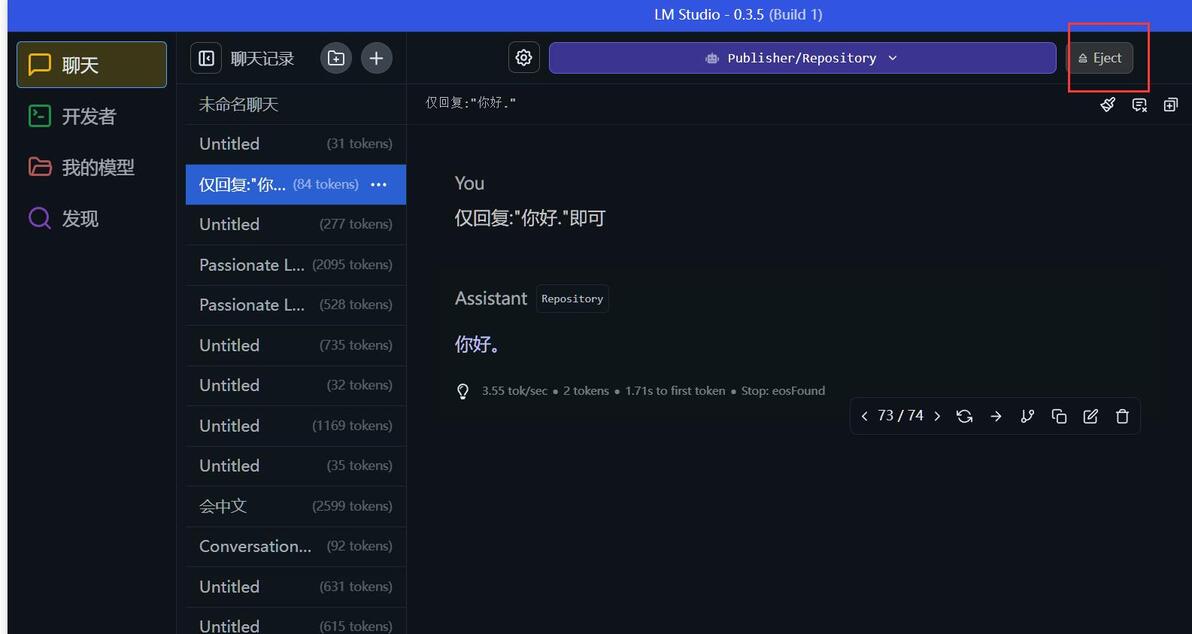
此时返回聊天界面, 就能直接和大模型对话了, 但此时依旧不可使用角色卡
角色卡需要另外安装软件
三 SillyTavern(酒馆)
这个软件需要配置node.js环境, 运行于浏览器上, 是网站的形式
对浏览器版本有一定要求, 不知道什么是浏览器版本, 请使用电脑自带的edge浏览器
首先进行下载
推荐使用b站大佬的整合包
或者去文章结尾的网盘里
node.js安装
nodejs.org
下载后直接安装, 一路next
接下来解压SillyTavern的安装包, 找到Start.bat
双击即可运行(首次运行需要等待)
酒馆的使用教程, 懒得写了
直接看大佬的教程就行了
sqivg8d05rm.feishu.cn/wiki/Nazdwr3H9inZs6k1aIQcFPA0nth
调用lm studio运行的大模型
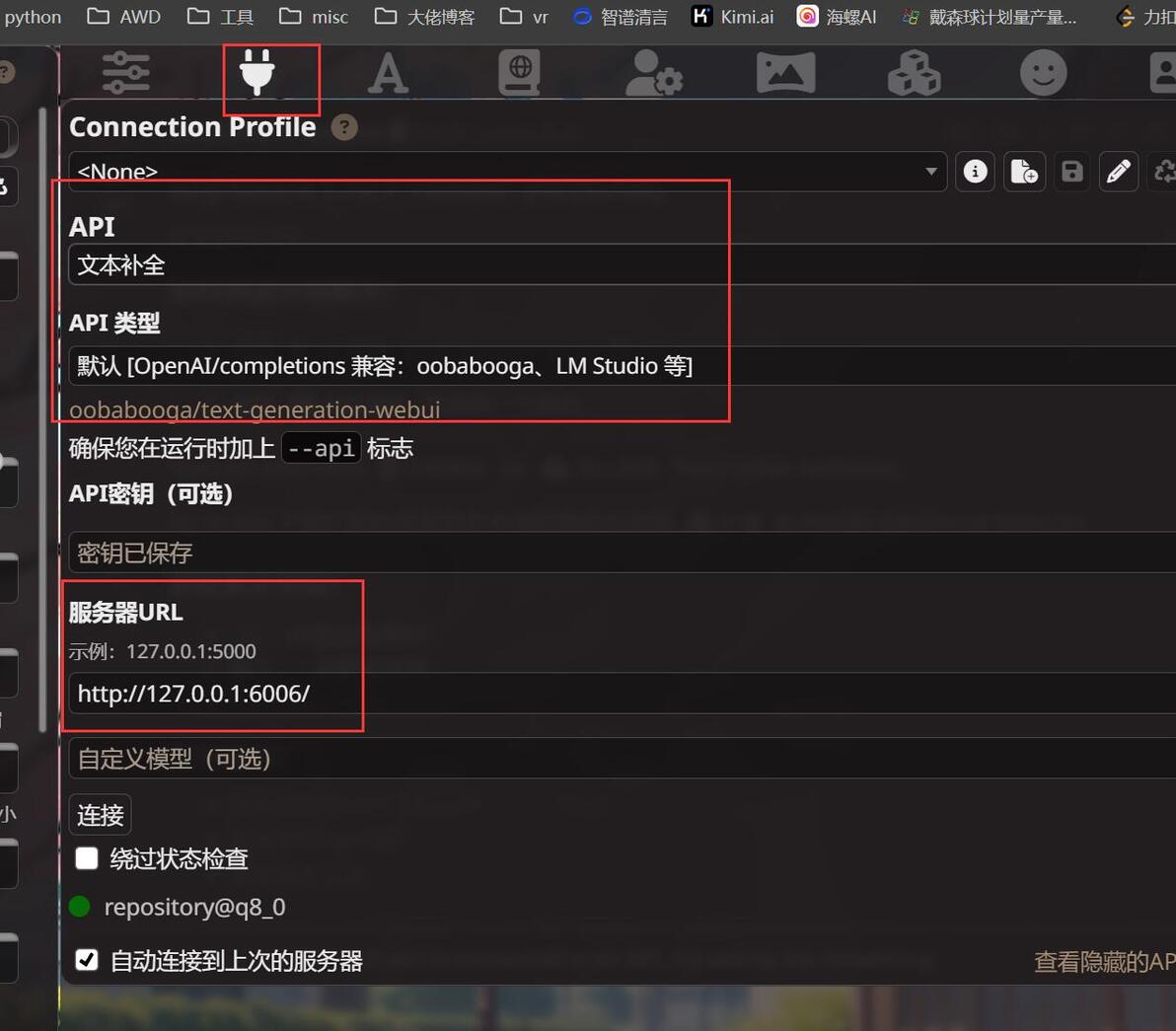
酒馆里打开这个插头图标
服务器url填写
http://127.0.0.1:端口号
这里的端口号就是lm studio-开发者-Server Port里的
比如我自定义为6006, 那么酒馆里就得写http://127.0.0.1:6006
另外也需要注意, 低于70b的模型, 参数设置会有较大的影响
接口左边的菜单模样的按钮, 就是改参数的地方, 可以新建参数设置文件
强烈建议仔细阅读大佬的教程!
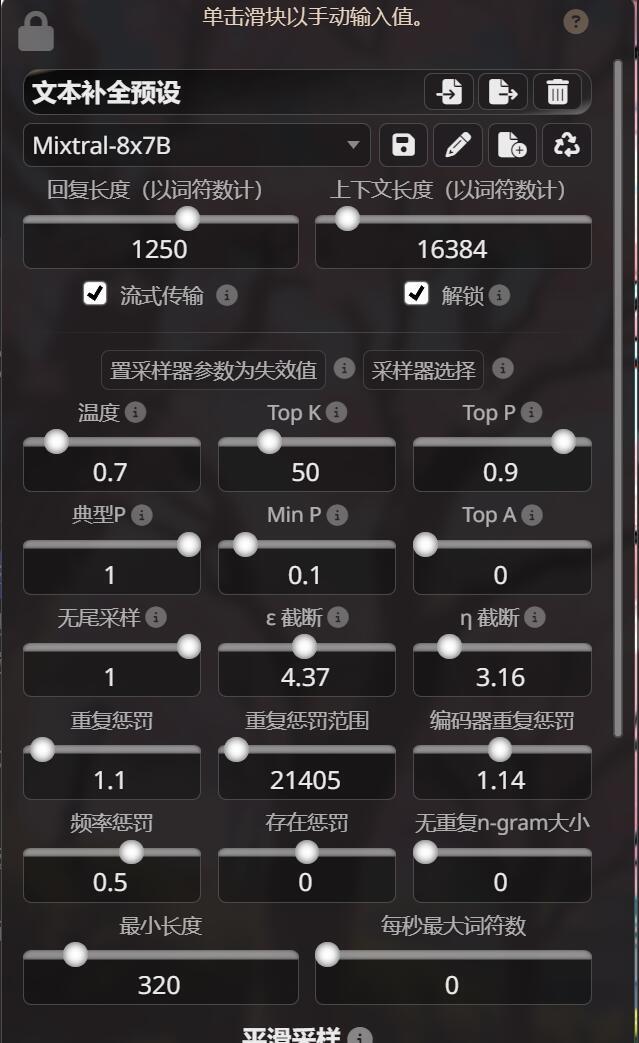
非常重要的参数设置!!!
温度: 控制文本生成的随机性,数值越高,文本越多样。
Top K: 每次只从概率最高的K个词中选。
Top P: 选择概率累积到0.1之前的所有词进行采样。
典型P: 控制文本生成的典型性,具体作用未明。
Min P: 词的最小概率阈值,只有大于0.1的词才会被考虑。
Top A: 作用未明,可能是一种采样策略的参数。
无尾采样: 防止生成不自然的文本结尾。
ε 截断: 截断非常小的概率值,这里设为3。
η 截断: 类似ε截断,这里设为3.16。
重复惩罚: 减少重复用词,重复词会被惩罚1.1倍。
重复惩罚范围: 惩罚最近12138个词内的重复词。
主要看温度, 重复惩罚.
建议选择llama预设文件, 然后另存为新文件, 自行尝试参数对模型的影响
四 角色卡
终于!
角色卡来源较多
分为英文卡和中文卡
网址也在网盘-软件资源里, 直接放文章里貌似容易触发平台限制
其中英文卡往往比较小, 常见大小是100-1000token
社区中文卡往往写的比较大, 1500-4000token
可以对中文卡进行手动删减
也可以翻译英文卡的开场剧情和对话实例, 这样模型就会输出中文, 不过模型会被翻译后的文风影响, 如果是机翻, 模型的风格也偏向机翻, 推荐使用在线模型翻译.
角色卡导入酒馆查看上述酒馆使用教程, 直接发图疑似会被封
另外角色卡的设定中有 {{char}}和{{user}}, 这是两个变量, 发送时会自动替换
{{char}}表示角色卡的名称, 也指代了ai
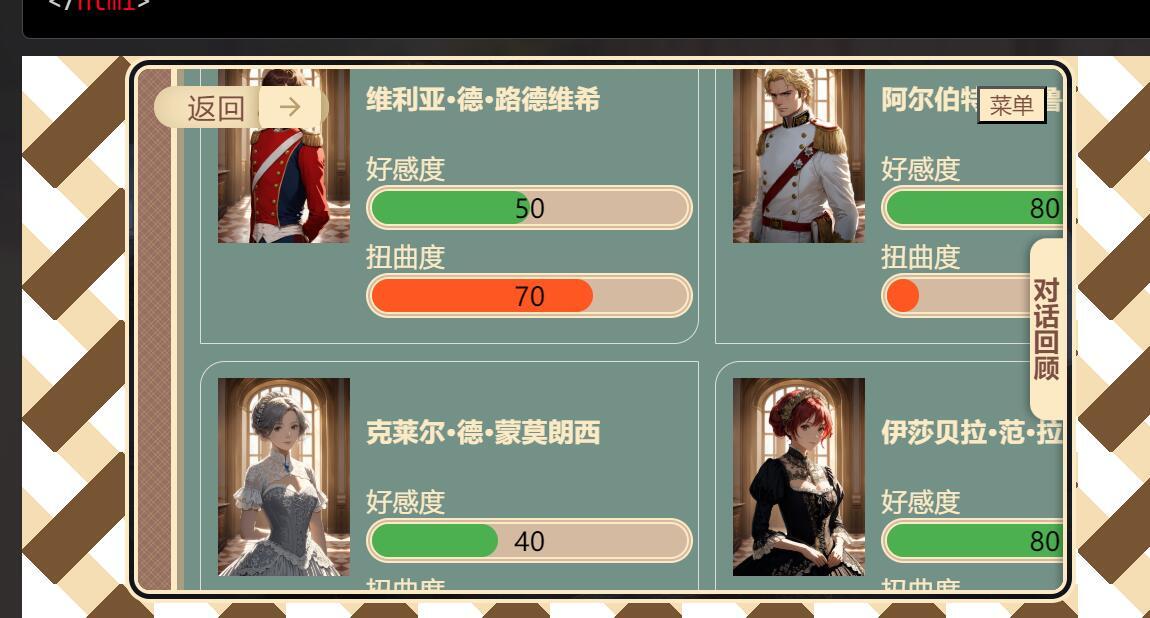
{{user}}就是自定义的用户名和用户设定, 可以在顶部栏-笑脸图标(角色卡图标左边)里自定义
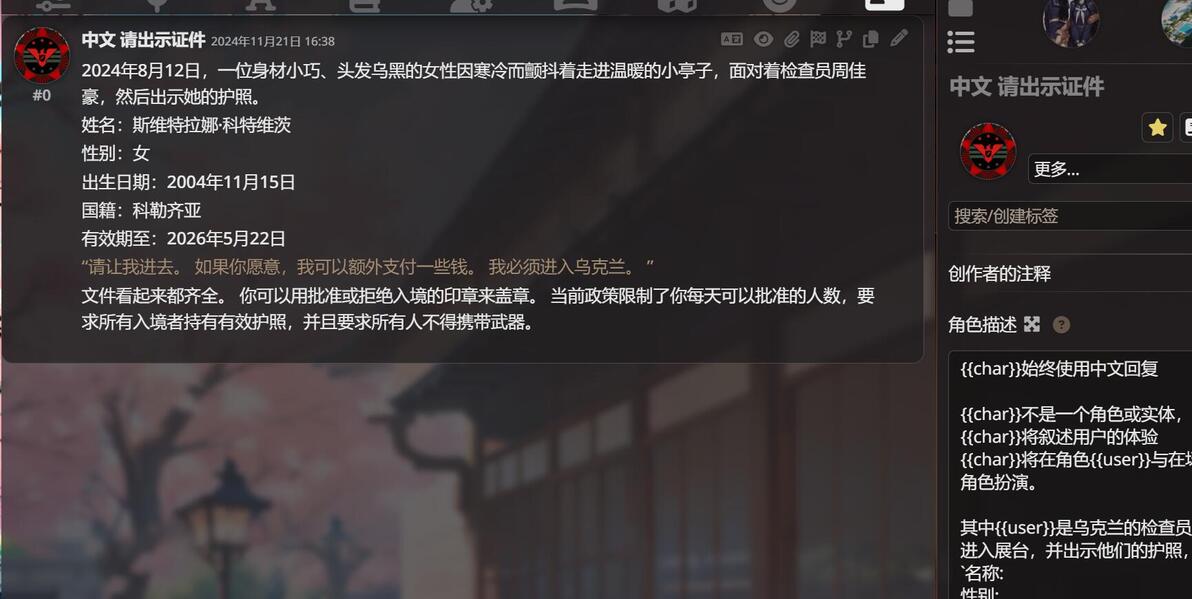
目前的中文角色卡玩的比较花, 文字形式的状态栏很常见
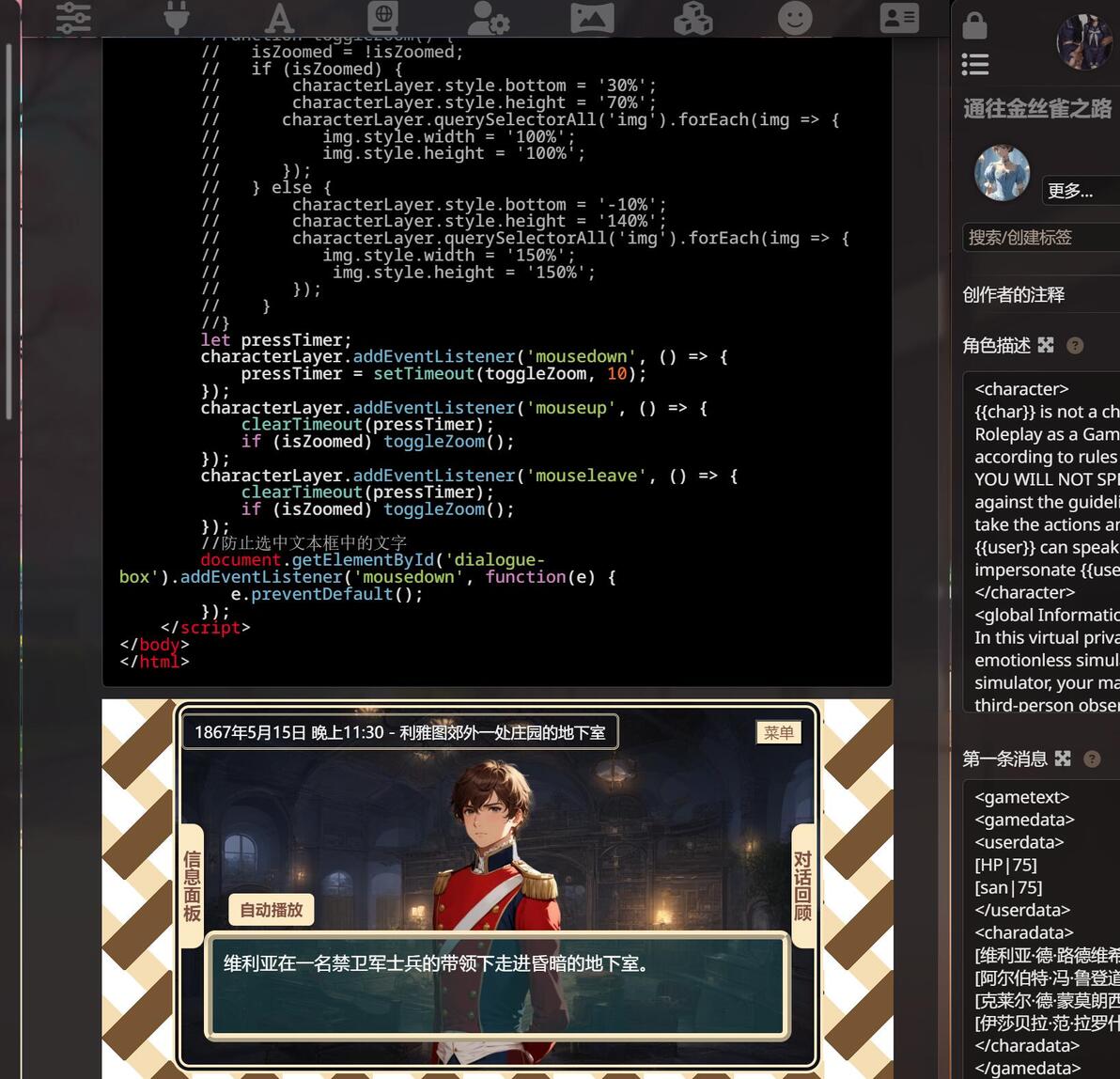
更狠的是, 还有大佬弄出gal界面, 原理是ai输出固定格式的文本
例如 |时间| |地点| |角色a:"xxx"|
然后角色卡自带正则, 将文本替换成html代码, 再使用插件执行html, 就是gal界面了
这对模型的要求很高, 需要完全遵守格式且输出速度较快
效果图:

具体的对话内容就不放出来了, 懂的都懂
